That’s irrelevant, and missing the point entirely. We can discuss this too, but it’s a whole separate new topic.
Here in that comment, I’m talking about the value for money the service provides to its customer. Anything “free” there, and/or rolled into the “fixed” cost is a very poor value for a majority of users, by design; that’s the whole point of doing it. With itemized invoices, it’s much harder to screw the user over.
Profitability of a specific company is not a topc of this dicussion.
Duplicacy is not designed for a full system bare metal backup.
Generally, if you need full system backup, a hybrid approach is advised: infrequent bare metal backup, (say, monthly, or after major system updates or changes, or never) and frequent user data only backup (say, hourly). That way, system data does not compete with user data for spacce and bandwidth, and user changes don’t sit in the queue behind bulk system backups.
Barely costs anything at these scales! Charging for “API” is even more silly, though you can understand the reason AWS et al do it with their service - because big businesses do things on a much much larger scale, where ingress/egress and transactions do ramp up along with its storage size - needing to be time-critical, will actually have tangible cost at those levels.
This isn’t necessarily the case at smaller scale and with home users, and smaller providers. Quite frankly, it’s really up to the provider to juggle that, and for the consumer to stop conning themselves into a worse deal over some questionable principles. This mentality is the reason why certain countries don’t have internet connections with unlimited bandwidth as a defacto standard.
Anyway, the fact that Google Cloud Storage and Google Drive exist in the same Workspace product, proves this isn’t a downside.
I agree. Those “principles” are justification or explanation of what happens, not the ultimate goal in themselves. And yet, the experience suggests that the overall quality and value of the service received strongly correlates with the incentives’ alignment, as described above. So, as a shortcut, to avoid scrutinizing every service in every respect, (which is often impossible to do, and even if you did – it may change tomorrow) you can go by these rules of thumb. As a result, you will get with better deal.
For specific examples: people who think that they found a “deal” of getting 6TB for $5/month though Office365 discover after uploading a large chunk of data that performance sucks, API has bugs, and Microsoft would not do anything about it. Any savings evaporate this instant.
Disagree. With Workspace, you pretty much get storage for free: storage is not a product, it’s incidental to the SaaS they are offering, the collaboration and management platform. If you recall, they have never enforced storage quotas there (I don’t know if they still do). They are effectively “unlimited”. Would it be wise to use a Google Workspace account as a replacement for GCS or AWS S3? Hell no.
But… but. I was doing it myself!. Yes, I was dumb, and learned on my mistakes, so you don’t have to.
I agree entirely with the general notion. We’re all seeking the Holy Grail of backup solutions.
For the average user, it usually means it’s on by default and just happens without any effort (e.g., iOS and Android devices backing up to their respective cloud services).
For more sophisticated users, it’s most often a USB drive sitting on a desk or drawer. The level of complexity ranges from simple drag and drop to some software solution.
And then there’s you, me and the other folks on this and similar websites with more advanced requirements…
For us, the journey to backup nirvana begins with deciding on which path to take (offline, DAS, NAS, cloud, or some combination thereof?); the simplicity of drag-n-drop, disk imaging or software with a multitude of backup options; and sifting through all of the service providers to find out what best meets our needs (speed, cost, compatibility, reliability, etc.).
At the end of the day, it takes us a lot of work to make our backup solution(s) look straight forward, simple, reliable, and good all at the same time.
That particular minimum only applies to the default service plans. There’s a special “Borg” service plan (not limited to the Borg backup software) with a 100GB minimum ($18/yr).
While it’s true that storage is paid for up front, other than the relatively small annual minimum ($18 isn’t a whole lot of income for a service provider after factoring in 1%-6% for the card issuing bank + network fees + merchant bank fees), additional storage is billed in 1GB increments for $0.015/GB ($0.18/yr) and storage that’s added/removed is prorated for the remainder of the year so wasted space can be kept to a minimum.
For a user with 5GB to back up, there are definitely cheaper options than rsync.net if cost of storage is paramount. But it’s also why Dropbox currently has 700 million users but only 17 million paying customers (< 2.5%) and a $8.6 billion market cap while having over $3.2 billion in debt and other liabilities on its balance sheet. The former has been profitable while the latter is still a work-in-progress.
The main course plus sides might not be the best value meal ever, but it’s still among the lowest overall tabs out there (it’s almost dinner time ).
