I would say it’s more of a workaround than a “support”, I had to basically engineer my OS/Filesystem in a way to cheat the program into thinking that something that isn’t a folder (but a drive) - is a folder
The entire reason someone would pay and use a GUI version of the software is because they don’t want to deal with CLI’s (let alone OS-level CLI commands)
Both things (drives and simple inclusion/exclusion) need to be fixed, in my eyes, since both of them require a lot of manual, error-prone labor that is (or should be) simply unnecessary for the software to fulfill its most fundamental role: select a bunch of sources (regardless of where they are), select a destination, and backup from A to B
I’ve reread your earlier posts multiple times on this thread and the other (Best practice for single NAS + Cloud backup?). I thought I had a good grasp of what you’re looking for, but perhaps I still don’t.
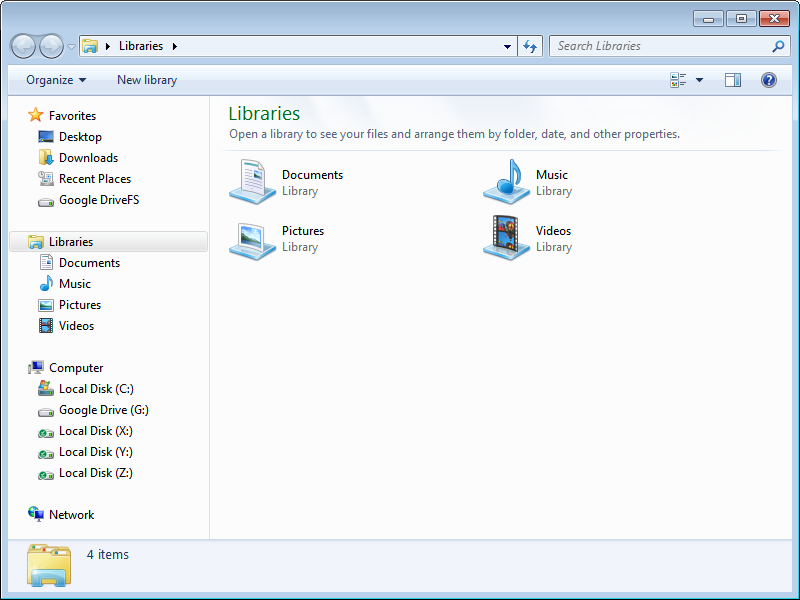
(The screenshots below are of Windows 7 + Duplicacy Web Edition 1.6.3 + Google Drive + Firefox on a virtual machine I created to mimic the example host system you described earlier.)
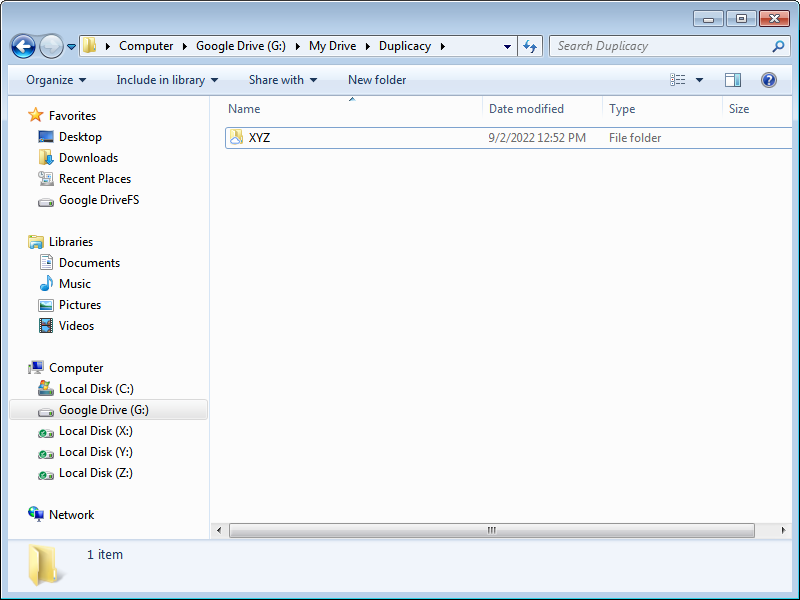
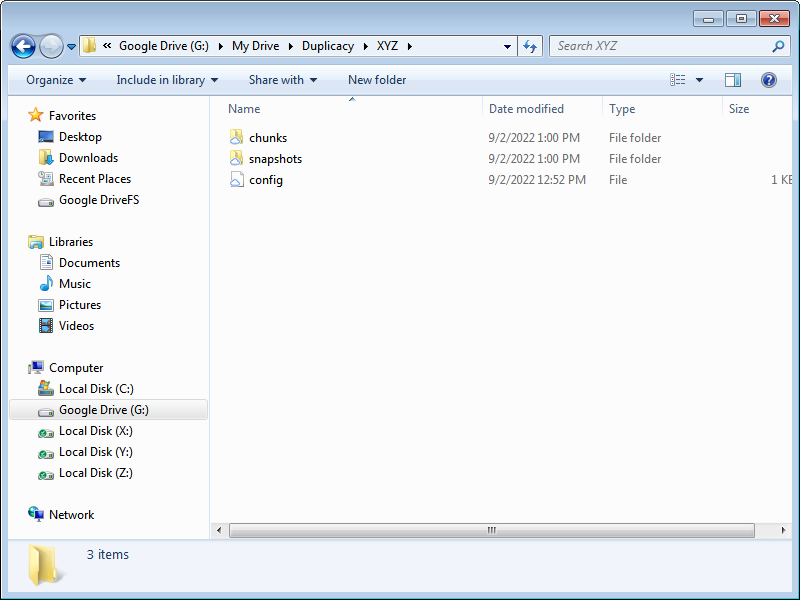
First up, Windows Explorer showing 4 internal drives (C:, X:, Y: and Z:) plus 1 virtual drive provided by Google Drive (G:). Nothing special about the Windows installation which is entirely on C:…
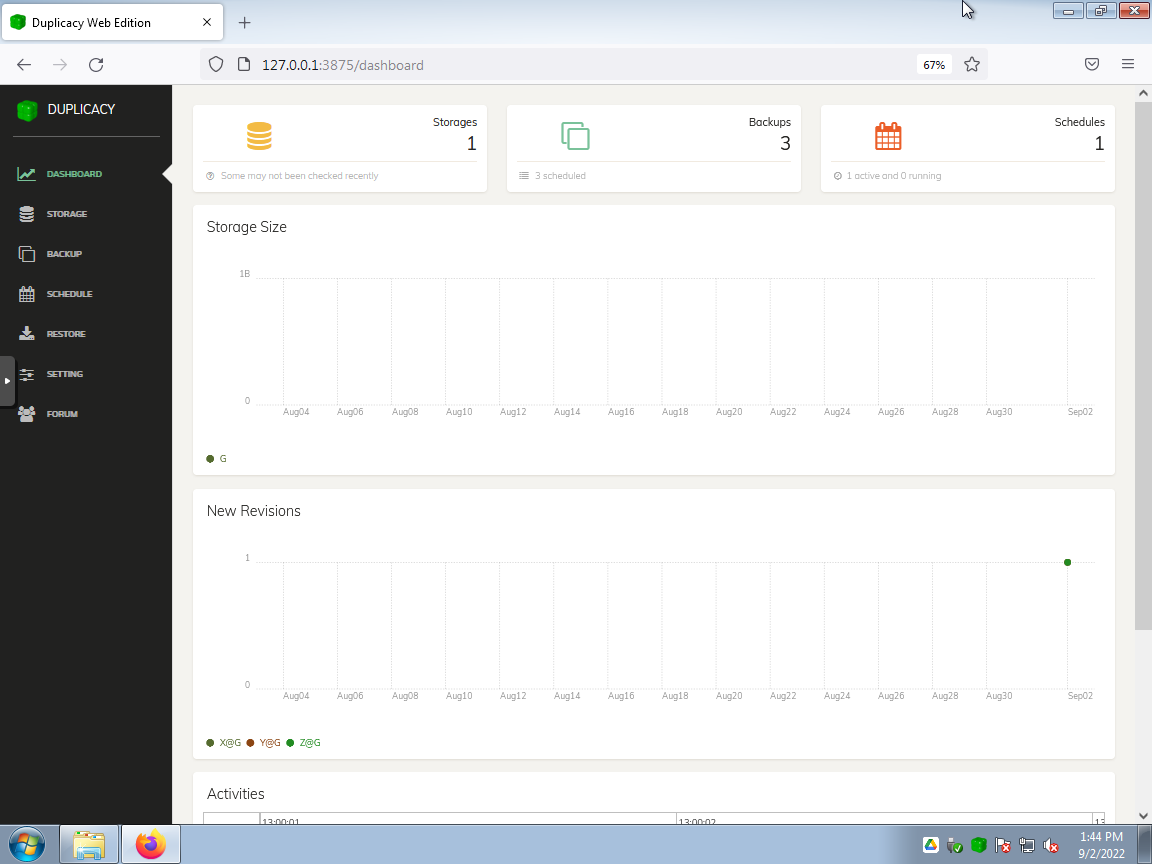
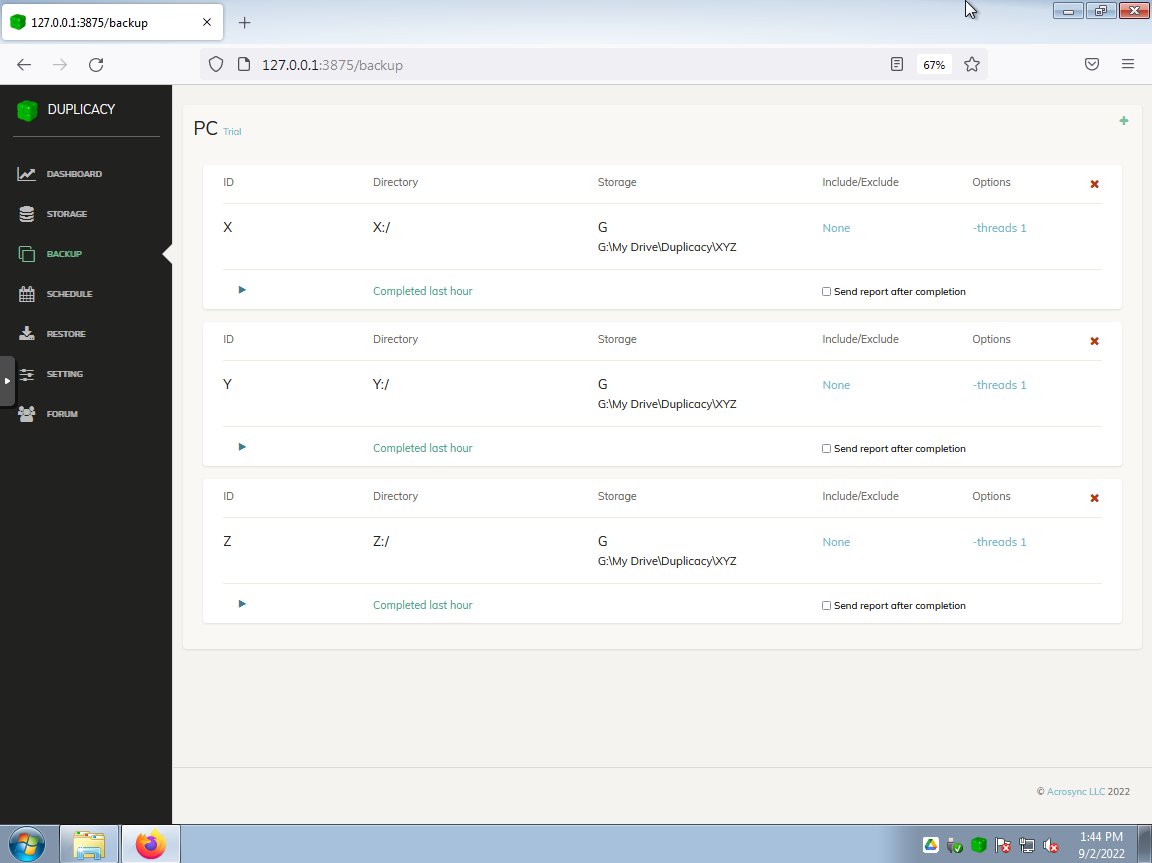
Storage configuration panel with a single target destination. As a twist, it’s pointing to the virtual drive (G:) provided by the Google Drive desktop client…
(Although G: is a virtual drive provided by the Google Drive desktop client, the storage destination could just as easily be Backblaze B2, Wasabi, OneDrive, etc. via a S3 API.)
