That’s your problem.
Ext4 raid can not detect or correct bit rot. Switch to BTRFs or zfs with data redundancy and checksumming enabled.
Obligatory link to explanation of why, how, and what now: https://youtu.be/yAuEgepZG_8

That’s your problem.
Ext4 raid can not detect or correct bit rot. Switch to BTRFs or zfs with data redundancy and checksumming enabled.
Obligatory link to explanation of why, how, and what now: https://youtu.be/yAuEgepZG_8
I do not find a file called
4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02
in my backup storage. How can this be?
duplicacy check did not reveal any missing files:
All chunks referenced by snapshot xxx at revision 345 exist
All chunks referenced by snapshot xxx at revision 346 exist
1 chunks have a size of 0
Chunk 0bbe097db03c668070a400cd8f89b13bb8d327e9f4506b632daa4ef242559c8c has a size of 0
Ok thanks but this does not help me with my restore.
@gchen is there a way to skip this chunk file and continue the restore?
That chunk should be found under the subdirectory 4f with a file name starting with 5bb437....
To skip this chunk, you’ll need to find out what files that are affected by this corrupt chunk and exclude these files in the restore command.
How to do this?
That chunk should be found under the subdirectory
4fwith a file name starting with5bb437
2752512 Mar 8 13:25 5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02.etxoukth.tmp
1015808 Mar 8 13:25 5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02.rukzppzj.tmp
6651904 Mar 8 13:25 5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02
I hope its ok if I send you the file via private message
edit:
btw: is it possible to run the check -file command against a single chunk?
IMO, it’s more likely than not, that the chunk was corrupted during transfer and neither Btrfs or ZFS would be able to detect it either - the fs is storing the files it was given, just fine.
I’ve seen too many missing and corrupted chunks (without seeing any kind of disk failure) to know these unexpected, but seemingly relatively common, failures aren’t necessary hardware related.
I’d really like to see remote checksum verification on the sftp backend (via md5sum/sha1sum) and on any cloud storage providers that support it (surprisingly many).
Do you have backup logs going back to March 8th? Would be interesting to see what it says when Duplicacy attempted to upload the chunk.
Incidentally, the log may also narrow down the list of files that were backed up on that day and time.
Those 3 chunks are divisible by 1024, which indicates they’re all corrupt. I’m just wondering how each of them compares to each other, perhaps if you use a tool like Beyond Compare’s hex compare? Expecting the first two to match the beginning of the third, but still would be interesting to check.
SFTP and any other encrypted transfer protocols would fail if data was corrupted — it would simply fail decryption. Even SMB with packet signing will guarantee that the data will arrive intact.
Over which protocol? I have never seen corrupted chunk over SFP to bitrot aware storage and B2. Did I get lucky or is there something fundamental that prevents it.
The only possible corner case I can see is if the transfer is interrupted and partial file remains on the destination. In this case it’s a simple fix for Duplicacy to verify size of uploaded file and re-upload it if it is not what was expected. Or upload to temp file and rename after. I think that’s what Duplicacy is doing, no?
That would be the best, yes.
I did  please let me know how I can continue my restore
please let me know how I can continue my restore
You can turn on debug logging by running duplicacy -d restore -r revision. This will show you the file it is trying to restore when the error happens. You can then exclude that file to see if the restore can continue (you may need to exclude multiple files).
Now back to the issue. Since there are two .tmp files that are significantly smaller the the third one, I think what happened there was that the first two attempts to upload the chunk failed (possibly due to a full disk?) and the third attempt went further but it still seems to be incomplete given the decryption error.
I then noticed that in the sftp backend the returned value of the Close() call is not checked:
So maybe the call to Close() returned an error but Duplicacy ignored the error and continued to rename the chunk? The right thing to do here would be a Sync() call before closing the file but unfortunately the go ssh library doesn’t provide such a call and even if it did it would require the “fsync@openssh.com” extension to be available on the ssh server.
In any case, the returned value of Close() should be checked for correctness. I’ll release a new CLI version over the weekend to add this check.
Definitely not 
1TB still free and on this device and the device is only used for duplicacy backups.
In any case, the returned value of
Close()should be checked for correctness. I’ll release a new CLI version over the weekend to add this check.
Nice to hear that you implement an enhancement for SFTP backups.
This is very complicated to be honest to find out:
filetorecover1 chunk 795f21605693263bbdb1d3fe60b9f6b7bab4604be11996d4daabb6456b7d6940 is not needed
filetorecover1 chunk fb69301dfef91f1508cfbae05ec9e4e5f4014d5f6aa3a77d2ac40220df6cb232 is not needed
filetorecover1 chunk 82f459996a02bc5da6d0f8d9ce29144eec4d91094a75cd128893949dfcb41315 is not needed
Updating \\?\W:\xxxxx\filetorecover1.MP4 in place
Chunk a1c8e97df3cb634ccc63608687f602efade67821a87181da4c35e54609de0f29 is unchanged
Chunk 046187690733996879251bd433070a75ceb483ed0009280d50eeda656df04cda is unchanged
Chunk 73e7ee944d855dc22d2c14f7dc265bfe43a96159352005143f8208eeacb7748b is unchanged
Chunk db041c02858419ad5b9f9934247c9d43d2a60dd33398144a21d32b228e4593f7 is unchanged
Chunk ea3293a399ceae86348e2affcfe3b5d8b526f828fb6c44a51f95978d927c7b20 is unchanged
Chunk 1c291a843d0038a183d44741d0cb76bab2f1ef8591b653376cd3900c6c51d4ee is unchanged
Chunk cde4d71af38c0be4e31033170ab9b479b3d6e2909fbdfccf2a27fa578ed8b91c is unchanged
[...]