Also true, but the standard plan might be sufficient for many users, especially for those who follow a 3-2-1 backup protocol.
Given the storage requirements @rjcorless estimated, if rsync.net’s datacenter got hit by a nuke, as long as one of the devices being backed up is outside of the blast radius, there’s likely plenty of time to make another backup.
I honestly don’t think rsync.net is actively trying to unseat any of the big three. It’d be a futile exercise. But rsync.net doesn’t have to out compete in order to be a sustainable business.
There’s Google Photos and many other free alternatives, but yet SmugMug has a loyal paying customer base (only free option is a 14-day trial). I used to be a SmugMug customer and would again if the need arose because it was a good value.
Same goes for Fastmail which is competing with Gmail, Outlook/Hotmail and Yahoo. I have family and friends who’d balk at paying even $1/yr for email service but plenty of enough people pay for Fastmail to have sustained it since 1999.
For sure, rsync.net won’t be everything to everyone, but it’s certainly something to someone for it to have lasted more than two decades so far. It’s good to have a variety of options to choose from.
Sorry, I’ve seen no evidence here that this is the case. Unnecessary paying for egress and API calls doesn’t make something a ‘better deal’ and certainly no rule of thumb to actively look for.
Google Drive is perfectly fine as a backup destination. No download caps or costs, no API charges. Why would any sane home user choose GCS over GCD when it fits the bill and costs significantly less?
Well, just did a test on S3 with 10 20 30 and 40 threads. Looks like 30 is the max/optimum for my bandwidth as I could do a restore @ 15MB/s.
Can anyone tell me how to run the benchmark test because (i) going to either an unraid console or the Duplicacy console resulted in “Duplicacy not found” message and (ii) once I found “duplicacy_linux_x64_2.7.2” was the program to run, I got init errors and I could not work out what to do as I am using the Web Gui.
I am not CLI proficient and probably know enough to be really dangerous!! Ta.
One may come to that conclusion with naive approach of only optimizing “storage cost on paper”. But this not the only factor. If you consider the whole package – how much time and money is it cost to run duplicacy to GCD – the cost of GCS becomes negligible in comparison.
It goes back to using the right tool for the job. GCD is not designed for bulk storage. GCS on the other hand is specifically designed for that. So one should expect fewer issues with the latter and more with the former.
And indeed, have you noticed I stopped posting here with technical problems quite a while ago? And have you seen all the issues I reported with GCD? Blog posts I written? The amount of time I spent triaging them and building workarounds would have covered the cost of GCS tenfold for decades. And that is GCD, that is one of best ones, that is possible to made work. I gave up on OneDrive in an hour. An hour I will never get back, mind you. I value that my hour, let alone amount of time I spent triaging GCD issues much more than the aggregate cost of the storage on amazon for years.
Have you seen any issues anyone reported with S3 or GCS, that were not a configuration issues? I haven’t. I wonder why.
And lastly, a plot twist, invalidating the false premise of “GCD being cheap” even on paper itelf: google cloud drive is not cheaper than proper S3 archival tier storage over the lifetime of a backup. Duplicacy does not support archive tiers, and thereby forces users to overpay for hot storage. Backup in a hot storage is an oxymoron. The middle ground is S3 intelligent tiering, but this requires reading and analyzing long term costs. End result is be a massive time and money savings for home users who predominantly backup static media. This is something that Acrosync can do with duplicacy-web – to wrap archival storage into a end user product drastically saving money to the customers. But that’s whole other topic.
you need to run it in the folder where the storage is initialized. Ideally, run it on your desktop, to remove unraid from the picture entirely.
Otherwise, go to the backup or check logs in WebGUI and in the first few lines will be a path to a temp folder.
You need to cd to that folder and run duplicay benchmark (with the ful path) in there
I’m only running Duplicacy on the Unraid at the moment, not on my PC. Because I want a quick-as-possible restore process, I’m using a combo of EaseUS ToDo for the ‘bare metal’ backup, and I’ve also set it up to run a ‘smart’ backup which runs every 30 minutes across all my documents and stores locally on another (non OS) drive in my PC (this runs Incremental backups throughout the day than as midnight rolls over it creates a differential backup for the entire previous day and re-starts incrementals for the next day.) Then I use Syncbackpro to transfer to my Unraid NAS at the end of the day. I was just going to use Duplicacy to provide that cloud based back up from the Unraid server.
