
I setup prune on the GUI to only keep 1 every 7 days and I ran it and after that I ran the check, now it has missing chunks. I saw on the forum to run the prune again with exclusive and exhaustive, and its resurrecting chunks? Am I doing something wrong?
Missing chunks can be caused by many reasons, this is explained in Fix missing chunks. If you suspect that some fossils need to be resurrected, run a check with -fossils and -resurrect.
Ok i followed the guide and I think it fixed most things but when I rerun prune
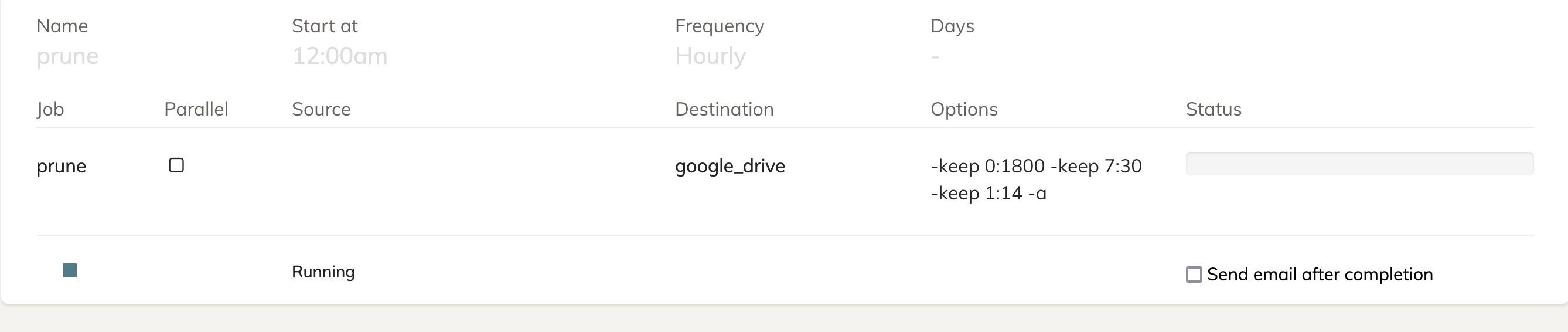
It has gotten stuck and when I click on the loading status for the log
I see this: 2021-12-01 01:43:34.208 INFO SNAPSHOT_DELETE Deleting snapshot xxxxx at revision 7
It seems to be stuck deleting this snapshot
It may take a very long time, specifically with Google Drive. I have seen it spend 48 hours pruning the 2 TB dataset.
If you want to see detailed progress (i.e., skipped chunk X, deleted chunk Y, skipped chunk Z…) – add -d flag to the global options.
But no reason to. It’s not stuck, it’s doing its job. It will take a while.
Hmm, its still stuck there its been like that for 19 hours or so, its a small backup as well, <100GB folder.
If I stop the prune, and start it again does that break things?
I’m using Google Workspace by the way, should I be creating my own project for the gcd file? I have been using the default way to login.
Won’t break things in the sense of it deleting data that wasn’t meant to be deleted anyway… you may have to manually delete snapshots files it never got around to removing. Lest they show up as missing chunks.
BTW the Web UI isn’t great at tailing logs so you might want to examine them directly in .duplicacy-web\logs with a text viewer.
In your shoes I might abort (ensure all processes are killed) and add the -d (or -v) global option but add -threads 8 to speed up proceedings.
