Does this mean I should exclude db files (does anyone have a regex?) from all my backups and create a separate backup for those (possibly one for each repository)? Not very convenient…
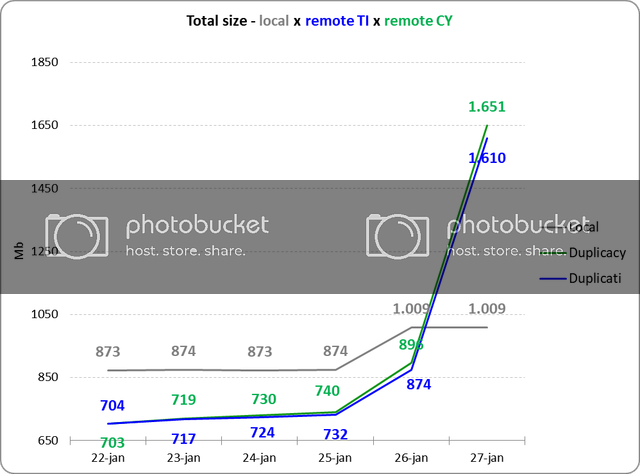
I think an average chunk size of 1M should be good enough for general cases. The decision of 4M was mostly due to the considerations to reduce the number of chunks (before 2.0.10 all the cloud storage used a flat chunk directory) and to reduce the overhead ratio (single thread uploading and downloading in version 1). Now that we have a nested chunk structure for all storages, and multi-threading support, it perhaps makes sense to change the default size to 1M. There is another use case where 1M did much better than 4M:
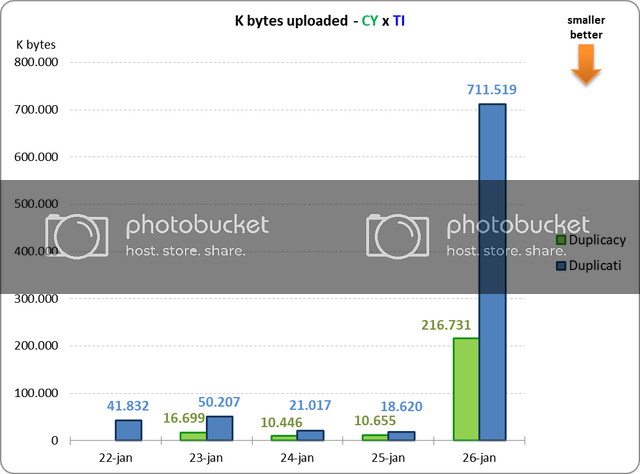
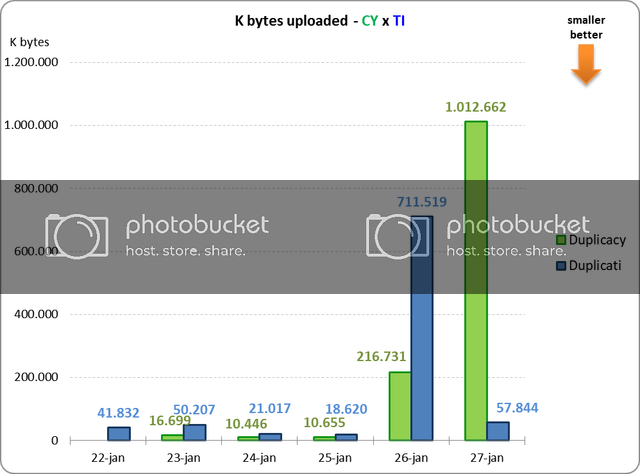
Duplicacy, however, was never to achieve the best deduplication ratio for a single repository. I knew from the beginning that by adopting a relatively large chunk size, we are going to lost the deduplication battle to competitors. But this is a tradeoff we have to make, because the main goal is the cross-client deduplication, which is completely worth the lose in deduplication efficiency on a single computer. For instance, suppose that you need to back up your Evernote database on two computers, then the storage saving brought by Duplicacy already outweighs the wasted space due to a much larger chunk size. Even if you don’t need to back up two computers, you can still benefit from this unique feature of Duplicacy – you can seed the initial backup on a computer with a faster internet connection, and then continue to run the regular backups on the computer with a slower connection.
