One of my backups consists of my music collection, which is mostly large FLAC, DSF and DSD files that should (almost never) change. There are no duplicate files in the source (there shouldn’t be any!), and these files exist nowhere else, so I can use a dedicated storage location just for this backup set (regular documents/photos/etc would be backed up to a separate repository, shared by multiple PCs to make the most of deduplication functionality).
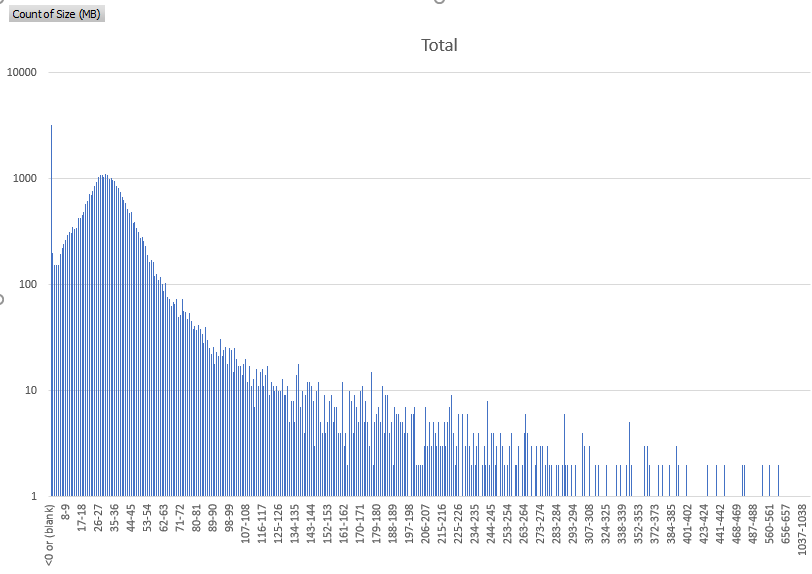
The file sizes vary, though these are primarily between 5-100MB (see distribution below), so with a default chunk size of 4MB it’s guaranteed that a high percentage of files will be split across multiple chunks.
An initial test backup of 1.3TB of data comprising of 65k files has resulted in 280k+ chunks being created, and I’m a bit concerned about performance when it comes to doing verification, restores, pruning data (very little should ever be deleted from here, so not sure that’s relevant), etc.
For “special” use cases like this, are there any recommendations on how best to configure chunk sizes and other parameters when initialising the repository and storage?
I’ll be backing up to at least two different destinations, neither of which (I believe) support rsync.
Also, AFAIK rsync doesn’t protect against human stupidity and/or system error? For example, some rogue process or human modifies files it shouldn’t. In other words, under normal circumstances, the data is immutable, but it’s the edge cases I’m more concerned about, which is why keeping “proper” backups is better than just sync.
To back up my music collection I use Rclone with the --backup-dir option, rsync also has this option. It’s simple and works very well (and fast). I don’t see the need to use an advanced product like Duplicacy in this case.
yep, its the same option for rsync. quoting from man page:
-b, --backup
With this option, preexisting destination files are renamed as each file is transferred or deleted.
You can control where the backup file goes and what (if any) suffix gets appended using the
--backup-dir and --suffix options.
Note that if you don't specify --backup-dir, (1) the --omit-dir-times option will be implied, and (2)
if --delete is also in effect (without --delete-excluded), rsync will add a "protect" filter-rule for
the backup suffix to the end of all your existing excludes (e.g. -f "P *~"). This will prevent previ-
ously backed-up files from being deleted. Note that if you are supplying your own filter rules, you
may need to manually insert your own exclude/protect rule somewhere higher up in the list so that it
has a high enough priority to be effective (e.g., if your rules specify a trailing inclusion/exclusion
of '*', the auto-added rule would never be reached).
--backup-dir=DIR
In combination with the --backup option, this tells rsync to store all backups in the specified direc-
tory on the receiving side. This can be used for incremental backups. You can additionally specify a
backup suffix using the --suffix option (otherwise the files backed up in the specified directory will
keep their original filenames).
--suffix=SUFFIX
This option allows you to override the default backup suffix used with the --backup (-b) option. The
default suffix is a ~ if no --backup-dir was specified, otherwise it is an empty string.
Thanks for the info, even though that doesn’t answer my question! I’d rather use a single tool for all my backups, and since duplicacy has been getting the job done nicely for my regular files, I’d rather just use that for the music collection too…
I’m on the same page as saspus and towerbr. Given the conditions you described, rsync is going to be a better tool for backing up your music collection if performance is a major concern even though it means using a separate tool.