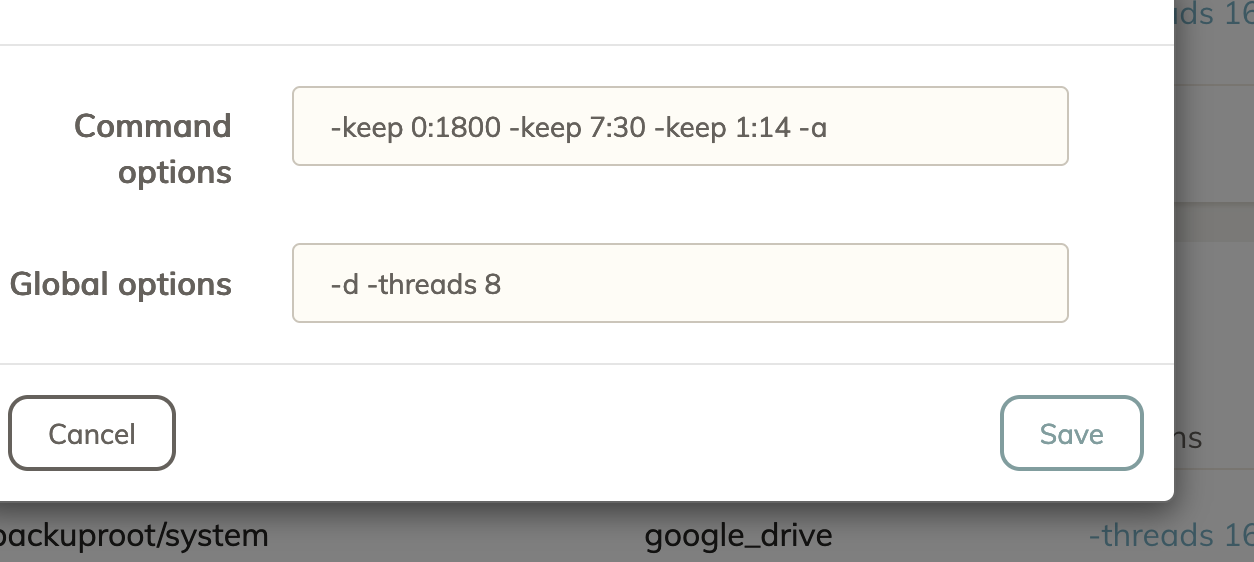
Like this?
It says invalid options when I try to start it. Looking at Prune command details it says that -d is dryrun? But saspus mentioned its for detailed progress?
Oh ok I got it working, i moved the threads to the command options. I’ll see how it goes and I’ll follow the log as it goes. Thanks for the help so far!
I keep hitting the rate limit: 2021-12-01 23:24:35.018 DEBUG GCD_RETRY [5] User Rate Limit Exceeded. Rate of requests for user exceed configured project quota. You may consider re-evaluating expected per-user traffic to the API and adjust project quota limits accordingly. You may monitor aggregate quota usage and adjust limits in the API Console: ; retrying after 2.80 seconds (backoff: 2, attempts: 1)
It would hit it, retry a few times and continue and hit it again. I have google workspace, would creating my own project help with this limit? What is the API limit anyways?
Google drive tolerates 4. I would (and did) set it to one.
You can generate your own credentials, but then you also need to maintain a service for token renewals that for tokens issued by duplicacy.com/gcd_start is currently hosted on duplicacy.com/gcd_renew.
On a separate note, Prune must be way more verbose and transparent: duplicacy knows how many files to delete, so why is there no progress? Also, hitting API rate limit shall be logged as warning at default logging level.
The guide is great, I will be using that I think. Is it possible to move my current duplciacy backups into the appdata hidden datastore? I’m not sure if that is what you’re doing as well.
Yeah I wish duplicacy was more verbose as well, and I wish the web UI has more features and options.
I don’t think you can move the datastore directly server side — two different scope are required for accessing app data folder and users drive.
But I guess you can run rclone with the same token in the google cloud instance and copy duplicacy datastore to avoid roubdtip through your home connection, if that is a bottleneck.
Ah ok, curious by the way, did you make the guide? Its pretty thorough!
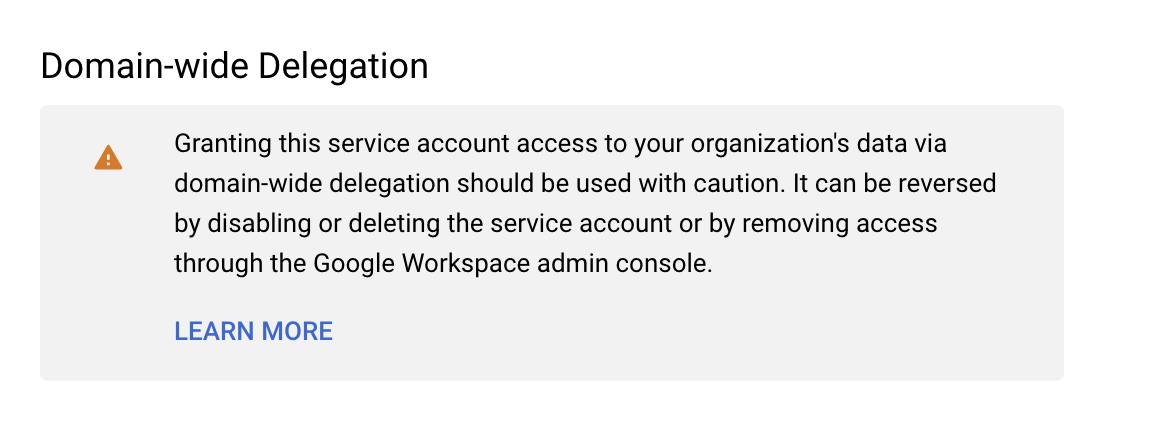
I am however seeing this, and I have authorized the client id in the admin panel to allow domain-wide delegation but I don’t see a check box in the service account menu.
