Ensure you have enough RAM — depending on the number of files per backup duplicacy can be quite memory hungry.
Duplicacy support STORJ natively. There are pros and cons in using S3 gateway, both your own or STORJ provided ones, and they should be evaluated separately. That tutorial just describes how to configure any s3-compatible storage, but so does the official quick start Quick Start · gilbertchen/duplicacy Wiki · GitHub and built-in command help.
The file is readable by duplicacy. But so is the data being backed up. If your server is compromised – your data is as well.
Can’t comment on linux keychains, maybe someone else will chime in, but on macOS it works quite well.
However note that use of keychains only ensures that only the application with the specified hash can read the keys. Which means the attacker can still do everything duplicacy can do with your backup, including deleting recent revisions by calling asking duplicacy to prune with carefully crafted parameters.
This is an unnecessarily strong and unattainable goal unless you have hardware key storage. You can use Mac mini for example, or just setup the system in the way that keys and credentials are useless for the attacker.
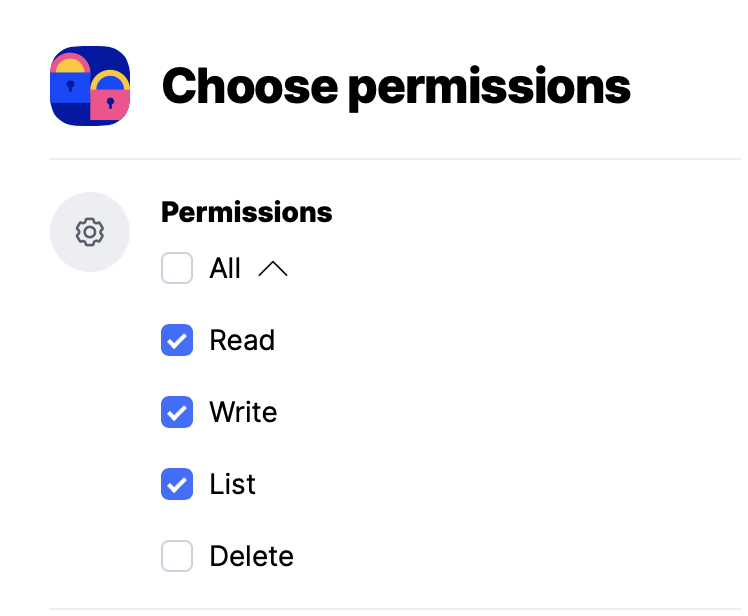
For example, generate cloud storage credentials that can only add and read files but not delete. The support for object lock would help here but it is not yet implemented: Is S3 Object Lock supported? - #2 by gchen
Neither you nor attacker will be able to run prune and/or delete data with these credentials, the backup will be effectively immutable. This is an example of accomplishing this with Backblaze B2: Backup Immutability - Object Lock support? - #22 by tallgrass. With STORJ you can create access grant or S3 credentials that prohibit delete:
I’m not sure if write permission allows overwrite, would be interesting to check.
So, this will protect against modifications and deletion. To protect against data disclosure you can use RSA encryption to encrypt your backup, to prevent the attacker that got full access to your PI from also reading your backups: to decrypt and restore data you would need to provide private key, that should not exist on the machine that is only expected to do backup.
But then again, if attacker steals you pi along with your storage server – it already got all your data.
This is all sounds like a massive overkill though. What is the attack vector you are trying to protect against? If the adversary is targeting you specifically to the point of scrubbing credentials from a raspberry pi – I’m sure there are other, much less high tech avenues to get you to provide all the passwords and biometrics “voluntarily”