
You’re right. I didn’t think to click on the icon. FWIW I was expecting a double click to expand the directory (and single-click to select), but you can probably file this under stupid end user error if it’s obvious to others.
Not sure which other port should be used.
Will fix these.
I think it just needs to be explained in the user guide with the official release.
Agreed.
Don’t know if there is a better place for the restore buttion.
Not sure about this.
Was there any error in ~/.duplicacy-web/logs/duplicacy_web.log? Or was there a new log file named backup-yyyymmdd-hhmmss.log under the same directory?
The bottom of the backup panel is reserved for that.
Can you reproduce this? Don’t know how this can happen.
I’ll fix that.
That is because backups are per computer. Later you should be able to add remote computers and create backups for each of them.
This can be easily fixed by some CSS changes.
Currently schedules do not have names. Maybe they should?
This can be very convenient, this I total agree, but I need to think about the details.
The size is the total bytes of chunks on the storage (including all revisions).
This can be easily fixed.
The names of the log files aren’t that important. I hope to make a better version of the Activities panel in the Dashboard page from where you can access all the logs.
Try reload the page before entering the password. You probably accessed the page from different machines at different times (or restart the binary after the page was generated).
As a suggestion - port 3875. It is not widely used and the number is a T9 for DUPL 
Objects that are more frequently used should be larger and easier to click, more affordable. backup and restore are a safe buttons to click, while deleting the backup task is not --and yet they are all very small crowding in the corner. but I’m not an expert in UI design, there perhaps are better approaches.
Ive tried to re-create the scenario after nuking rm -rf ~/.duplicacy-web/.
But now I cannot add SFTP storage anymore - when putting all data I get this error:
2018/11/05 22:26:35 ERROR STORAGE_CREATE Failed to load the SFTP storage at sftp://me@nas.home.saspus.com//Backups/duplicacy: ssh: handshake failed: open /Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy/known_hosts: no such file or directory
There is nothing under ~/.duplicacy-web/repositories/localhost/all
Perhaps it is a simplistic approach, but thinking about hierarchy:
- a job is made up of: command + parameters + options
- a schedule is made up of jobs
It may make more sense to create the jobs and then create schedules for these jobs. Or you can also have the option to run the jobs manually.
In this way, it would have a “jobs panel” and another “schedules panel” for the schedules of these jobs, where the schedules would be created and would simply point to one or more jobs already registered. You could even use a job in more than one schedule.
I said this because I was enthusiastic about this chart in the other post about the interface: 
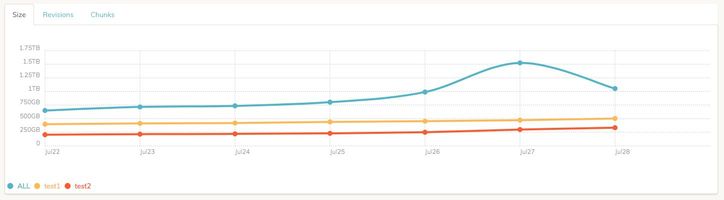
I thought I could see the growth of backups considering the revisions already created.
2 Likes
This is because ~/.duplicacy-web/repositories/localhost/all/.duplicacy doesn’t exist. I’ve fixed this in my code base, but for now the workaround is to manually create this directory.
Each check run only updates one day’s data points. Once you have it running for a few days the graph will look much better.
Sure, I understand this, but once the log itself gives all the information below, would not it be possible to put this on the chart? Is the chart data being fetched directly from the log?
| rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
| 1 | @ 2018-09-18 10:28 -hash | 89714 | 7,530M | 5956 | 6,983M | 3 | 664K | 5956 | 6,983M |
| 2 | @ 2018-09-18 14:23 | 93117 | 8,582M | 6674 | 7,825M | 3 | 665K | 721 | 862,504K |
| 3 | @ 2018-09-18 14:57 | 93857 | 9,348M | 7310 | 8,591M | 0 | 0 | 639 | 785,088K |
| 4 | @ 2018-09-18 15:37 | 93857 | 9,348M | 7310 | 8,591M | 0 | 0 | 0 | 0 |
| 5 | @ 2018-09-18 16:43 | 94229 | 10,759M | 8409 | 10,001M | 0 | 0 | 1102 | 1,410M |
| 6 | @ 2018-09-19 09:03 | 94229 | 10,759M | 8409 | 10,001M | 0 | 0 | 0 | 0 |
| 7 | @ 2018-09-19 10:51 | 94231 | 13,559M | 9650 | 11,560M | 2 | 625K | 1244 | 1,559M |
| 8 | @ 2018-09-19 11:02 | 104840 | 14,813M | 10239 | 12,112M | 3 | 898K | 592 | 566,758K |
| 9 | @ 2018-09-19 11:21 | 104846 | 16,540M | 11496 | 13,564M | 2 | 737K | 1260 | 1,452M |
| 10 | @ 2018-09-19 11:56 | 108036 | 17,831M | 12540 | 14,838M | 3 | 1,394K | 1047 | 1,275M |
| 11 | @ 2018-09-19 13:54 | 115911 | 26,982M | 19951 | 24,027M | 3 | 1,606K | 7414 | 9,190M |
| 12 | @ 2018-09-19 17:29 | 116582 | 27,402M | 20310 | 24,449M | 2 | 1,255K | 362 | 433,387K |
| 13 | @ 2018-09-19 17:34 | 140031 | 28,712M | 21394 | 25,742M | 0 | 0 | 1087 | 1,294M |
| 14 | @ 2018-09-19 22:47 | 140031 | 28,712M | 21394 | 25,742M | 0 | 0 | 0 | 0 |
| 15 | @ 2018-09-19 23:12 | 140146 | 29,582M | 22091 | 26,616M | 2 | 1,359K | 700 | 896,530K |
| 16 | @ 2018-10-01 12:08 | 143039 | 32,275M | 24300 | 29,302M | 0 | 0 | 2215 | 2,691M |
| 17 | @ 2018-10-01 14:46 | 143039 | 32,275M | 24300 | 29,302M | 0 | 0 | 0 | 0 |
| 18 | @ 2018-10-03 16:36 | 152471 | 36,824M | 27982 | 33,871M | 4 | 3,442K | 3686 | 4,571M |
| 19 | @ 2018-10-03 17:32 | 160262 | 38,751M | 29539 | 35,807M | 5 | 4,386K | 1561 | 1,939M |
| 20 | @ 2018-10-03 22:38 | 206665 | 47,007M | 36386 | 44,099M | 3 | 2,476K | 6852 | 8,296M |
| 21 | @ 2018-10-09 10:32 | 206666 | 47,007M | 36387 | 44,100M | 2 | 2,197K | 4 | 2,695K |
| 22 | @ 2018-10-10 08:12 | 295375 | 67,187M | 52390 | 61,750M | 2 | 3,141K | 16006 | 17,653M |
| 23 | @ 2018-10-11 12:55 | 302363 | 82,221M | 64544 | 76,831M | 2 | 730K | 12158 | 15,085M |
| 24 | @ 2018-10-11 14:07 | 314503 | 98,739M | 78029 | 93,418M | 2 | 555K | 13489 | 16,588M |
| 25 | @ 2018-10-11 15:44 | 322082 | 104,970M | 83083 | 99,675M | 0 | 0 | 5058 | 6,259M |
| 26 | @ 2018-10-12 21:05 | 322082 | 104,970M | 83083 | 99,675M | 0 | 0 | 0 | 0 |
| 27 | @ 2018-10-12 21:12 | 325951 | 108,576M | 85999 | 103,296M | 2 | 1022K | 2919 | 3,623M |
| 28 | @ 2018-10-13 21:57 | 330412 | 113,831M | 90309 | 108,574M | 0 | 0 | 4314 | 5,280M |
| 29 | @ 2018-10-14 17:43 | 330412 | 113,831M | 90309 | 108,574M | 0 | 0 | 0 | 0 |
| 30 | @ 2018-10-29 08:32 | 343981 | 118,524M | 94181 | 113,286M | 2 | 1,501K | 3875 | 4,715M |
| 31 | @ 2018-10-29 11:50 | 346884 | 119,837M | 95229 | 114,605M | 3 | 1,817K | 1051 | 1,320M |
| 32 | @ 2018-10-29 15:19 | 347782 | 120,734M | 95938 | 115,507M | 0 | 0 | 712 | 924,889K |
| 33 | @ 2018-10-29 18:57 | 347782 | 120,734M | 95938 | 115,507M | 0 | 0 | 0 | 0 |
| 34 | @ 2018-10-29 22:46 | 349256 | 122,875M | 97687 | 117,657M | 0 | 0 | 1752 | 2,152M |
| 35 | @ 2018-10-30 09:16 | 349256 | 122,875M | 97687 | 117,657M | 0 | 0 | 0 | 0 |
1 Like
Another point: I noticed that the program is generating a single / unified preferences file with several entries with
"id": "duplicacyweb"
A curiosity: how will filters be referenced for each backup?