Exploring a little deeper, here are the chunks and snapshots folders along with Duplicacy’s storage config file inside the XYZ folder…
Selected a bunch of sources (could have easily added a few folders too).
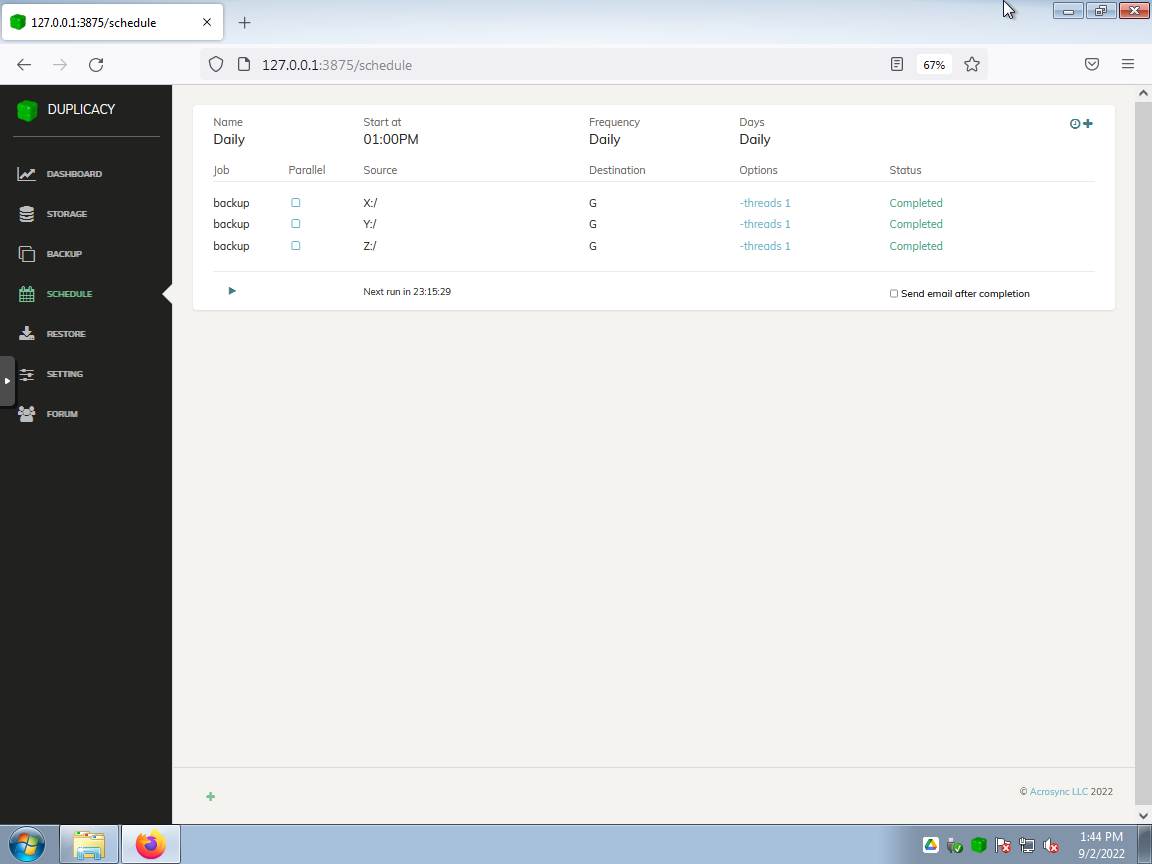
Set a backup to upload the sources to a shared storage destination (taking advantage of deduplication).