Fetching chunk 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02
Failed to decrypt the chunk 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02: cipher: message authentication failed; retrying
Failed to decrypt the chunk 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02: cipher: message authentication failed; retrying
Failed to decrypt the chunk 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02: cipher: message authentication failed; retrying
Failed to decrypt the chunk 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02: cipher: message authentication failed
filetorecover1.mp4
could be restored without any problem. The debug output does not point to the file which is related to 4f5bb437441b6e7235375d5b3d00c039fb8678721866c491c6257441150c0c02
I still can’t restore at the moment.
edit:
filetorecover1.mp4 was not recovered completely. the video stopped at about half of its length. After exclude this file from restore, the restore failed again with the next corrupted chunk
Downloaded chunk 1200 size 1936097, 12.95MB/s 03:11:50 3.8%
Fetching chunk 2bb9cbc3bc4e9966ba1531c14ad2fa373c4046a5f0c6fbd414c74d073269630c
Failed to decrypt the chunk 2bb9cbc3bc4e9966ba1531c14ad2fa373c4046a5f0c6fbd414c74d073269630c: cipher: message authentication failed; retrying
Failed to decrypt the chunk 2bb9cbc3bc4e9966ba1531c14ad2fa373c4046a5f0c6fbd414c74d073269630c: cipher: message authentication failed; retrying
Failed to decrypt the chunk 2bb9cbc3bc4e9966ba1531c14ad2fa373c4046a5f0c6fbd414c74d073269630c: cipher: message authentication failed; retrying
Failed to decrypt the chunk 2bb9cbc3bc4e9966ba1531c14ad2fa373c4046a5f0c6fbd414c74d073269630c: cipher: message authentication failed
searching for tmp files gave me more then 1000 results:
[/share/Backup] # find -name *.tmp | wc -l
1012
all tmp files together have 3,22GB
To skip every file / chunk manually does not look reasonable for this backup

back to the concept of the restore:
Having a corrupt junk seems very likely in huge backups. Why not just continue the restore and automatically create a text file or a console output which list all failed chunks and all failed files?
It would also be great to have the possibility to check the integrity of the backup. What I found with the check option is that I could only check for the existence of all chunks or to download every single file (which would cause a lot of traffic) and check it. Is there really no other way to make sure backups are not corrupted?
You can use check -files or check -chunks, but - as you correctly point out - Duplicacy has to download chunks to do that. Though -chunks may be more efficient than doing a restore, as it won’t redownload de-duplicated chunks.
Although, having said that, a restore at leasts caches successfully restored files locally, so you won’t have to download them again.
A more efficient procedure might be to attempt to copy the storage locally, which does two good things - avoids re-downloading de-duplicated chunks, and will error out if any of these chunks are corrupted. (Although it might be nice if Duplicacy can continue on, just like we need restore to do.)
Several ideas about making it more robust have been suggested.
One of my own suggestions was to put the checksum of each chunk in its filename, but I dunno how much it’d affect RAM usage.
Did you try to exclude filetorecover1.mp4 when running restore?
Furthermore, if you happen to have another copy of that file, you may be able to fix your storage by 1) renaming the bad (non-tmp) chunk out of the way, 2) setting up a new dummy backup to backup only that file to the storage (optionally include a copy of the few files which were originally listed alongside the bad file in the same directory - i.e. a few files just above and below, alphabetically in the list). This might re-upload the corrupt, and now-missing, chunk to the storage.
I have more then 1000 tmp files.
You can leave the .tmp files alone, but you should be able to incrementally complete the restore by excluding individual corrupted files as it encounters the bad chunks.
It jumps from corrupt file to the next corrupt file. So far all corrupt chunks have a temp file.
How are the timestamps of these .tmp files distributed? I wonder if they were generated by one or two backups. If you still have a log file from the backup that created one such .tmp file then it should show what error it encountered.
You can try to restore one subdirectory at a time. Or find a revision that is outside of the time range of these .tmp files.
Oldest one from 2019
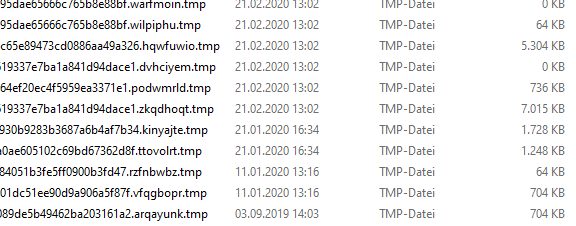
Newest one from last month:
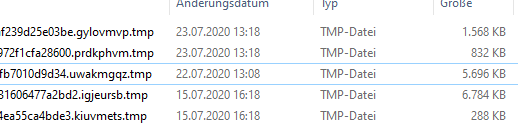
Unfortunately not 
a lot of manual work…
Not all .tmp files necessarily indicate you have corrupted chunks. I’m assuming here, but where you have a .tmp file with a chunk ID (file name) corresponding with a chunk file without the .tmp extension - that’s where you may have a bad chunk and maybe a bad backup snapshot. The .tmp files aren’t normally seen by Duplicacy, and their presence doesn’t mean you have a corrupted chunk or backup. The problem you have is with the chunk files that were ultimately renamed from .tmp to non-.tmp.
All you have to do is keep running the restore, with debugging enabled, to a temporary location. Duplicacy should skip files that were restored in a previous run, so it should be quick.
When you encounter a bad chunk, add the corresponding filename to the exclusion pattern, then do another restore. I doubt you have that many bad files TBH.