
Hello,
I am currently working on an implementation of the paper “Duplicacy: A New Generation of Cloud Backup Tool Based on Lock-Free Deduplication” which describes the basic algorithm behind Duplicacy.
The paper is very interesting but I found two scenarios where the proposed algorithm can cause data loss to occur. To make sure that they are not caused by me misunderstanding the paper I want to present them to you and maybe find out how Duplicacy solves them.
Scenario 1: Race condition during fossil collection and deletion
The paper claims that some processes performing fossil collection while other processes are performing fossil deletion are lock-free. In the following scenario, the algorithm deletes a fossil that is referenced by a manifest file. This could lead to data loss as follows:
- Client 3 creates a manifest file called #1 referencing a chunk that is not referenced by any other manifest file.
- Client 2 decides to prune manifest #1 and performs a fossil collection step. This leaves the chunk as a fossil.
- Client 2 creates a manifest file called #2 referencing the same chunk.
This causes a new chunk to be uploaded. - All other clients create at unrelated manifest file, allowing Client 2 to proceed with the fossil deletion step.
- Client 1 decides to prune manifest #2 and performs a fossil collection step. This leaves the chunk as a fossil (replacing the existing one)
- Client 2 performs the fossil deletion step, which causes the fossil to be deleted since it is not referenced by any manifest file.
- Client 3 creates a manifest file called #3, which referenced the chunk, but the check for its existence happened during step 5 before it was renamed into a fossil. This prevents a new chunk to be uploaded, and leads to a missing fossil.
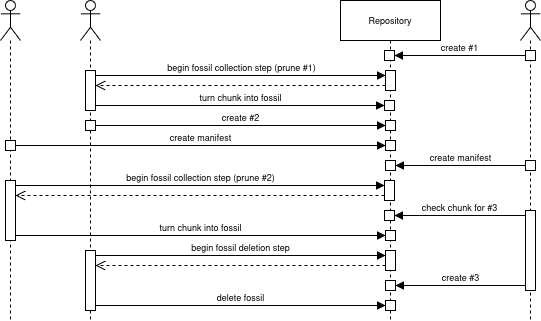
I think the reason for this behavior is that after step 5 two fossil collections exist containing the same fossil.
Since fossils from different fossil collections are not separated, a fossil can be deleted by any fossil deletion step processing a fossil collection containing it, even when Policy 3 would prevent another fossil collection from proceeding with the fossil deletion step.
This scenario can be prevented by limiting the fossil collection and deletion steps to a single client (and allowing only one fossil collection to exist at a time).
I’m wondering whether this problem has been discovered before – at least in the Duplicacy implementation, I see that the prune command should only be run by a single client.
Scenario 2: Manifest files being replaced
While the paper does not explicitly mention clients replacing manifest files, such scenario can happen in case the client does not take precautions against it. In the following scenario, this leads to a new manifest file that is not identified as such, causing a fossil to be deleted instead of being recovered:
- Client 1 creates a manifest file called #1.
- Client 1 performs a fossil collection step that does not prune #1 but turns a chunk into a fossil.
- Client 2 creates another manifest file called #1 that references the chunk turned into a fossil, but the check for its existence happened before it was turned into a fossil.
This causes no new chunk to be uploaded. - All clients create a unrelated manifest file to allow Client 1 to proceed with the fossil deletion step.
- Client 1 performs the fossil deletion step that ignores manifest #1 since it was seen by the fossil collection step and therefore deletes the referenced fossil
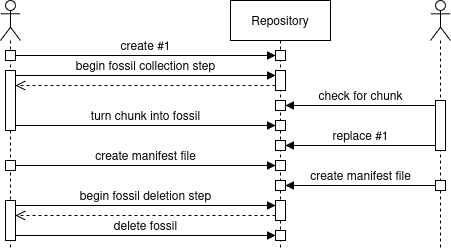
In the example above, I assumed that the “diff” function used by the fossil deletion algorithm works on manifest file names and can therefore not differentiate between different manifest files with the same name.
I hope the presented scenarios are understandable. Any feedback whether my observations are wrong or right would be very helpful.