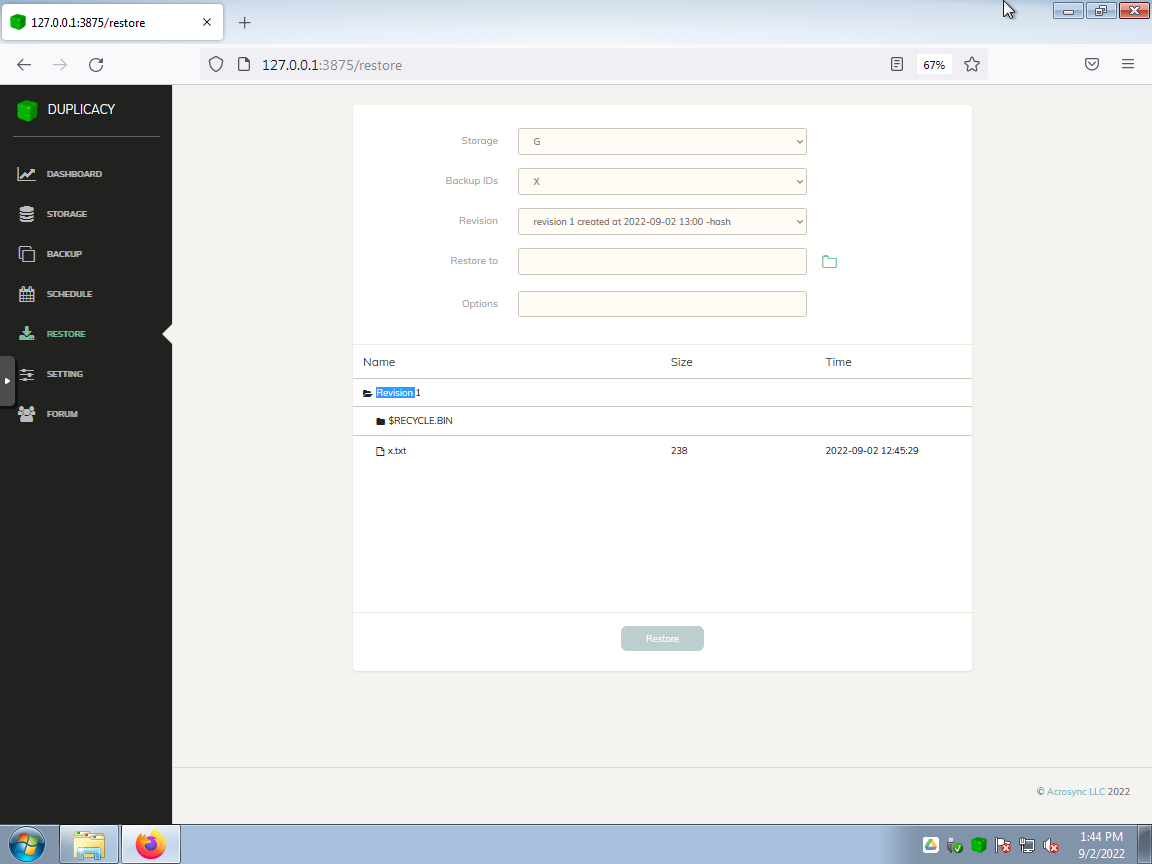
Showed that a particular snapshot revision for a source can be restored.
So if the requirement is to “select a bunch of sources (regardless of where they are), select a destination, and backup from A to B”, what’s missing from the example above?
(Setting up the virtual machine, installing Windows and other software, grabbing and editing the screenshots took 2+ hours… setting up the backup in Duplicacy took 2 minutes. )
Imagine that in each drive there is a folder that is a certain color (e.g. Z:\Red and X:\Red etc. as well as Z:\Blue and so on).
I want a single backup plan per color, not 3 backup plans per color,
because then if i have 3 drives and 9 colors i would have 27 backup plans instead of 9 backup plans.
Why do i want a backup per “color”? because it is exactly this property (i.e. obviously it’s not an actual color or even a folder with a color-name, it’s just a “code” for some arbitrary categorization of the data that spans multiple drives. In my personal case it’s a code-name for importance of the data, which warrants different treatment) that might influence things like destinations, the frequency, and other properties
I want to have for example a plan named: “red → gdrive” and a plan named “red → NAS”
I don’t want to have a plan named:
“Z-drive-red-gdrive”
and
“X-drive-red-gdrive”
and
“Y-drive-red-gdrive”
and
“X-drive-red-nas”
and
“Y-drive-red-nas”
and
“Z-drive-red-nas”
and then have the entire set — for blue as well (maybe with different destinations)
This separation to drives makes no sense
And then, let’s say there’s a new drive added to the mix, now I have to create maybe 19 new backup plans instead of just adding it to the very few I have that already describe exactly the logical type of source (rather than a physical location) and the destination.
I really don’t understand what’s complicated about this?
Instead of each backup in that list saying : “I am a backup of stuff of type RED but only those that happen to reside in X drive and i go to destination D1”
I want it to say: “I am a backup of stuff of type RED and i got to destination D1”
A new drive/source appears? great - i just add it to the include list of each relevant category (if it has any data of the relevant category) - and i’m done
Physical locations → described in include/exclude lists
Logical categorisations → Warrant creation of distinct backups
The existence of a new drive should not warrant creation of new backup plans, since it perfectly fits already into existing logical division of the data (e.g. “Movies” or “important stuff” or “Grandma’s docs”)
Is that any clearer?
Why does grandma’s docs span over 3 drives? who knows - maybe grandma is a bit disorganized, it doesn’t matter. For any other Windows program it’s a trivial feat to let me select multiple drive sources per a single “plan”.
Just like it makes no sense to have a backup plan per “folder”, it makes no sense to have a backup plan per drive.
In a perfect world, I wouldn’t need to create multiple backups per destinations either, i could just provide each logical backup scheme a list of destinations as well. That way for example the same include/exclude list wouldn’t need to exist 5 times if i have 5 different destinations for a certain logical division of my data.
Here’s a short “algorithm” of creating a new backup scheme that would perfectly capture what I’m trying to say:
Name your backup scheme (e.g. “Important Stuff”)
Choose sources for the backup (any drive(s), any folder(s) within any of the drives, etc.)
Choose destinations for the backup (from a list of pre-defined destinations)
That’s it
Now there’s a logical single entity to describe what would otherwise need to be “N x M” back up schemes, where N is the amount of possible physical sources (e.g. drives) and M is the amount of possible destinations (i.e. storages).
Simple.
Now i know that “important stuff” includes so and so data from so and so drives, and goes to these and these destinations.
I can easily add more data to the scheme with a single change, or add/remove destinations with a single change.
I don’t need to manage 18 different backup schemes (in case i have 3 drives and 6 destinations).
