
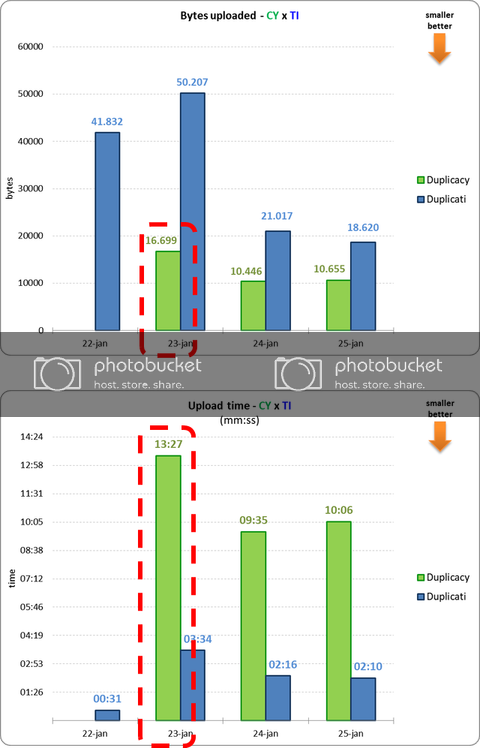
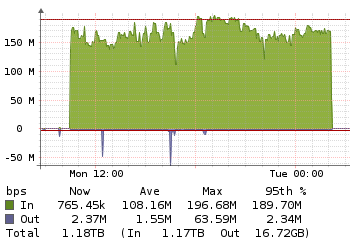
- How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
- If the upload was so small, why the total size of the remote has grown so much?
I’m puzzled too. Can you post a sample of those stats line from Duplicacy here?
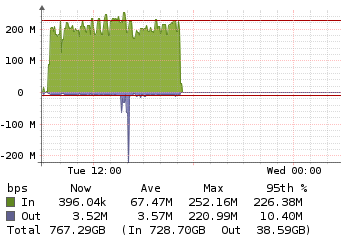
- Why did Duplicacy last upload take so long? Was it Dropbox’s fault?
This is because the chunk size is too small, so a lot of overhead is spent on other things like establishing the connections and sending the request headers etc, rather than on sending the actual data. Since the chunk size of 128K didn’t improve the deduplication efficiency by too much, I think 1M should be the optimal value for your case.

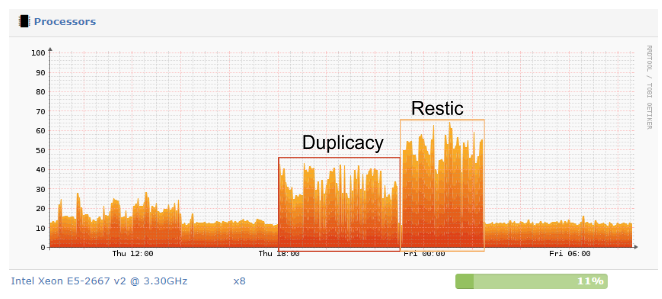
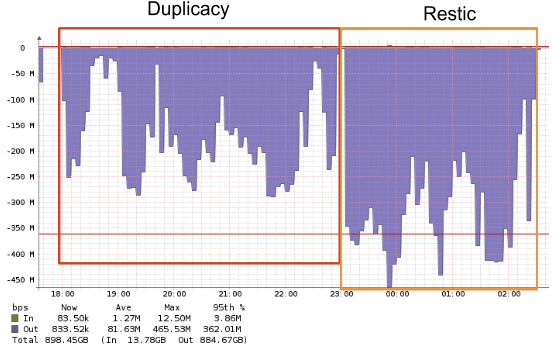
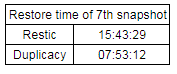
 Such as half the restore time, lock free dedup and lower backup sizes.
Such as half the restore time, lock free dedup and lower backup sizes.