Okay, so this might be an odd case because I didn’t run prune for about a year. When I finally started running it, it would run for a while, eventually giving an error:
“Failed to locate the path for the chunk […] net/http: TLS handshake timeout”
I downloaded the latest version, ran a backup, then a prune.
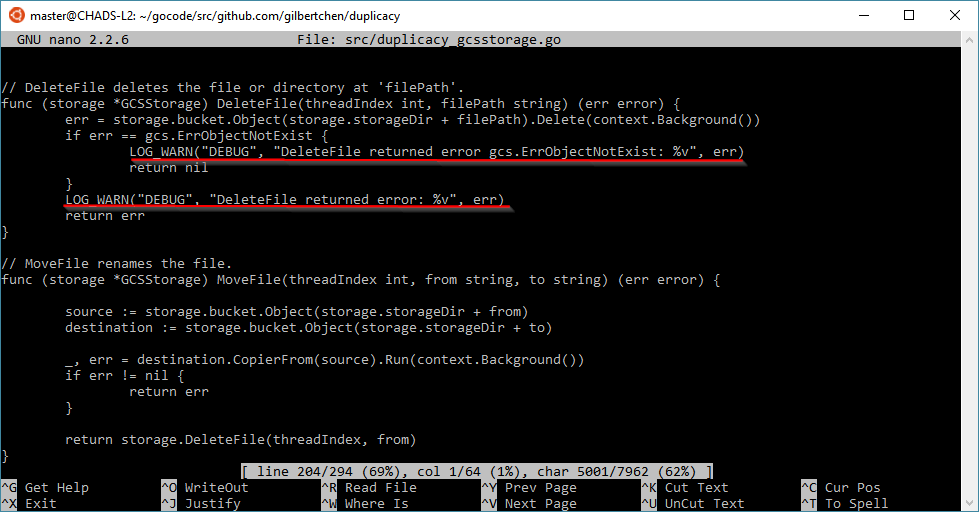
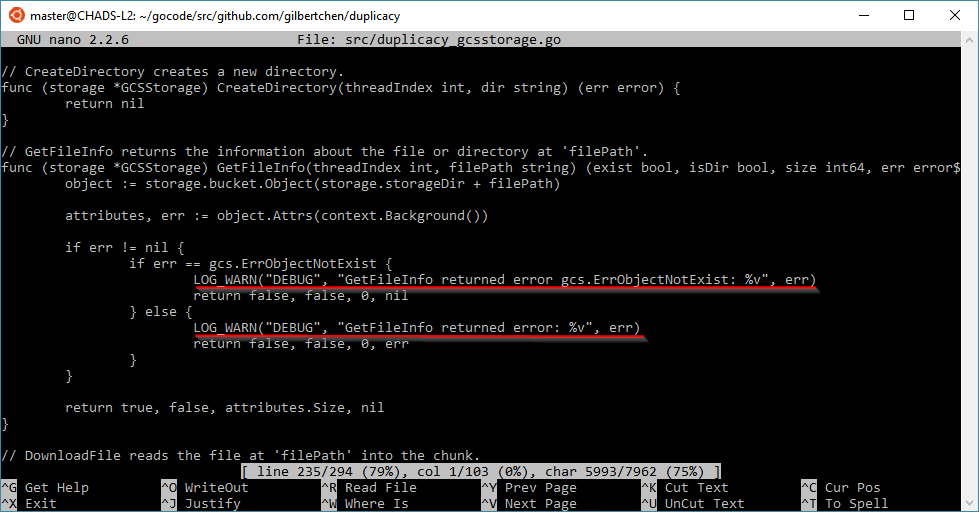
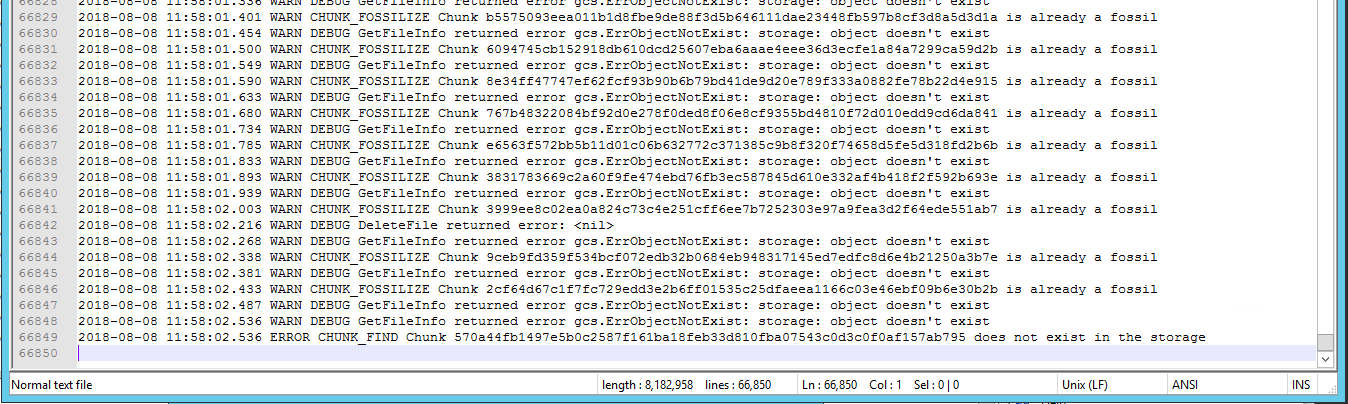
The latest version 2.1.1 seems to have a less verbose prune, but it decided to resurrect some of the chunks and got as far as snapshot 294 the first time on the new version

I then ran another backup, and another prune and got as far as 295 with no other output than “Deleting snapshot [snapshot] at revision 295”

EDIT:
Correction, there may be a pattern here. The second prune actually didn’t end until after it once again said that “Chunk [blah] does not exist in the storage” so maybe it is erroring out at that point.

A check command reports that there are a lot of chunks that do not exist at revision 1 for this storage.
Additional information: the backup is roughly 6.4 TB to GCP cold storage

Please advise