If i had 5 different categories (which i do), that might mean (in the worst case) i need to manage 90 (!!) different backup schemes, each with its own (duplicated) include/exclude lists.
Why?
Let me manage five backup schemes (one per logical category), because this is exactly what distinguishes them: their logical role, not their physical source or destination.
Since you’re still editing your post I’ll wait a bit before rereading it thoroughly, but the short answer to your question above is “Yes”.
What you just described wasn’t what was detailed in any of your earlier posts. You asked about creating a single backup plan that had multiple sources and a single destination. Even during the discussion regarding filesystem links and filters, the only mention of folders was not wanting to have to individually add filter rules to include them in a backup.
I think what you’re looking for can be done with Duplicacy (CLI and Web edition). But as I mentioned in an earlier post, the stumbling block here is Windows’ reliance on drive letters – Linux, macOS and other Unix-like operating systems are built on the “one big ‘virtual’ root” you were/are trying to achieve. It’s not that you can’t use Windows; it’ll just take a little more effort to make it do what you want.
Text-based online forums lack the audio and visual cues that are a part of normal conversations so I could be wrong, but I sense frustration and perhaps even some irritation. There’s no need for either. Everyone on this forum is here for the same reasons. I cannot speak for anyone else, but I don’t have mind reading mutant powers, so bear with me if I have to ask a lot of questions in order to help you.
You yourself referenced my previous post as well, which clearly indicated that I have multiple destinations and multiple logical “divisions” of my data based on its importance, so the combination of the two posts should indicate exactly what i’m trying to do.
The fact I tried to solve the problem of including multiple drives within a single backup (with a single destination) is simply because it was my understanding that Duplicacy doesn’t support more than one destination per backup-scheme.
I could live with having to duplicate my backups to account for multiple destinations for the same “source”, but having to ALSO duplicate them per drive was too much to cope with (it also defied any logic, in my eyes).
I didn’t want to confuse the forum with 3 different problems when i was focused on solving one. It’s customary to try and tackle one problem at a time.
The issue of filter patterns is another issue i encountered along the way which also forces duplication and manual labor.
But just from me discussing it you can easily surmise I have multiple folders in different drives (i even explicitly gave such a scenario in the examples i provided)
My point is that it shouldn’t. Other Windows software deal with this “problem” of drives perfectly well without forcing users to create virtual roots or symlinks. It’s rather wild to even suggest that it should be necessary…
Being misunderstood about something quite basic can be frustrating.
Asking questions is fine, if that’s all you did I would gladly answer each one to alleviate any lack of clarity about my explanations or examples.
What you did is mostly assume I’m trying to do “B” (after explaining rather in detail how i’m trying to do “A”) - and then to show me some non-solution and say: “See, easy!” and that is frustrating
Having you literally wasting 2 hours just to prepare the visual example you did only did more to add to my frustration. It’s like ordering an orange juice and having the salesman come back after a while with a chicken soup they toiled on for hours in the kitchen. I just wanted juice.
Again, what i’m talking about here isn’t some crazy suggestion — the “logical” division of backups is the most generic and universal implementation possible - since it even includes the present state of things (if anyone wished to divide their backups that way).
e.g. - want to have a backup scheme per source drive AND per destination?
With my suggestion of the “perfect” implementation - you could.
Want to have a backup schemes that includes multiple source drives, multiple destinations,
---- making the only difference between the different schemes - the question of which source folders are included in each scheme?
with my suggestion - you could.
and so on.
It allows the most flexibility since it doesn’t bind you to either a single physical source, nor a single physical destination.
===
and - again, regarding the frustration, you spent what seems to be hours also crafting the reply regarding the issue with the filter patterns ---- talking about loops, giving intricate examples that are completely irrelevant to the case, etc.
It’s not rocket science: it can be replicated with an easy - single folder - that is nested 3 layers deep —
and without the extra rules to account for intermediate paths – it simply doesn’t work.
Why? probably because there’s an implicit “Exclude everything” rule when there’s only include rules.
it has nothing to do with loops, with CentOS 8, with RHEL 4 with music libraries, with USB hubs or disk-on-keys or with the drive GUIDs — all these are completely foreign to the issue at hand and only serve to complicate the discussion.
It feels like you’re creating monologues or toiling on a visual user-guide instead of being laser focused on what i’m actually saying or what the problem at hand even is.
These are not “questions” to try and understand my use-case, these are long fables.
(I’m still reading and thinking about your recent post above, but just wanted to comment on one thing and ask a quick question.)
While I understood that you classify different types of data into various levels of importance, what wasn’t clear to me was which approach you wanted to use to achieve the desired goal (i.e., NAS to cloud, or virtual “root”).
Plus there was also no earlier indication that you wanted a particular backup to cover only a subset of files grouped into “logical divisions”, classes, etc. that span multiple sources, or as you most recently described, a “backup plan per color”.
You’re obviously well-versed with your backup plans and needs, so it’s perfectly natural that your earlier posts before today are clear as day to you, but it wasn’t to me – it’s why I posted the screenshots above because it demonstrated an approach that met the requirement to be able to…
However, backups analogous to a color-coded scheme is something else entirely different and not commonly done, even though some others might want the same thing.
A typical business might have email accounts, customer accounts (e.g., names, credit cards, etc.), and back office records (e.g., account receivables, inventory, taxes, etc.).
A typical company might choose to lump it all together by working via network drive shares from a central NAS that’s backed up to offsite storage. Much less complicated than backing up multiple computers and/or disks directly to a shared cloud destination.
My current employer used to take a similar approach… NAS plus a huge onsite robotic tape library that user devices (>10,000) uploaded backups to that eventually gave way to a hybrid local + cloud system before transitioning to a cloud-only model with every device syncing to Box/Drive/OneDrive (the company has all three) and backing up separately to CrashPlan (deduplication only between devices used by the same individual). There’s no stratification of user data. It’s all just a big digital pile per user.
