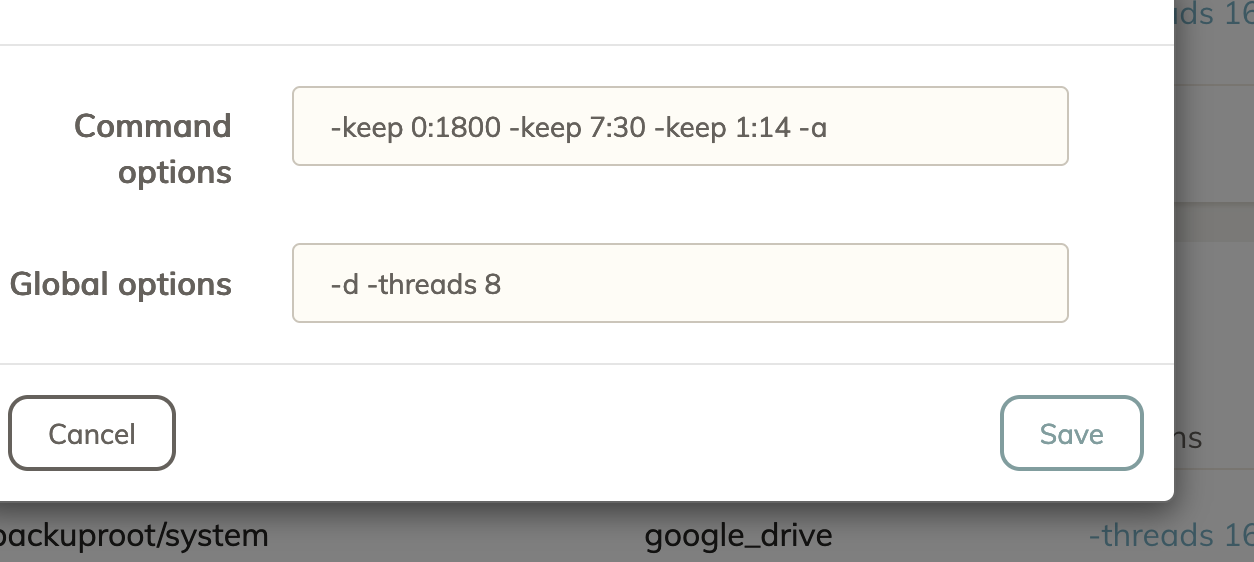
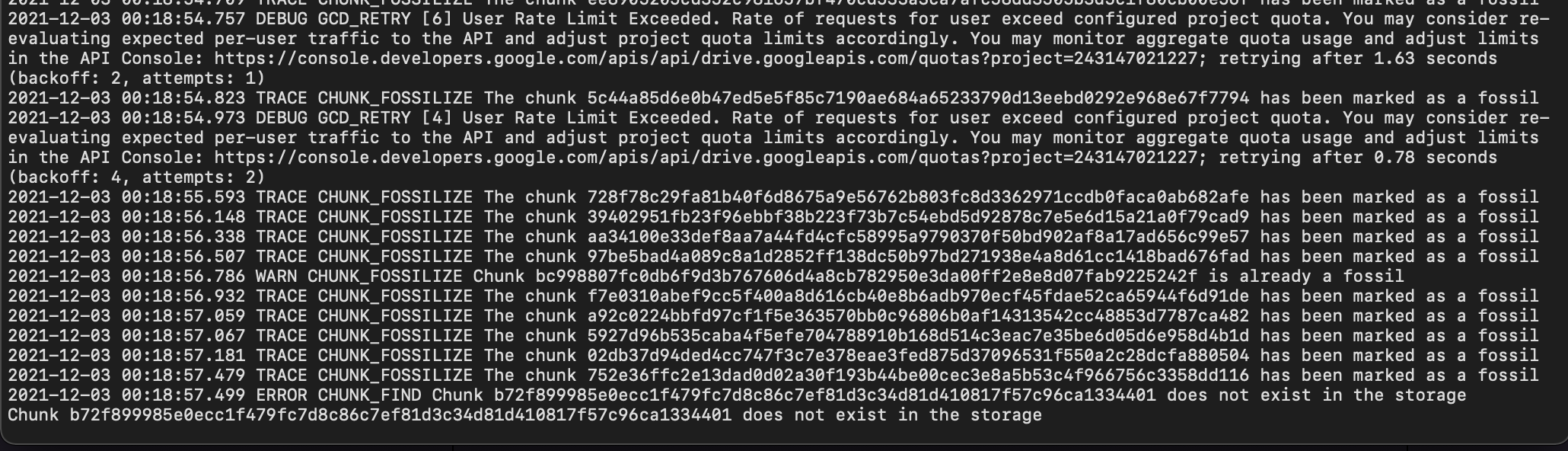
Ok i followed the guide and I think it fixed most things but when I rerun prune
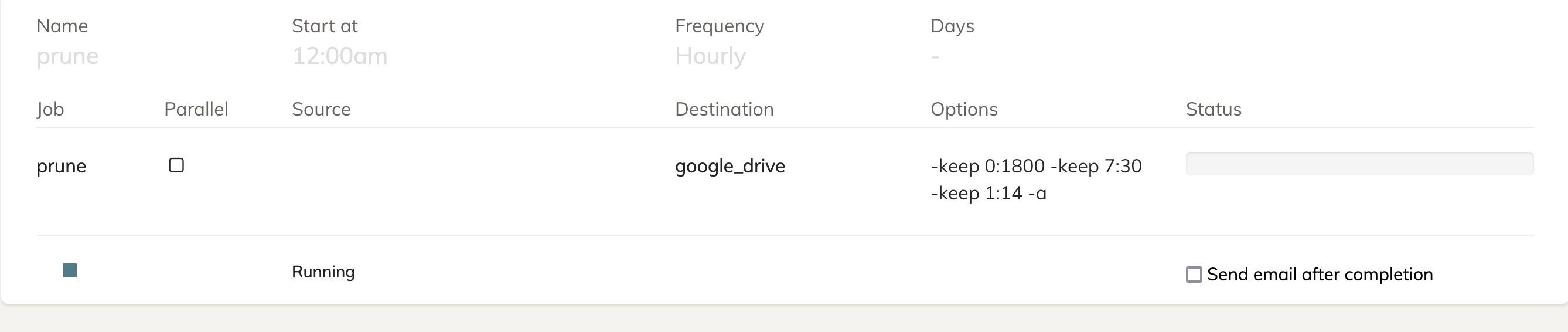
It has gotten stuck and when I click on the loading status for the log
I see this: 2021-12-01 01:43:34.208 INFO SNAPSHOT_DELETE Deleting snapshot xxxxx at revision 7
It seems to be stuck deleting this snapshot