Synbackpro can save directly to the cloud as well, including S3 (which ToDo can’t).
As you may tell, my ‘backup’ strategy is a bit of a patchwork quilt precipitated by me building my first NAS with Unraid on an old re-purposed Sandybridge MB with an Intel 2500K and 16GB Ram. On oldy but a goody! It has a very stable Overclock of up to 4.5Ghz, great cooling and 8 SATA ports. Perhaps my strategy is more a reflection of ignorance more than it is necessity!
Eventually got the benchmark to run. Tried a few different # threads. This was 50 down and 8 up
Generating 256.00M byte random data in memory
Writing random data to local disk
Wrote 256.00M bytes in 0.22s: 1183.77M/s
Reading the random data from local disk
Read 256.00M bytes in 0.11s: 2389.16M/s
Split 256.00M bytes into 52 chunks without compression/encryption in 1.30s: 196.19M/s
Split 256.00M bytes into 52 chunks with compression but without encryption in 1.94s: 132.24M/s
Split 256.00M bytes into 52 chunks with compression and encryption in 2.13s: 120.03M/s
Generating 64 chunks
Uploaded 256.00M bytes in 74.31s: 3.44M/s
Downloaded 256.00M bytes in 15.87s: 16.13M/s
Deleted 64 temporary files from the storage
Says who? It functions perfectly fine as such! I’ve used it successfully with Duplicacy (and Rclone) for personal, company, and clients - for many years. I’ve not come across any users - some who store petabytes of stuff in there - who complain of scaling issues, data loss or corruption… other than the well-known, quite reasonable, rate limits - i.e. 750GB/day U/L, 10(!)TB/day D/L, 10 transactions/sec - fair, ample, and doesn’t cost a penny more for the privilege.
Now, if you want to claim it wasn’t designed that way; citation needed. Let’s see what Google says here:
Perhaps because the userbase is tiny and other, much less costly, solutions exist and are used instead?
Perhaps they reasoned the pricing structure for GCS et al isn’t exactly straightforward to predict against unknown de-duplication efficiency and data growth.
Perhaps they want to adopt good backup practice by regularly testing restores?
Even IF Duplicacy supported archival level storage, Workspace Enterprise has unlimited storage and is already better value than anything demanding more than a few TBs.
You’re screwed when you actually have to do a restore though.
My personal experience. It’s an extra layer between me and GCS that I don’t need. I had issues with it. I did not have issues with GCS.
And that’s what distinguishes google from others, like dropbox and onedrive. Still, does not change anything in my reasoning.
I don’t have access to statistics.
Good one With AWS you can restore for free/at very low cost certain amount of data monthly to cover this usescase
The problem with this is that “unlimited” won’t last forever. They will eventually fix the quotas issues and start enforcing them. When will this happen? No idea. But i’d rather not have to be left hanging, and I would like to pay for what I use, and I don’t want to participate in some shady averaging and “unlimited” claims. Actually, they never use the word unlimited. They use “as much as needed”. And when they decide to cut down on abusers like your clients – its anybody’s guess.
I choose not to play this game and just pay for what I use. It’s transparent, straightforward, and fair.
Home users rarely need to restore everything at once. Restoring slowly in small chunks is from free to very low cost.
The change in terminology isn’t surprising. “Unlimited” has always been a misnomer - implies infinite, which of course, is impossible. Obviously there’ll be a hidden, fair use, limit with anything - yet they’d have to work hard to justify encroachment on the “as much as you need” marketing. A dozen or so TB isn’t gonna fuss Google when they haven’t fussed previously over many 100TB+ and even peta users, and it’s not like Google is suddenly desperate to reclaim storage space. They also know they’re unlikely to make much revenue from these users by bringing it down significantly, so why risk a good selling point?
I, like everyone else, was migrated from G Suite to Workspace, for marginally more cost per month. Even the full wack Enterprise Plus would only cost me £23 from next April (after my 50% discount expires). That’s still quite a bargain for what I need it for.
Incidentally, neither I nor my clients are abusers - I use what I need, and our clients’ use comes under the 5TB you get with Business Plus for £13.80pm. Which still works out to be less than Glacier without restores. Need more? Add more users and pool data. Still cheaper, free restores.
The colder the storage, the more expensive that restore process is.
IMO, ‘archival’ tier storage should be for… archives. Not continuous backups.
