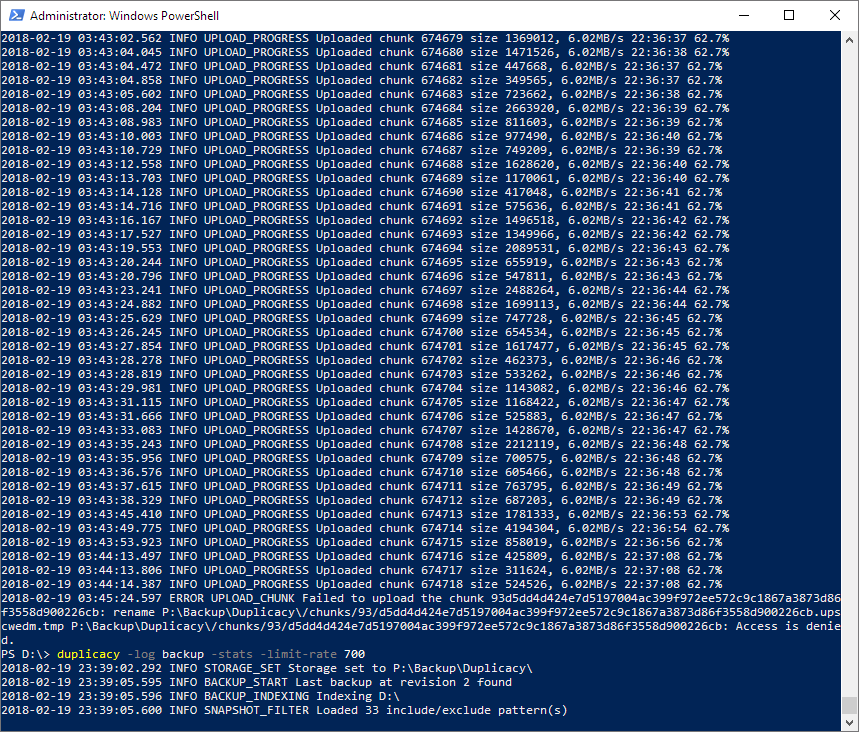
So you’re saying that those Skipped chunk 1 size 8427437… messages are only produced when duplicacy has the incomplete file to check which files to skip? In other words: when duplicacy attempts to upload a file that turns out to already exist (and hence skips it) then this is not reported as Skipped chunk…? Fine.
No, it is the opposite: if there is an incomplete file Duplicacy will know which files to skip so it won’t produce many Skipped chunk messages. If that file is absent, it doesn’t know which files had been uploaded in the previous backup (nor does it know there was a previous backup), so it will start from the first file and attempt to upload every chunk. But a lot of chunks had indeed been uploaded and that was why you saw so many Skipped chunk messages.