Right. You need to save both. Without either of them you can’t access data.
I’ts a limit on a number of concurrent connections your router can handle. It does not matter whether it is one application doing it vs another.
It could be multiple factors.
gateway may be a bottleneck, and its just one location you sent all traffic to.
inherent storj peer-to-peer parallel nature and optimizations they made to avoid slow nodes affecting performance. I.e. one of its main selling features Quoting from their article:
When you upload or download from the network, file segments are sent one after another. However, the pieces that make the segments are sent in parallel. Much effort has gone into optimizing this process, for instance when you download a file we attempt to grab 39 pieces when only 29 are required eliminating slow nodes (Long Tail Elimination). This is our base parallelism and allows up to 10 nodes to respond slowly without affecting your download speeds.
When uploading we start with sending 110 erasure-coded pieces per segment in parallel out to the world but stop at 80. This has the same effect as above in eliminating slow nodes (Long Tail Elimination).
On a separate topic, I’ve tried telling duplicacy to create chunks of size 64 and the resulting file size is indeed honest 64MiB=67108864 bytes. So, duplicacy does not overshoot, which is nice. Using chunk size of 64 shall make the best use of the network.
I got curious, so I started tests for s3 and native of various thread counts for 64MiB chunks overnight. (it will take some time because of my measly upstream. Will report tomorrow.
script
#!/usr/local/bin/zsh
# OPTIONS:
# -file-size <size> the size of the local file to write to and read from (in MB, default to 256)
# -chunk-count <count> the number of chunks to upload and download (default to 64)
# -chunk-size <size> the size of chunks to upload and download (in MB, default to 4)
# -upload-threads <n> the number of upload threads (default to 1)
# -download-threads <n> the number of download threads (default to 1)
# -storage <storage name> run the download/upload test agaist the specified storage
function bench()
{
(
echo "$(date): storage: $1, chunk-size=$2, threads=$3"
./duplicacy_main benchmark \
-storage $1 \
-chunk-size $2 \
-upload-threads=$3 -download-threads=$3 \
| egrep "(Upload|Download)"
) | tee -a benchmark.log
}
bench s3 64 1
bench s3 64 2
bench s3 64 4
bench s3 64 8
bench s3 64 16
bench s3 64 32
bench storj 64 1
bench storj 64 2
bench storj 64 4
bench storj 64 8
bench storj 64 16
bench storj 64 32
Run the same form a beefy Amazon EC2 instance. I expect to see same or better results than using gateway. Because the gateway is just an instance in the cloud in the same way. You can, in fact, run your own gateway.
And test file transfers with rclone. In case maybe there is something with the version of uplink duplicacy is built against
Yeah. Something fishy is going on. I strongly suspect my modem has to do something with it. I’ll confirm soon.
Another possibility is that a bunch of optimizations that storj did in uplink were made in the versions after the one duplicacy is built against. I’ll rebuild it with the updated version and retest.
So, the plan:
duplicacy bench on amazon cloud
rebuild duplicacy with newer uplink and try from home again
measure performance with rclone simply downloading the same files.
Shape: m4.2xlarge
Connection: High, whatever that means,
OS: Amazon Linux 2
Chunk size: 64MiB
Upload, MBps:
type\threads
1
2
4
8
16
32
s3
13.1
18.8
24.1
30.0
31.5
28.2
native
16.8
29.8
29.1
31.0
31.0
31.0
Download, MBps
type\threads
1
2
4
8
16
32
s3
11.3
22.1
48.3
79.2
72.0
77.7
native
11.2
21.4
39.6
70.0
70.0
71.0
Few observations I see:
m4.2xlarge instance seems to be bandwidth limited to somewhat 30MBps upload and 80-ish. I’m going to change the shape to an instance that provides explicitly 5 gigabit network and retry. Maybe also it was resource deprived. I’ll see if I can instance with guaranteed resource allocation.
Even one thread gets dramatically better up and downstream when not running though a consumer grade internet connection.