Though I’m eager to see Duplicacy support separate metadata (primarily so I can duplicate that directory in my pools for added redundancy), I strongly suspect those intrepid arctic explorers be disappointed at the cost savings when all’s factored in.
Understood. This is not unreasonable, there will be some users that are happy with the service (I was one of them myself, and was saying almost the same things almost verbatim). It’s probably also possible to find other corner cases and niches to get the best deals in every areas. They may change from time to time – for example, before google there was unlimited amazon drive. It was perfect in the same way – use as much as you want, it works, based on AWS, with a thin layer. It went away. People found hubic. which also went away. Now people found g-suite. While S3 kept working just the same.
I thought hunting bargains was worth my time. Now I think it ins’t. I guess this is the underlying reasoning.
It seems that way on the surface. But at the closer look – hot storage is suitable for fast access. That’s what it is good at. Backups don’t benefit from that performance at all. In fact, amazon themselves suggest Glacier for backups here:
**S3 Glacier Flexible Retrieval (Formerly S3 Glacier)***** - For long-term backups and archives with retrieval option from 1 minute to 12 hours
Yes. Backup is like insurance. One shall plan the risk-adjusted cost. The expectation is to never have to restore the whole thing, while restoring few things here and there occasionally. Archival tiers are most cost effective for these consequences.
I.e. you are not optimizing (cost of storage * years + cost of restore), you need to optimize cost of storage * years + risk of loss * cost of restore. And this makes restore cost pretty much irrelevant.
And here where I disagree with the approach: all data needs to be guaranteed immutable. Not just metadata. If I doubted my storage – I woudl not duplicate mediate, I would replace storage.
ISTM these object storages are designed around the premise of using with cloud compute, and egress to internet is not the usual. I doubt such long wait times for objective retrieval would work too well with a backup tool like Duplicacy - even where metadata was hot. Supporting archival tier may involve quite a bit more work than isolating metadata. Maybe a copy to local might be most feasible.
And what to do meanwhile… Duplicacy doesn’t support it yet.
Nothing is guaranteed immutable - that’s the point. There really is nothing wrong with adding redundancy when it’s extremely minimal effort and cost (metadata amounts to very little). At the flick of a couple check boxes, I could have Stablebit DrivePool duplicate that directory on however many drives I want - a configuration similar to SnapRAID’s content files.
Given that Duplicacy backup storage is easy to ‘repair’ by copying missing chunks from offsite storage, duplicating metadata is just another layer of redundancy that expedites a DR scenario.
Final Update:
Couldn’t put up with the thought of a ~2MB/s restore speed off OneDrive (even if it was just once per year), so I’ve used my Amazon AWS account to use their S3 storage offering.
So far, weekly full backups and daily differentials on windows documents files are being uploaded automatically at the end of each day (even though there are many incrementals being saved to Unraid every 30 minutes that I can also use quickly if I need to.
Currently have a full weekly backup and daily incrementals on a two week rotation for a bare metal restore. Given the daily differentials and unraid incrementals during the day appears to work OK, and given I don’t update/install new updates or programs to my windows PC, I may review this further and just run a Full backup weekly and say keep a month’s worth which is probably about 350GB in total. May just leave it at two through. Not decided.yet.
Looks like this will cost me about $3 per month which is nothing really. But really happy with both upload and download speeds that I can achieve with AWS. Will just do me fine.
Thanks for the insight and discussion! Very interesting and something I have never bothered with before!