But I understand the convenience of sticking with Duplicacy…
A well-curated music collection won’t have any identical tracks, and FLAC files are compressed upwards of 40-50%, so it’s difficult for a deduplication tool to find common chunks between two different audio files.
The larger the chunk size the less likely it is that it will be shared between multiple files. So for the purposes of deduplication, smaller is generally better, but not always.
Assuming that deduplication isn’t a priority, to avoid some of the hashing overhead, you could bump the average, minimum and maximum chunk size to a much higher value, e.g., duplicacy init -c 128M -min 128M -max 128M. Or for the least number of chunks, find the largest file in your music collection and set the chunk size to something larger than that. The result should be the number of chunks being fairly close to the number of files (65k in your case) unless it turns out there are actually lots of large identical chunks.
A few thoughts…
You didn’t mention the type of storage (e.g., NAS with RAID, USB drive), but regardless of if it’s hard drives or flash storage, bit rot due to failing media is always a possibility. The higher the density, the higher the error rate.
Using Duplicacy, you’d be chopping up your audio files into chunks that need to be intact in order to reconstruct your music collection. If a chunk is damaged, any audio files referencing that particular chunk will be unrecoverable (at the very least not identical to the original). A single chunk could potentially be part of dozens, hundreds, or thousands of files.
Using rsync to back up your music collection:
Always a 1:1 ratio of files in your source and backup(s).
Backups and restores are generally faster because there’s no need to manage file chunks.
Every audio file is completely independent of the others in a backup. Disk corruption would only impact individual files and not necessarily groups of files.
Every FLAC file includes an embedded MD5 signature so it’s easy to verify file integrity (https://xiph.org/flac/features.html) independently of the backup tool. For DSD and DSF files, I would generate MD5 hashes for each file to help with detecting errors.
Can also use “rsync --checksum” to compare the source against the backup(s).
If your backup destinations don’t support rsync but do support SMB/CIFS, rsync can sync to a file share. Because your audio files aren’t subject to change much there’s already no savings from rsync’s delta-transfer algorithm – although “rsync --checksum” will be less efficient because it has to download a file locally in order to check it.
If your storage location isn’t on a file system with built-in file integrity checking (e.g., ZFS, Btrfs), you’d need to run “duplicacy check -files” regularly to scan for damaged chunks (CPU and I/O intensive). Otherwise there’s the risk of missing files in the backup(s) just when you need to recover from losing the source.
(Full disclosure: I’ve only been using Duplicacy for a few weeks, but have been following the project for about a year. I’ve used rsync for many years and the largest backup I’m currently managing is ~9TB consisting of 150+ million compressed files so I’ve had a chance to stumble through learning how to deal with relatively large backups. )
Thank you for these details. I also have a media library currently exceeding 13TB. Files vary from KB to 7GB. I use Duplcacy for all my backups except the media library, for that I am currently using rsync. I backup to a NAS and recently started rsync to a remote (off-site) NAS. It’s the remote NAS that has me thinking of using Duplicacy for the media library as I want it to be encrypted and I don’t want to move 13TB with every change in the library.
Using your suggestion I would set the chunk to the largest file size. Every file would amount to one chunk, unless I happened to have two identical files. This would result in my media library being encrypted to the NAS that Rsync would mirror on the remote NAS.
What is the maximum chunk size? I found with a 1GB chunk you get an error.
Might I suggest, instead of rsync or Duplicacy for large media files, to use rclone instead? It does encryption, supports cloud, local and sftp remotes, and can be mounted and decrypted on the fly. IMO, it’s the perfect companion to Duplicacy.
Just as an FYI, if your local NAS has support for per-file encrypted storage, it’d probably be much more efficient in combination with rsync than doing Duplicacy -> local NAS -> rsync -> off-site NAS because all of your music files are already compressed Duplicacy will be spending time compressing data that doesn’t really need it.
No, unless all of your files happen to be exactly the same size as a chunk, the ratio will never be one file per chunk because Duplicacy packs files into an archive before chunking, i.e., a chunk might contain parts of two or more files.
I took a look at the source code for Duplicacy and didn’t see a cap on the maximum chunk size. If I were to guess, the value you provided for the maximum chunk size might not have been a power of 2. For a 1GB chunk size, use 1073741824.

 )
)