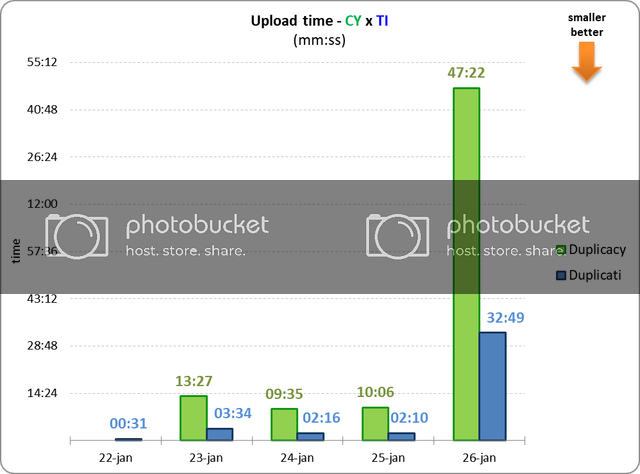
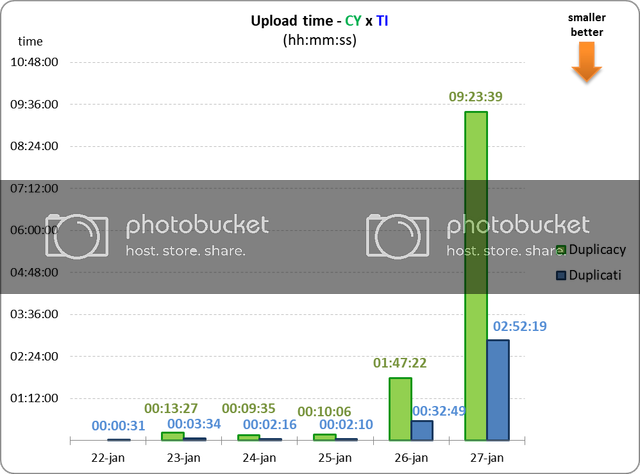
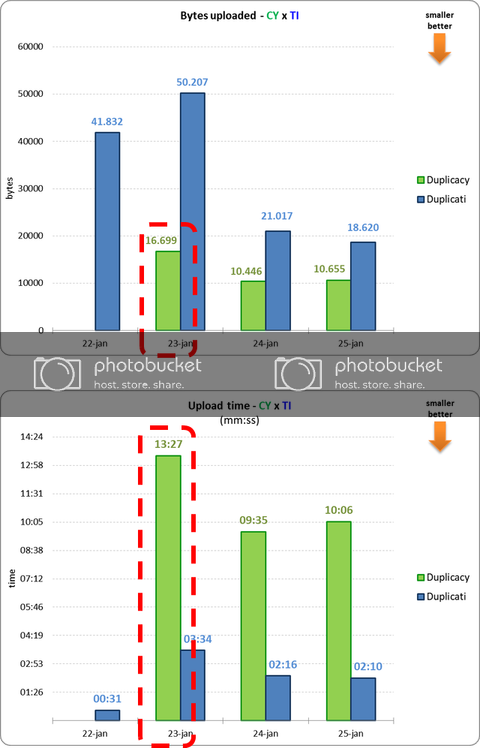
I also wanted to add that the variable-size chunking algorithm used by Duplicacy is actually more stable than the fixed-size chunking algorithm in Duplicati, even on a single computer. Fixed-size chunking is susceptible to deletions and insertions, so when a few bytes are added to or removed from a large file, all previously split chunks after the insertion/deletion point will be affected due to changed offsets, and as a result a new set of chunks must be created. Such files include dump files from databases and unzipped tarball files.