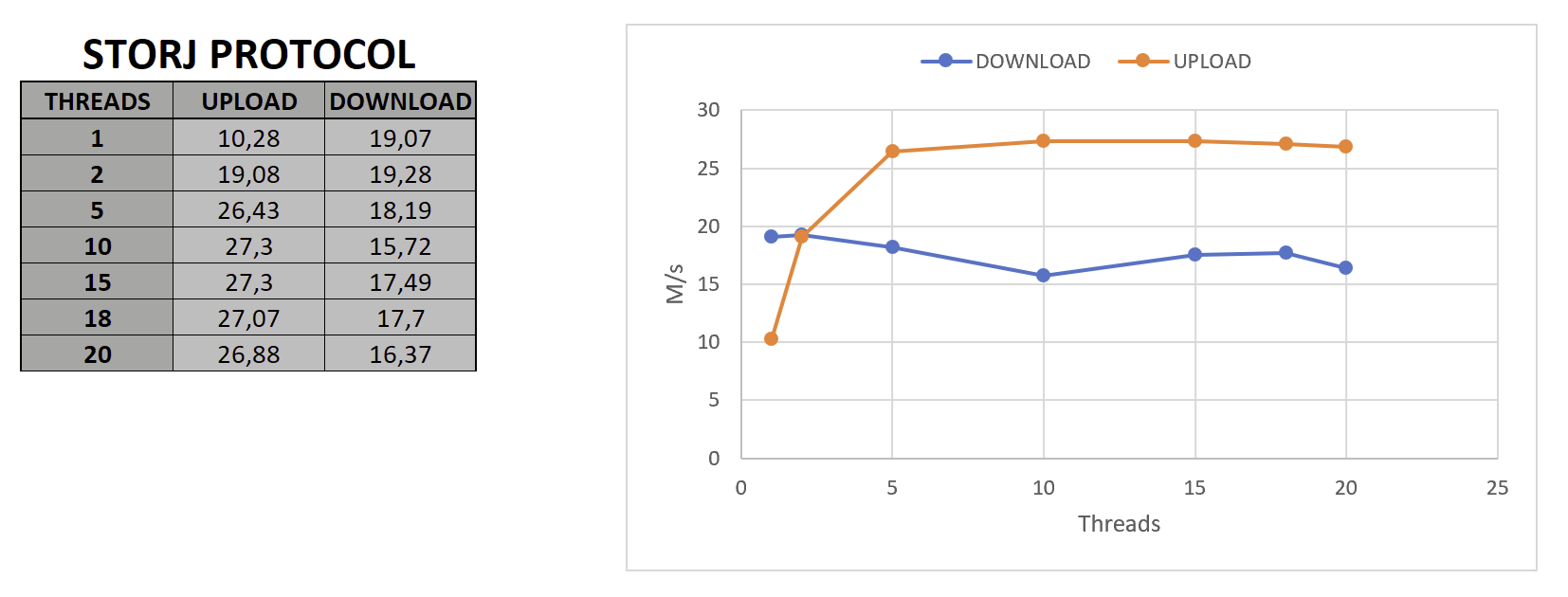
So I guess the takeaway is – s3 is good when resources are scarce (gateway will be doing all heavy lifting). Native is good when resources are not a concern and massive performance is desirable.
If I have understood properly these results were obtained using professional grade internet connection. Were STORJ protocol seems to scalate way more than S3. However, they would not be representative for a domestic setup.
Then would you recommend using S3 for a consumer grade installation? In my personal case, and noting that the benchmark I did was kind of limited, apparently I could use STORJ to outperform S3 when using more that 15 threads for download, and almost in every case for upload. However, maybe this could change if chunk size can be strictly set to 64Mb.
Anyway, I’m not sure of which impact would this have on PC/Router requirements and stress while running.
I’m not sure what professional grade is in this context, but it was a low latency connection indeed. It seems the performance, regardless of the endpoint, is strongly affecteby by latency, as expected.