Has duplicacy been updated to honor the subject and scope fields yet?
Also when I download the JSON credential files, the scope isn’t included in the file, and the guide only says to add the subject line.
Also thanks for the help so far! I appreciate it!
Yep. At that time I switched blog to a different CDN, and went overboard with large screenshots to see how it would work 
This is a warning, and it’s a correct warning. Service accounts can do anything. With great power comes great responsibility.
Not sure what checkbox do you refer to.
The PR was merged, so if you build top of tree you’ll have it. But is is not in the released binary as of today.
Building duplicacy however with modern go will fail. You’ll need to do this to address it: Building recent version fails with "Context.App.Writer undefined (type *cli.App has no field or method Writer)"
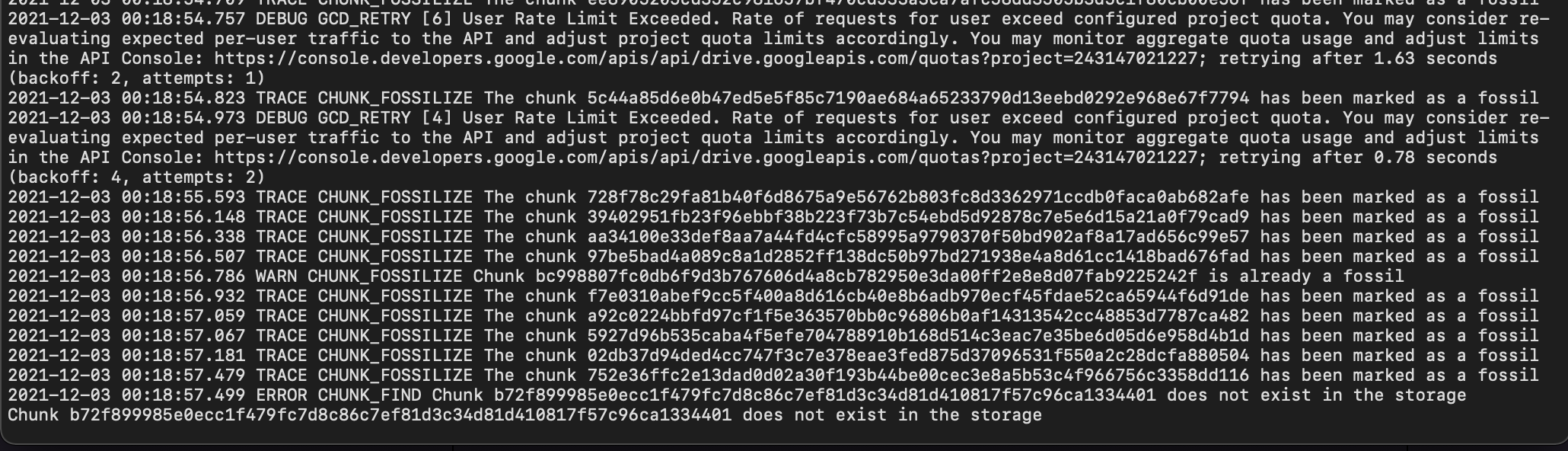
- Reduce number of threads to 1. There shall be no rate limit exceeding stuff. It just slows everything down
- Was there interrupted prune before? If so, missing chunks belong to ghost snapshots.
Yeah I have cancelled it in before this prune cause I wanted to use -d. Ok I’ll adjust my threads.
Should I delete my cache folder, change my threads to 1 and rerun the prune?