I didn’t see this while skimming through the other responses, but the buttons to delete a given storage or backup are styled the same way as buttons to add them.
This delete button

Should look more like the delete button for schedules.

2 Likes
I am really liking the direction of the GUI. I am evaluating tools for replacement of Crashplan, and Duplicacy seems to have a VERY powerful and flexible backend. But a simple GUI for non technical users (and technical users who don’t do enough with backups to enable them to do what they need to do when they need to do it), is critical for its wide spread deployment. New GUI seems to be making big steps forward to closing the gap that currently exists.
But a couple of early comments :-
-
Am I missing something, or does there appear to be almost zero security in the current beta. It seems once I start the process, anyone who hits the URL (local or across the net) can access the GUI and then I assume do whatever they want with the backups. Once I did the original access and created a password, then I could re access the same URL from anywhere and get straight in??? With that access, I assume someone could prune all my backups, or restore confidential files to locations they can access (eg network shares that already exist on the PC) all without access to my computer or backups etc etc etc. Unless I am missing something, this backdoor needs to be fixed ASAP or risk the security of beta testers backup data.
-
I am far from convinced that your strategy of focusing restores on the backup objects is a good idea. I suspect for non expert users, this could result in all sorts of unintended consequences. eg accidentally restoring over the latest version of a file when someone simply intended to look at a previous version. Another issue I see is for people who create a new repository at a new location to do the restore above for say a single file. To do this they 1st have to setup a “Backup” job. Now if they then go can run that “Backup” job as a “Backup”, then I assume it will then create the last revision as a backup with only the 1 restored file. I think all of this could lead to significant confusion. I think I would handle restores as a separate tab, and in the more traditional way. ie let people browse through their backups, then select what they want to restore, then select where they want to restore it to. Default to not overwriting existing files, but allow the overwriting of existing files with suitable warnings clarifying what is happening and confirming the overwrite etc.
-
While on restores, I have always found it useful the backup tools that allow directories to be browsed for the files you want to restore, and then to be able to see the different versions of the files that are historically available. Current GUI does not seem to be able to do that without having to browse through each revision independanding all the way to the file and repeat this long process over and over again for each revision. Workaround would be to go back to the CLI and do a “duplicacy history” to see the dates the file had changed, and then manually go and find each revision with the changes you are interested in to find each file. But this would be quite tedious, and ideally it would be quick to find and identify different revisions in the GUI all in the one place, and then if needed to restore different revisions as different files so they can be examined.
-
given it is likely to be some time before GUI can do everything, it would be nice if you could pretty seamlessly transition between driving with the GUI and the CLU. It appears this is probably reasonably simple using new CLI which I found at ~.duplicacy-web\bin\ and various repository configuration files at ~.duplicacy-web\repositories\localhost[0,1,etc,all]. But if I run the commands, I have to keep putting in the ssh and storage keys. Is this stored anywhere in a keyring which will enable the CLI to pull these out without having to reenter them?
I hope this is useful, as I am sure you must be busy.
2 Likes
Am I right in assuming the email notification functionality is yet to be developed for the new GUI. Is so, what you you think would be the estimate timeframe before this is likely to be available?
Here is the video of the reproduction, happens 100% of the time:
https://1drv.ms/f/s!ArUmnWK8FkGnkpdvWo1Rel9XsZ7Fyw
Off-screen I started the server, created the folder above and added SFTP storage named Tuchka
Note that pressing backup in the beginning does nothing.
Then clicking “+” to add “Check” schedule removes “Backup” schedule.
In the same folder I put censored json file and the log file.