I would recommend native integration on fiber connection, and S3 otherwise.
But you have a kind of interesting situation: you have a fiber connection, but traffic goes through a high latency VPN.
I don’t know your network environment, and reasons for using VPN, so cannot suggest how to configure your networking to bypass VPN for duplicacy traffic. Or probably better approach would be to only send traffic over VPN that actually needs to go to vpn network, as opposed to everything. That 100ms latency affects everything, not just backup.
Native backend will create an order of magnitude more connections, as described in that forum post on hotrodding storage . That should be fine for most decent routers, but some home routers may struggle.
I’m repeating the test setting chunk size to 64 Mb, and changing chunk count to 10 (just to avoid uploading and downloading 4Gb each time). Therefore using: duplicacy benchmark -chunk-size 64 -chunk-count 10 -upload-threads x -upload-threads x
I changed the VPN type to from a multi-hop to a normal one. This way pinging STORJ server reports an average ping of 32ms (the same as without VPN).
Perhaps vpn endpoint performance limited? With multi hop perhaps you accidentally got better routing. Can you try without VPN?
Also, 30ms is way too much for fiber network. Depending on where you live. I’m on the US west coast, and ping to storj is 15ms, which is minimum ping I can get anywhere, including to my own ISP, so it’s entirely due to cable modem.
Im wondering if maybe something else in your network interfering with peer to peer transfers? Maybe some overzealous firewall or anti-DDOS protection (like one on Synology, that would be triggered by pinging it form two machines simultaneously)
I tried without VPN, the results were slightly better, but nothing that makes me think of the VPN itself being a problem. Using the same config and 15 threads I got 30,25 upload (vs 27,3) and 21,27 download. (vs 17,49)
It’s curious, when pinging STORJ with VPN I get 31 ms average, and without VPN I get 35 ms.
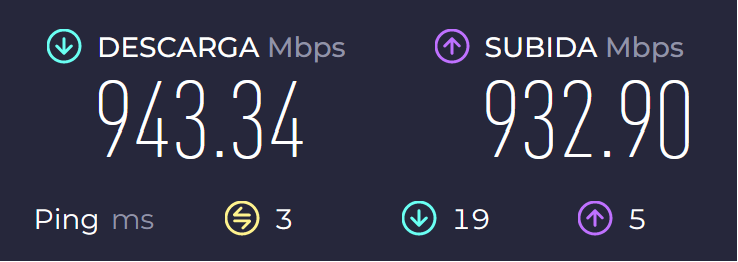
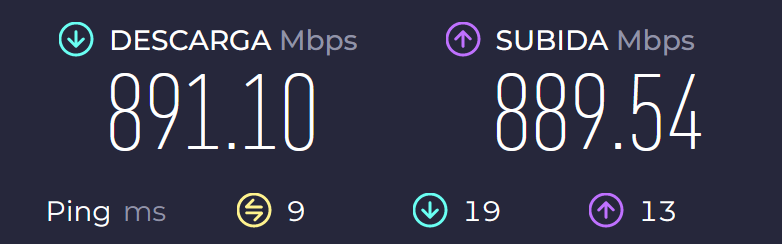
I decided to run the typical speed test and got these results:
Latency seems to increase a bit, but nothing too significant.
I’ve got nothing strange regarding firewall, I’m using a modified windows without a lot of its bloatware (windows spectre), so it should interfere even less than regular windows. The router is a ZTE H298Q provided by the ISP, alongside with a Huawei ONT. The only thing I could think off would be Bitdefender, but It is the free version and to my knowledge it should not interfere in anything network related.