I used to be a sysadmin for a research facility that had to comply with SOX, HIPAA and an alphabet-soup list of other federal and state regulations. Some of the instruments generated a terabyte of data per day – there was so much data that a Backblaze Storage Pod was assembled to keep up with the storage requirements. Emails, user files and instrument data were kept in separate data silos with the latter having the highest priority and more frequent backups.
Having used a lot of different backup software both free and expensive, I wish there was one that could easily do what you’re asking for because I’d want it too. I’m at a loss trying to name one that does exactly what you described.
Which brings me to my question… what is/was it about Duplicacy that drew you to it compared to Borg, Arq, Restic, Kopia, CrashPlan, Carbonite, Mozy, Backblaze (not B2), etc.?
And if there’s something about Duplicacy that makes it your first choice, wouldn’t a slightly more complicated setup be worth it?
The second you want to add an exclusion, though, things get more complicated quickly.
The filter guide says:
If a match is not found, the path will be excluded if all patterns are include patterns, but included otherwise.
If I’m understanding correctly, that means that the minute you add any exclusion, you now automatically include anything that isn’t explicitly excluded.
That’s why I have my patterns set up the way I do, as I posted earlier. I had to add -* at the very end to exclude anything I don’t explicitly include.
I also found that once I do that, my/ (in your example) is no longer sufficient, although it might only be if my is a symlink/junction. I also have to have my by itself (no trailing slash), or otherwise it’s excluded by the -*. I think it’s probably because the symlink is seen as both a file and a directory.
A shortened version of my filters I posted before looks like this:
I just tried again, and I think this is the minimal set of filters I can write (without considering regex at least) to include everything in C/Users/Compeek and all of its nested subfolders, except for C/Users/Compeek/AppData.
It took me a while to figure this all out a few years ago when I did it, but it’s been working great, so I can’t really complain. However, a simpler syntax for the filters would definitely be nice. (I’m not saying it’s an easy problem to solve–I’m a software engineer myself so I can certainly understand why it is the way it is.)
I’m trying to include several drives in a single backup (see post title), so - all paths are relative to some arbitrary directory containing symlinks to all my drives
Z is a symlink (to a drive), not a directory
it happens to reside in Z:/root (i.e. its full path is “Z:/root/Z”) but that’s irrelevant to the point
Yes, that’s the idea, i was describing rules that i’m adding beyond the rule:
+Z/my/cool/sub/folder/*
That is the only one that should exist because it perfectly describes what i want: all the files and sub-folders from this folder
I shouldn’t have to also add 5 more rules (and 5 are absolutely necessary as i said because they are relative to the root, not to Z) to describe the inclusion of a single folder (no matter how nested it is)
Just the fact we have to have this discussion about how many rules are even needed to include a single folder - is indication enough to me (and should be for anyone else) that something isn’t right: this should be as trivial and obvious as the sun in the sky. Same goes for multiple drive support
Your entire process is complicated. Why aren’t you using a method to organise your data properly? Pool your drives with mergerFS or DrivePool. Then you wouldn’t have to deal with this mess.
You should be reminded that @gadget here (nor I) isn’t the Duplicacy developer - you didn’t pay him, and you’re certainly not entitled to lay into him for trying to help you out. Really not cool.
The part where he explained link types on various OSs and their limitations - which Duplicacy isn’t responsible for - should get you to a working solution. I won’t expand on that coz I reckon messing around with symlinks/filters is extremely messy and unwise. Particularly if you don’t understand the syntax.
Duplicacy is designed to allow you to pick multiple backup IDs (repositories) - and that’s how you should probably do it across drive. It’s easy, noob friendly, and works well with very little overhead (de-duplication).
Plus trying to bundle everything into a single repository will only lead to pain, when you run out of memory to index files.
I don’t see the problem here. This is exactly how rsync filters work, they’re extremely powerful because of it. You could argue Duplicacy’s GUI could take care of this for you, but if you can’t achieve it with CLI, you have a whole different problem.
Seemed to be flexible enough (i.e. allowed me to pick specific sources unlike Backblaze which just backs up everything by force)
Supports a wide array of destinations
Supports encryption, de-duplication
Seems to be actively developed and comes up very often on reddit as a recommended software — this just means it’s unlikely to become abandonware anytime soon
Reasonable UI (the fact it’s web-based actually increases the chances for agile development compared with a full-blown OS integrated one)
Considered and tested Arq but there were tons of complaints about instability. Also felt very slow.
Kopia and other similar ones — seems like it’s very early stage (alpha/beta) so not mature enough
Depends.
Is the complicated setup a necessity ? if the answer is no, then i would expect it to be fixed - and become an effortless setup.
Otherwise, I might look for alternatives.
The specific examples you gave regarding various strategies that different individuals or businesses might choose are not important: of course every person or group might have their own agenda as to how to organize their data (and hence their backups).
For backup - I like to group it logically as I described (by importance)
That is not how it’s organized on my HDD’s (since data moves around arbitrarily, i run out of space and buy a new one and maybe move things around or spread them over multiple drives)
In the end, I don’t see any special reason why a backup scheme (also named a “backup id” here) should be limited to one drive OR to a single destination
A logical unit that points at multiple sources, and can be “attached” to multiple destinations - is simply the most high-level, generic, universal abstraction of the concept of a backup flow - i.e. - a linkage between some origin(s) and some destination(s).
What characterizes this “unit”?
the chosen sources
the chosen destinations
its name
That’s it.
Now, what if you want a more complex setup, for example, you want to make SOURCE1 flow into DESTINATION1 every hour, but you want it to flow to DESTINATION2 once a week?