There is nothing else, no other log file:
mymbp:~ me$ find ~/.duplicacy-web
/Users/me/.duplicacy-web
/Users/me/.duplicacy-web/bin
/Users/me/.duplicacy-web/bin/duplicacy_osx_x64_2.1.2
/Users/me/.duplicacy-web/repositories
/Users/me/.duplicacy-web/repositories/localhost
/Users/me/.duplicacy-web/repositories/localhost/all
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy/preferences
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy/known_hosts
/Users/me/.duplicacy-web/logs
/Users/me/.duplicacy-web/logs/duplicacy_web.log
/Users/me/.duplicacy-web/duplicacy.json
/Users/me/.duplicacy-web/stats
/Users/me/.duplicacy-web/stats/storages
/Users/me/.duplicacy-web/stats/schedules
Other minor things
- Dropdown boxes are indistinguishable from edit boxes (not obvious that it is a dropdown)
- cannot delete the schedule. Maybe because it is last one - but regardless I should be able to delete it.
- If you run the sever when the directory structure exists but is empty the server serves “resource not found” page. (i.e. probably it should be checking for actual content to be present as opposed to merely directory structure.
Edit. actually, I get that page regardless occasionally, and have to restart the server
Yep. After restarting the thing I now always get “404 page not found”, while nothing interesting in the log:
2018/11/06 22:47:30 Duplicacy CLI 2.1.2
2018/11/06 22:47:30 Temporary directory set to /Users/alex/.duplicacy-web/repositories
2018/11/06 22:47:30 Schedule 0 (12:00am, 3600, 1111111) next run time: 2018-1106 23:00
2018/11/06 22:47:30 Duplicacy Web Edition Beta 0.1.0 (FDA052) started
2018/11/06 22:47:34 127.0.0.1:51542 GET /lookup_stroage
2018/11/06 22:47:35 127.0.0.1:51542 GET /
2018/11/06 22:47:35 127.0.0.1:51542 GET /
1 Like
I have discovered another little bug with the implementation of the dialog box to edit the filters in the windows GUI. I can create a filter list without problems. However, it I come back later to edit it, I can navigate and select directories to exclude, but when I press the exclude button, nothing happens (directory item is not added to the exclude list). I can add things manually with the “Add” button and typing it manually. But selecting and pressing the “Exclude” button does not work.
If I delete all the entries and then add them all again including the new entry it works. But if I need to come back and edit this list later, I have the problem back again.
I clue to the issue might be in the way the directories can be selected, and the difference between what is displayed for a new entry and what is display for editing and trying to add a entry. For a new list, you are placed at the level of the repository that you are backing up, and you can only see the sub directories of the repository (which makes sense). But when you edit the list, you are ask to select from files in the root of the file system (ie in windows, C:, and any other drives you have mapped).
1 Like
Your points 2 and 3 are very important to me as well.
I’ve been trying to move away from CrashPlan for years, but nothing satisfies point 3 as nicely. It’s pretty easy for my users to restore a file by themselves with CP, in particular with the revision browser. There’s 0 risk of accidentally overwriting anything too.
If Duplicacy had those, I would migrate all my computers on the same day. Until then, I’ll have to swallow CrashPlan.
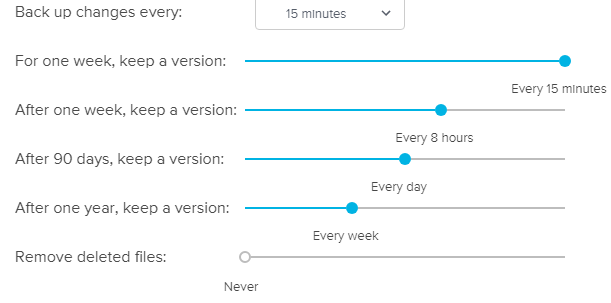
Another very nice thing to have is granular revision control. With CP, I set a backup job to have revisions every 15 minutes and keep a lot of revisions (see screenshot). I know nothing on the market with this feature set.
Easy way: change the listening address to a local one, for example, 127.0.0.1:8080, so the web GUI can be accessible only on the local machine.
Hard way: run the program with the -access-token option to specify a secret token, then open http://host:port/set_token to enter the token. Without entering this token first you’ll always get a 404 error for any page.
If the token is random, it will generate a random token for you.
I had another design for the restore flow before coming up with the current one. It can start on the Storage page, where you can click a button in each storage panel to browse the revisions/files stored in the storage and restore selected files whenever needed. Maybe this one is what you would prefer?
I need to think more, but this “history” feature is unlikely to make the first release.
All passwords are stored in the duplicacy.json file (so only one entry in the KeyChain/Keyring is needed for the master password). If you run the CLI from those directories, you just need to enter the passwords once which will then be saved to the KeyChain/Keyring.
Yes, email notification will be in the final release. I’ll try to get it done by next week.