Ok, so I’ve finally had some time to work on this. However, it’s not related to restores (finally just kept at it until it finished), but instead for copies as I’m thinking of bringing on another cloud storage vendor.
For some background, I have ~1Gbps synchronous internet . I am backing up to 1 Azure storage account with a single container (root folder). In that container I have ~970GB of data in ~250 revisions and ~222500 chunks. My backup runs hourly with a daily check and weekly prune. This has been working consistently for awhile (maybe 1-3 failures due to TCP resets throughout a week), and I typically update ~50-100MB/hour. To test copying ability I created a new container in the same storage account - NOT bit-identical. Azure specifies a max of 50MB/sec bandwidth for a storage account (theoretically my network could saturate that). I’m also running the Web UI in a docker image (saspus/duplicacy-web).
I attempted to run the initial copy and it continually kept sending the TCP reset at various times during the initial copy of all the revisions. To get around this and get them up to the same I spun up an Ubuntu VM in Azure and did the copy via the CLI. It completed successfully with no TCP resets on the first run - yay.
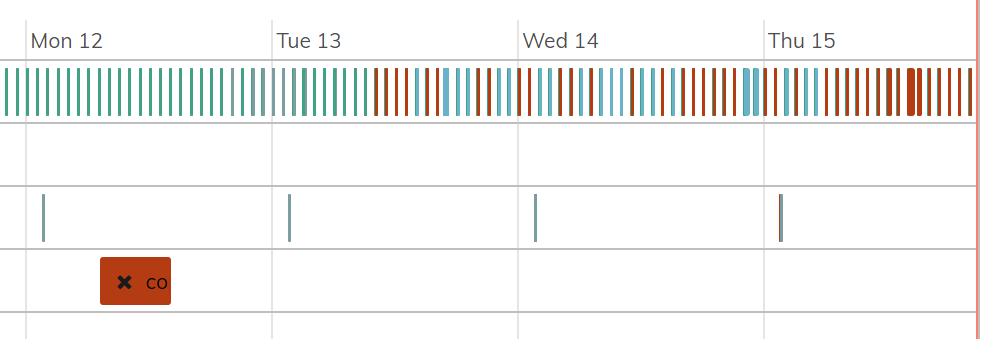
Now, I want to keep my backup and copy sync’ed. On my hourly schedule I have the regular backup that runs and then the copy that runs (NOT in parallel). I have had very little luck getting the copy to complete successfully without having a TCP reset that isn’t retried. In the image below you can see the initial copy fail on the 4th row along with all the hourly failures.
As per the recommendation I’ve been playing with the -upload-limit-rate and -download-limit-rate settings. After the few hourly failures I tried 20000 for each (20MB/s) which theoretically would’ve been less than the 50MB/sec max. After that failed for a over night, I moved it down to 10000 for each, then 1000, then 500, then 100, and finally I’ve set it to 5 and I am still receiving the same errors. During all of this I have not added the -threads options. It does not appear to be related to the rate.
As mentioned the Java SDK seemed to have a similar issue with retries that was fixed earlier this year - https://github.com/Azure/azure-storage-java/issues/363#issuecomment-480969209. It’s possible that moving to a new version of the SDK may help with these due to both sync and async IO improvements.