Well, then it is justified to replicate the backup-scheme into two separate ones, so that each one could be scheduled differently (of course, it would also be useful if there was a “duplicate” button, which there isn’t)
But as long as what distinguishes your distinct backup schemes is just their SOURCE mapping, your scheme list could be extremely concise
Basically, things should only be “replicated” (i.e. there should only exist more than 1 instance of a certain definition) if they warrant some kind of different treatment by the software (number of threads, frequency, maybe other more advanced features like the erasure thing or whatever)
So for example, if i wanted to treat all the 5 importance categories exactly the same, it wouldn’t make sense to make 5 different schemes for them, even if i technically could.
in my case - they should be treated differently: they should go to different destinations - AND - they might require different backup schedules
Not familiar with these things, and - i don’t want to “organise my data” differently just because i’m using a backup software. I’m perfectly content with how it’s currently organised.
This “mess” only exists because :
the software doesn’t let me pick multiple drives per a single backup-id / repository.
every inclusion rule requires N+2 other rules, where N is the depth of the folder
As i explained, if i fully utilise it the way it was suggested i would have to literally maintain 90 different backup-ids
That’s unreasonable.
I don’t see what you mean here?
I don’t try to bundle my entire data, my data is grouped to several categories by importance.
I want each “importance” category to be a distinct backup-id —
why is that problematic in terms of memory?
How much memory do i need to achieve what i just described?
You don’t see the problem with the fact i have to add five rules per folder i have to include?
So if i have 20 folders i want to include i need to maintain 100 rules? some of them overlapping with eachother?
I don’t have a “problem” - the program does.
Literally every single other backup program i tried (e.g. google drive, arq, acronis) let me select multiple drives in a single backup scheme, and in all of them, i could visually just select folders and have them included in the scheme, without having to “engineer” some list of intermediate paths that “lead to” the desired folders.
Why is that such a huge challenge that warrants pages on pages of discussion?
Dedicating a backup scheme per drive would be tolerable if i had one destination. I don’t, i have five destinations. So 3 drives, 5 categories and 5 destinations means 75 different backup schemes to both create and maintain.
I’m not a sysadmin,
this isn’t a business,
I’m just some average joe with a lot of data that wants to carefully select which data goes to which destination and when, without paying an arm and a leg for the privilege, and without spending hours setting up or maintaining these backup schemes over time.
Then I guess “deal with it”, because that’s what you’re gonna have to do with how Duplicacy is currently designed. IMO, your lack of organisation is the main problem, without Duplicacy getting involved.
Furthermore, that structure is needlessly complex and you simply don’t want complexity in a backup solution. What you’re asking for is trouble - if you forget to add/change symlinks (or go into the backup software and reselect directories or deal with filters) - as data is added/moved. Quite frankly, if your drive/structure changes that much, all the more reason to look for a proper solution.
Drive pooling IS that solution, why ignore the tools that will save you sooo much grief - they exist for this very reason.
But you do you.
Why should it? Duplicacy allows multiple repositories with little overhead - it doesn’t need to.
Not Duplicacy’s problem if you cba to craft proper filters for your overly-complex structure.
If you really have that many drives, you have a lot of data. Trying to cram too many files into a single repository has memory use implcations - and splitting that data up is enabled, and encouraged, by Duplicacy’s design of location-agostic de-duplication. (Works the same from multiple source computers as well as source directories.)
Going back to the analogy world, that’s like kids running in front of Teslas should “Deal with” the car’s inability to identify them in time.
Technology is built to deal with the world, the world shouldn’t be “redesigned” to deal with technology.
My situation is not unique - I’m sure a decent amount % of people who have over 10TB of data might have some disorganization or have their data span multiple drives.
Drive pooling is a complete overkill. I live peacefully and without any problem with how my data is at the moment.
Asking me to change it is like telling a diabetic person to transfer their brain to another healthy body - instead of just giving them some insulin.
No, i will not transfer my brain.
i just want a tool that isn’t crippled by the fact some data is on 3 different drives.
The fact that EVERY other backup tool i mentioned deals with this effortlessly indicates where the problem actually is
There is no grief.
I live perfectly fine with how my data is.
Now i simply want to also back it up, that’s all.
Because as i explained, if i fully adopt the suggested solution i would need to have 75 backup schemes instead of 25 (which is already a redundancy that shouldn’t exist, because i don’t really need a backup scheme PER destination)
Again, literally any other program that allows you to visually pick multiple folders using a GUI, on windows, copes with this effortlessly.
You’re describing it as if I asked to do something exotic like apply some algorithm on each folder to determine if it should be included or not…
No, i just want to select 10-20 folders.
It’s not exotic, it’s not unusual, and it shouldn’t require me to craft a complex filter file with x5-x10 many rules (depending on the average depth of each folder) to account for the intermediate components of each path.
So, it is in fact duplicacy’s problem.
Again, forcing the user to manually labor at something the program can figure out on its own.
All the program needs, as input from me, is:
what things i want to backup
where i want them to be backed up to
on what schedule
that’s it - if i need to manage memory consumption myself for the software, something has clearly gone wrong in the design stage.
If the program needs to treat each folder as its own repository, or each drive as its own repository, to better deal with memory usage ---- it is free to do so, no one is “stopping it” from doing whatever is necessary to be efficient - internally - under the hood.
I, as a user, should not be expected to manipulate how my backup scheme looks like, or split it into dozens of different repositories - just to make sure the program doesn’t have RAM issues.
It’s a concern that should be completely abstracted away from the user.
Asking me to manage memory utilization myself would be like forcing me to create a separate S3 bucket for each 1TB i want to backup - for some obscure internal reason. It makes no sense.
btw, I’m not “alone” in my “madness”, @saspus seemed to agree with at least what i said about the filter pattern issue.
I feel like we’re going in circles here.
I’m describing what i consider to be like the A, B, C of simple software design (and as a software engineer with 16 years of experience, i know a thing or two about it)
and you defend the existing product no matter what concerns are raised, blaming the users for their own “messy computers” or some other nonsense.