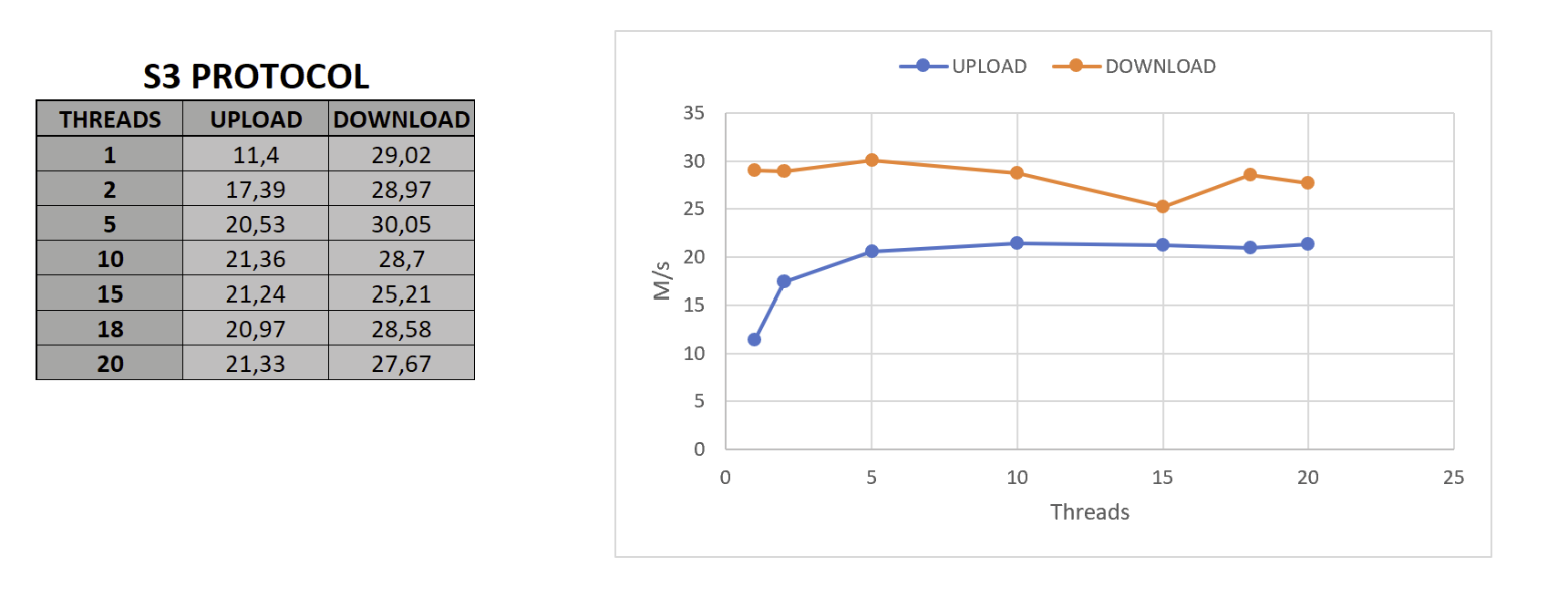
As said, I repeated the benchmark using S3, same conditions as before. Only that I forgot to encrypt the storage, which should not impact upload/download speeds.
Results are similar to using STORJ, however, S3 seems to perform better when download, meanwhile SOTRJ shows a better performance uploading. Neither of them seems to obtain a significant benefit from increasing threads further than 5.
so, your latency to the speed test server seems under 10ms, but to gateway.storageshare.io – 30ms. The former is fine, the latter is not too bad either.
To confirm – you are using EU1 satellite, right? What’s the ping to eu1.storj.io?
I chose eu1 when setting up the STORJ access in duplicacy, however I though it did ignore that parameter.
Pinging eu1.storj.io with VPN reports an average of 24 ms, 26 ms without VPN. Again without VPN I get a tiny increase in latency, probably within error margin of the measurement.
Could I be that it’s CPU limited? Check CPU usage of the process during upload and download. Does it saturate any one core? Otherwise I’m out of ideas.
On task manager CPU usage does not surpass 10% at any point when using 20 threads. It is a 13700k and temperature does not show a relevant spike neither.
