Understood. This is not unreasonable, there will be some users that are happy with the service (I was one of them myself, and was saying almost the same things almost verbatim). It’s probably also possible to find other corner cases and niches to get the best deals in every areas. They may change from time to time – for example, before google there was unlimited amazon drive. It was perfect in the same way – use as much as you want, it works, based on AWS, with a thin layer. It went away. People found hubic. which also went away. Now people found g-suite. While S3 kept working just the same.
I thought hunting bargains was worth my time. Now I think it ins’t. I guess this is the underlying reasoning.
It seems that way on the surface. But at the closer look – hot storage is suitable for fast access. That’s what it is good at. Backups don’t benefit from that performance at all. In fact, amazon themselves suggest Glacier for backups here:
**S3 Glacier Flexible Retrieval (Formerly S3 Glacier)***** - For long-term backups and archives with retrieval option from 1 minute to 12 hours
Yes. Backup is like insurance. One shall plan the risk-adjusted cost. The expectation is to never have to restore the whole thing, while restoring few things here and there occasionally. Archival tiers are most cost effective for these consequences.
I.e. you are not optimizing (cost of storage * years + cost of restore), you need to optimize cost of storage * years + risk of loss * cost of restore. And this makes restore cost pretty much irrelevant.
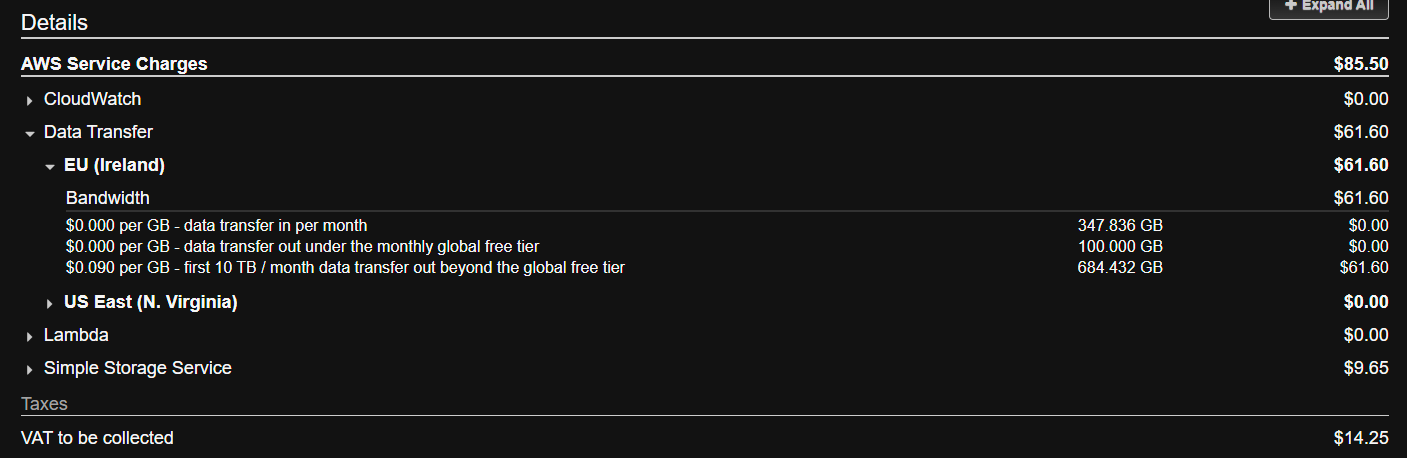
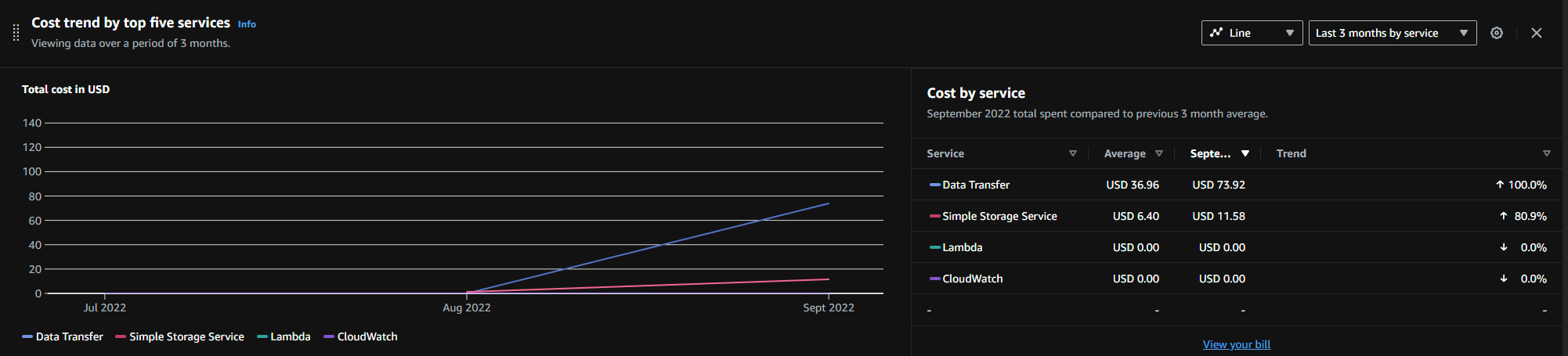
I calculated the cost. It can be very high, if you want everything at once, or very low, if you don’t.
Here is a back of the napkin old calculation Arq posted: AWS Glacier Pricing - How to Calculate the Real Cost | Arq Backup. Today it’s cheaper.
And here where I disagree with the approach: all data needs to be guaranteed immutable. Not just metadata. If I doubted my storage – I woudl not duplicate mediate, I would replace storage.


 With AWS you can restore for free/at very low cost certain amount of data monthly to cover this usescase
With AWS you can restore for free/at very low cost certain amount of data monthly to cover this usescase