UPDATE:
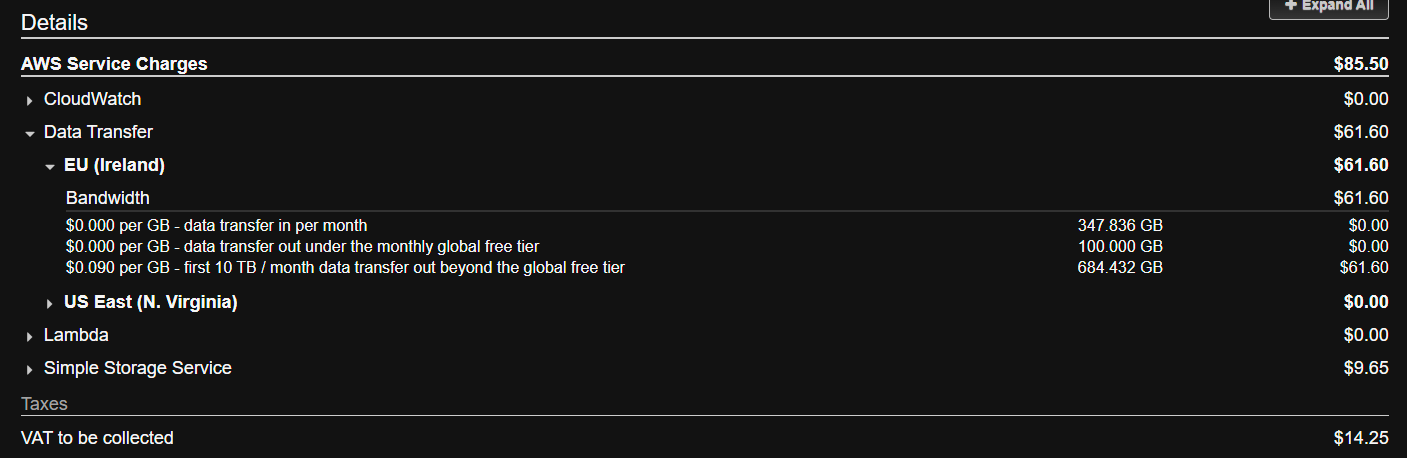
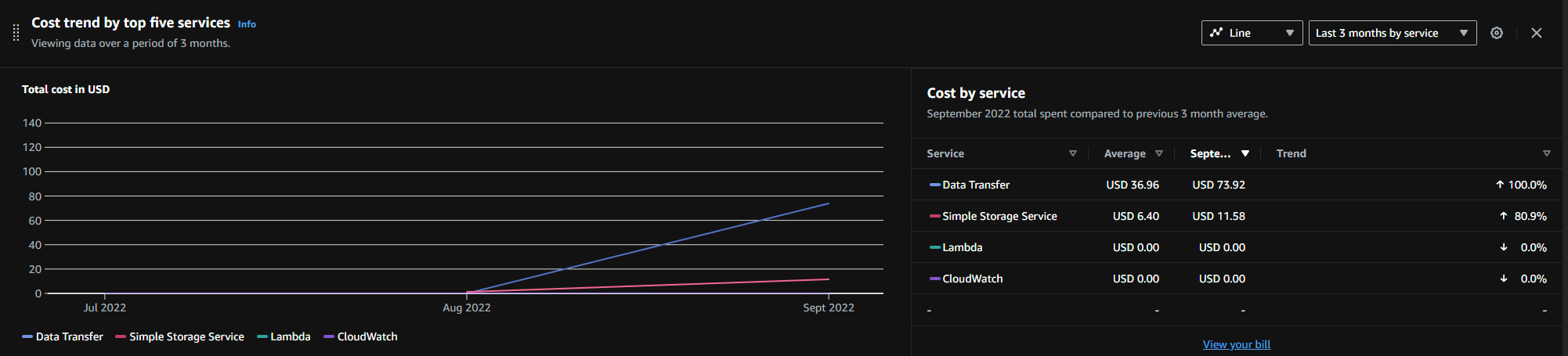
Well, in so much as the actual ‘storage’ cost for my 600GB rolling backup resulted in a nominal monthly charge of about £5, the charge for getting the data onto AWS within the month cost me another £79. What the heck? As I cannot see my strategy changing in backing up a ‘bare bones’ image, there is no way ai am going to pay £84 per month for uploading and storing just 600GB. I’m out!!
Not sure how did you get these numbers, check the bill
My upload of about 2TB to AWS cost me about $20 and then I pay $3 monthly for storage and incremental updates.
The idea being upload and download cost are irrelevant, you do it only once, but storage cost matters — you pay it forever.
Your numbers are however cray high. What tier have you used? Glacier flexible retrieval is what you want as there are no thawing involved, until Duplicacy supports archival storage properly.
Edit: since you are backing up an image you might have very high data turnover. This will be very expensive as low cost tiers penalize early deletion. Set chunking to fixed to combat it somewhat. But I would reconsider backing up images, even if you think it won’t work for you.


 ).
).

 With AWS you can restore for free/at very low cost certain amount of data monthly to cover this usescase
With AWS you can restore for free/at very low cost certain amount of data monthly to cover this usescase