Datahoarding community is a drop in the ocean. It’s nothing. A blip. For comparison, long ago, just this one company I worked for with 70k people all moved to G-Suite. I know for a fact they did not use any storage beyond the trivial amounts for email and a few documents. There are hundreds of thousands of other organization, school, universities, that pay for accounts without utilizing any nontrivial amount of storage.
If Workspace was just storage space – then $12/month/2TB is already cheaper than GCS it is being run on! But then there would not need to be Workspace – there is already google cloud storage.
It’s a marketing tool, not a secret really. And 10 people on reddit and over rclone knowing about it is not really representative set of google customers.
Incredible in what sense? Dozens? Hundreds? Thousands? Still a drop in the ocean compared to all other users with paid accounts that don’t use them.
You don’t need gigabit connection for that, I"ve been using it on 50/10 internet just fine. And no, it will not become mainstream because it requires some technical skills. Vast majority of people don’t posses those. You may think they do because you are part of that small tech circle – but for most people configuring rclone is beyond their capabilities or interests (and there is absolutely nothing wrong with that). Also, these are just consumers. Business users will go by the terms and if they need huge amount of storage for each employee – yes, they’ll likely pay for enterprise. Perhaps, they’ll do it regardless, due to other services included in enterprise; and that’s the point.
You can’t seriously think that!. Google did not get around turning on quotas?. Come on! They built all that ultra reliable and flexible infrastructure, but just can’t keep track of quotas!
But see, no, today google workspace does not enforce quotas either. They had plenty of opportinities to implement quotas during rebranding. They did not. So we are back in the same state where, as you said:
In other words, nothing changes with migration to workspace with respect to their willingness or probability to enforce quotas.
This is not and was never obstacle. if (domain.accounts.count > 5) domain.settings.quotas = ON is not a rocket science. Box.com figured it out – you think google attracts worse talent? 
Again, I feel number of data hoarders is minuscule and a drop in the ocean. It may not seem to you this way because you are part of that community. (yes, I too keep tens of terabytes of encrypted media there)
Of course they will. It’s free marketing. Even you think that there are many data hoarders due to how vocal is that community. It’s free advertisement for google.
Overall the product line is successful. And cost of storage that hoarders use for free does not even begin to cover value of free marketing they provide.
Google builds reliable platforms. How do I know? I used them extensively in a way they were not designed for. You did too. Why? Because of this “secret”. And now I’ve just written this sentence, which is the best advertisement google can ever get – testimonial from an impartial user. If google did not provide me with the opportunity to use their services – I would not have knows how awesome they are. That’s the value they get from it. It is worth way more than you or I can even manage to consume in storage costs.
This all would have been true even if that was purely cloud storage company. But google isn’t. Their income is advertisement and B2B services. The whole google cloud is responsible for under 10% of their revenue. Storage in workspace accounts is essentially complimentary. These $12/month you are paying are not for storage, but for all other stuff. In other words, storage is free.
They could, and they did not. Do you think they did the same “oversight” twice? It’s clearly part of the plan. I’d like to see google’s chief of marketing face expression if they happen to read this thread
I’ve read somewhere ( I think it was one of the google support discussions, or maybe reddit) that if you keep abusing the business accounts (abusing meaning in petabytes) they may ask you to move to enterprise.
But most importantly, if you are that user that has say 400TB dataset: does it really matter either for you or for google whether you pay $20 or $10? It’s zero, for all intents and purposes. It makes no difference. So, why bother, and risk pissing off a very vocal minority of customers?
Backblaze published the histogram of their users data usage. They too have data hoarders who figured out how to backup 100TB at $6/month. It’s a very steep curve. Vast majority of people pay $6 and use virtually nothing. And that’s pure storage company. With google – most people sign up to use spreadsheets and email, so the curve will be even steeper. Then having those minuscule amount of heavy user triple or 10x their usage has negligible effect.
Noted. I think it won’t. Let’s revisit in 5 years :). I’ll set a reminder in my calendar

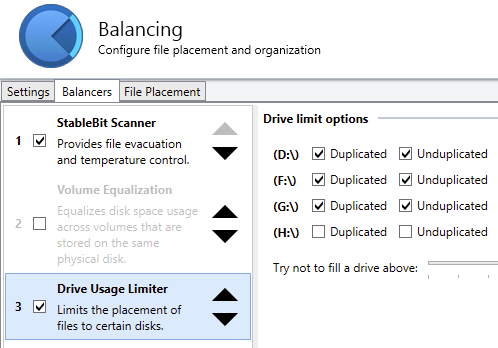
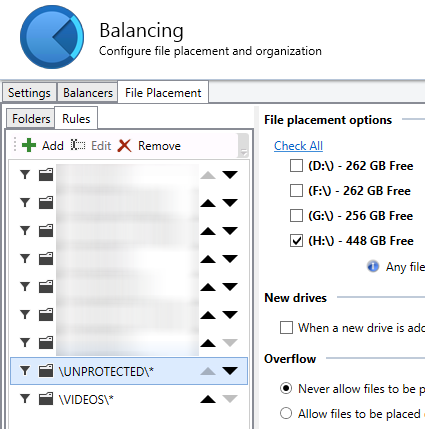
 Metered cloud storage is just too expensive for us.
Metered cloud storage is just too expensive for us.