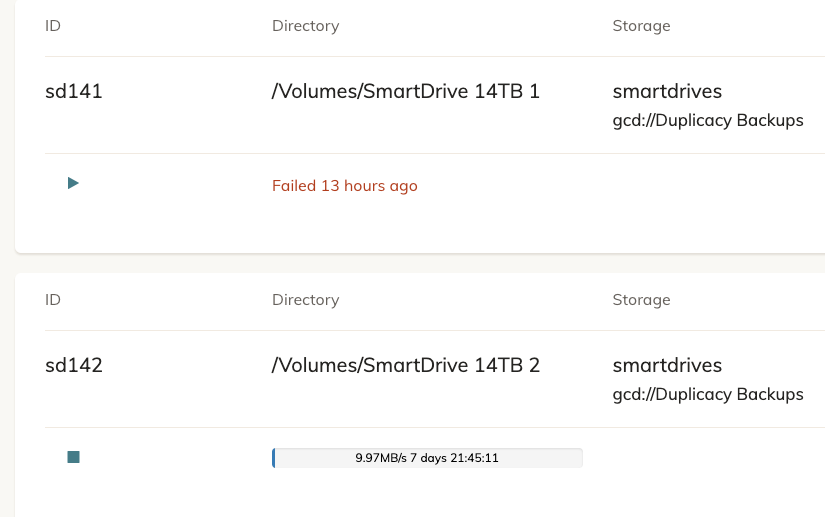
Can someone tell me what’s going on with my backup? Here is the log:
Running backup command from /Users/__________/.duplicacy-web/repositories/localhost/7 to back up /Volumes/SmartDrive 8TB 3
Options: [-log backup -storage smartdrives -stats]
2021-04-15 12:26:11.021 INFO REPOSITORY_SET Repository set to /Volumes/SmartDrive 8TB 3
2021-04-15 12:26:11.021 INFO STORAGE_SET Storage set to gcd://Duplicacy Backups
2021-04-15 12:26:13.660 INFO BACKUP_START No previous backup found
2021-04-15 12:26:13.660 INFO BACKUP_INDEXING Indexing /Volumes/SmartDrive 8TB 3
2021-04-15 12:26:13.660 INFO SNAPSHOT_FILTER Parsing filter file /Users/nathanscherer/.duplicacy-web/repositories/localhost/7/.duplicacy/filters
2021-04-15 12:26:13.660 INFO SNAPSHOT_FILTER Loaded 0 include/exclude pattern(s)
2021-04-15 12:26:13.663 WARN LIST_FAILURE Failed to list subdirectory: open /Volumes/SmartDrive 8TB 3/.Trashes: permission denied
2021-04-15 12:26:15.602 INFO INCOMPLETE_LOAD Incomplete snapshot loaded from /Users/nathanscherer/.duplicacy-web/repositories/localhost/7/.duplicacy/incomplete
2021-04-15 12:26:15.602 INFO BACKUP_LIST Listing all chunks
2021-04-15 20:06:46.524 ERROR LIST_FILES Failed to list the directory chunks/: read tcp [2603:9001:340d:f291:7977:59b2:7968:efd9]:50487->[2607:f8b0:4002:c10::5f]:443: read: connection reset by peer
Failed to list the directory chunks/: read tcp [2603:9001:340d:f291:7977:59b2:7968:efd9]:50487->[2607:f8b0:4002:c10::5f]:443: read: connection reset by peer
If there is any other information needed - let me know. This keeps happening every time I start a backup. I have other hard drives that work, but I have three that fail every time. Oh, and this is backing up to Google Drive.