So, i suggest we put it to rest here, since it isn’t leading anywhere
If you fail to understand why a person might want to group multiple drive sources into a single backup (btw, who said it’s a lot of data? maybe it’s three separate 250GB SSD’s? what concern is it of you or the program?) and you’re sending them to redesign their file system just to be able to back it up,
or - fail to understand why it is unreasonable to force people to create N+2 rules for every single folder they wish to include (of path-depth N) - then we truly are living in different galaxies - I’m speaking English and you answer me in Klingon.
So far, i at least managed to overcome the multiple drive issue with the symlink HACK
and - i can cope with the need to manage complicated and needlessly redundant include patterns until i find a better replacement (or until it’s fixed )
And that’s why we have zebra crossings and the green cross code - because we don’t currently live in a world where that technology actually works yet. What you’re trying to do is drive your Tesla up curbs and complaining when the battery explodes. See? I can make shitty analogies too.
Besides, Musk is a fraud.
Drive pooling is one of the first things any self-respecting datahoarder looks for. Your stubbornness to avoid looking at blatantly obvious tooling, concepts, is why you’ll continue to flail around.
Actually, it’s you that’s needlessly forcing complexity into your backup setup.
My point is this has nothing to do with Duplicacy, or whatever backup tool you use. Whether you use symlinks, filters, or manually tick check boxes - you’re willingly choosing to select stupid amounts of individual backup locations - an ‘include-only’ approach, instead of ‘include-everything’ by default. Going down this route you still have to manually keep a very close eye on what’s included, almost every time you add/move data.
IMO, it’s a poor backup strategy, labourious, and will bite you in the ass. You simply wouldn’t have to do this nonsense if you had a pool of drives. But sure, ignore my advice and continue driving around in your Tesla with your eyes closed…
But… it does.
Every single backup software i mentioned allows you to both select things from multiple drives AND to only state each folder inclusion a single time, instead of having to describe it using as many rules as it has intermediate path components…
The “technology” exists.
All you have to do is simply apply it.
The only one who is “stubborn” here is you - in trying to force people to change everything from the ground up about how they work with data, just so they could use this tiny backup tool,
whereas I recognize that there are many use-cases in the world: home users, businesses, etc. each with their own justified or unjustified reasons for why they have this organized a certain - very particular - way
A good tool is agnostic to how data is “organized”, and is not so opinionated so as to necessitate people to work with ANOTHER external tool just to “organize their data”.
A good tool is flexible, universal, and able to adapt to multiple possible setups - rather than force upon its users a plethora of constraints, rules, voodoo rituals and manual-labor chores.
With respect to these two “issues” - every other tool i mentioned is a “good tool”.
They are not good tools compared to Duplicacy in other respects, perhaps (e.g. supporting multiple types of destinations), but that is besides the issue.
because i don’t want to include everything.
why should i be forced to “include everything”?
Not only do i NOT want to backup “everything” - i want the few things i DO want to be backed up - to be treated differently: e.g. some folders i want to backup to 5 destinations, other folders i want to backup to 3 destinations, and so on.
Same thing with schedule frequencies.
Engineers and architects don’t tell people how they should be living their lives, how they should be crossing bridges or arranging their apartments: they build tools, buildings, infrastructures that fit the actual world people live in, with all its seeming “flaws and imperfections”.
If in order to use your floor-cleaning-robot your customers need to completely redesign their apartment, invite an internal decorator etc., you probably built a pretty problematic product. Especially if it’s a pretty common apartment setup (e.g. they didn’t place their furniture on the ceiling, it’s just another plain old apartment just like any other)
of course not, since I know what are the folders under which the data i wish to back up resides.
Whether it’s 10 or 20, etc. - doesn’t matter - it’s a handful of folders, i know them very well, they span multiple drives, and whenever (once in a blue moon) one would be added, all i would have to go is go and add one include rule to the backup scheme
Let’s do a survey and ask around how many home users (who have over 10TB of data and use backups) bother to use “drive pooling” tools.
You live in this bizarre alternate dimension where this is a common thing, for me - it’s literally the first time i ever even heard of it - since owning my first computer 23 years ago.
So, the fact i managed to run into a TON of backup software, sync software, etc. and not even hear this term mentioned once, is probably indication - as i said - we live in totally different worlds.
So, as I said, it’s the time to put an end to this pointless circular discussion
I would bring up the fact every back up tool i mentioned (I’ll also add Sugarsync to the mix, as another example) allows to do both things (choose sources from multiple drives, and do a “single action” per folder you wish to back up, instead of 5 ) as the best indication for what is considered proper and customary, and you’ll… keep babbling on about drive pooling and other external tools i guess
if everyone is driving on the left and you’re driving on the right, you might wanna reconsider whether you might be driving on the wrong side of the road.
Then might I suggest you have a lot of catching up to do…
On Windows, Drive Bender has been around donkey’s years - although perhaps not quite as good as StableBit DrivePool (which works just as well on desktop or server), and there’s always Microsoft’s Storage Spaces.
On Linux, you have ZFS pools, mergerFS, and probably many others. Though these are the ones used by most users I know that hoard TBs of data across multiple drives at home.
Even Drobo and off-the-shelf NASs can pool their disks into a single volume. Most RAID setups accord pooling as a side benefit.
You can even combine DrivePool or mergeFS with SnapRAID to add redundancy.
In a world where you want to keep myriad disks, this is common, yes. Common sense.
Maybe if you didn’t wrap your search queries in quotes, you wouldn’t be so in the dark all the time. Equivalent terms: drive pool, disk pool, etc… If you don’t already know what it is, you should let Google figure that out for you. Or, y’know, follow up on DrivePool or mergerFS which I already told you about.

 )
)