I’m pretty lost to be honest.
10% of total? Or max 10% of each core? Because if there is some single core bottleneck, you may see utilization equal to the max of the single core while other cores are idle. It does not even need to be the same single core — the workload can be moved around. If one core is pegged and others are idle, with 16 cores you will see 7% utilization and yet the process could be CPU limited.
Your CPU has 8 high performance cores and 8 power efficient ones. I’m wondering what will happen if you pin duplicacy to a high performance cores only (you could “set affinity” on a process in the task manager if I remember correctly).
I have windows 11 at home, I can try running it there and comparing, in case it’s somehow windows specific.
Next step would be:
run duplicacy benchmark so it uploads the 64MB chunks and then interrupt it, so it does not delete them
configure rclone with the same credentials as duplicacy (native)
do rclone copy from storj to the local folder and record performance.
This will rule out some inefficiency in duplicacy in windows and/or give another data point with different tool. It’s also possible duplicacy is linked against old uplink library and maybe there are some perormance optimizations done by storj.
Next, instead of 10 64MB files, create one file of 640MB and see what performance you get with it. If our understanding is correct, there should be no difference (file will be shredded to 64MB segments internally). But if there will be — that would be extremely noteworthy.
in parallel I would start a thread on storj forum (or support) for the explanation of low rclone peformance. They are pretty responsive. The reason for rclone— that’s the tool then are officially recommending so they are not going to have an excuse that “Duplicacy is doing something wrong”. In fact, rclone was slower than Duplicacy in downloading those chunks in my testing so it’s even better
But that’s up to you how much time you want to invest in figuring this out. I would go all the way in, I love puzzles like these.
I repeated it again monitoring with MSI afterburner, of the 24 threads (it monitors CPU usage of each thread) not a single one spiked over 70% at any moment, most of them were under that and some were just idling.
Since I was not sure of which were you trying. I assume you were trying to create just one chunk of 640 Mb, which I was not able:
Invalid average chunk size: 671088640 is not a power of 2
The only one that I managed to work duplicacy benchmark -file-size 640 -chunk-count 1 -upload-threads 20 -upload-threads 20
Which reported:
Generating 640.00M byte random data in memory
Writing random data to local disk
Wrote 640.00M bytes in 2.62s: 244.15M/s
Reading the random data from local disk
Read 640.00M bytes in 0.07s: 8602.24M/s
Split 640.00M bytes into 142 chunks without compression/encryption in 1.83s: 350.13M/s
Split 640.00M bytes into 142 chunks with compression but without encryption in 2.31s: 277.29M/s
Split 640.00M bytes into 142 chunks with compression and encryption in 2.35s: 272.71M/s
Generating 1 chunks
Uploaded 4.00M bytes in 1.70s: 2.35M/s
Downloaded 4.00M bytes in 0.64s: 6.29M/s
Deleted 1 temporary files from the storage
Since it is creating a lot of small chunks, far from 64Mb, low performance was expected.
About this part It would take some time, since I’ve never used rclone.
I rather invest time before starting to regularly use duplicacy and do it right. In fact, it is being quite didactic and I’m learning a lot. However, next week I’ll start a business trip that will have me out of home for almost a month, leaving this on standby. I hope we can figure it out before that
Edit:
I was thinking, in the first test even with the strict VPN, it was performing way better at least download wise.
I don’t think I’ve changed anything besides the VPN, so this confuses me even further.
A sorry, I meant transferring large file with rclone.
Rclone is pretty simple.
You run rclone config and it walks you through creation of the remote. You can name is e.g. “storj”. It will ask for credentials, key and encryption passphrase. Use the same ones you’ve used for duplicacy.
Then you do rclone copy -P --transfers N storj:path localpath
Btw you can still start the backup, and then adjust parameters if we find the culprit. Files will get transferred either way. Or are you waiting for see in case it’s impossible to make to work fast enough?

 Quoting from their article:
Quoting from their article: