
That is actually 16,699K bytes.
Sorry, the graphs titles are wrong, I will correct them ASAP.
But the question remains: 1) How does the total size of Duplicacy backend grows faster if daily uploading is smaller (graph 1 x graph 2)?
I wonder if the variable-size chunking algorithm can do better for this kind of database rebuild.
But it has to support both situations: small daily changes and these kind of “rebuilds”.
Switching to variable chunks will not make us to return to the beginning of the tests?

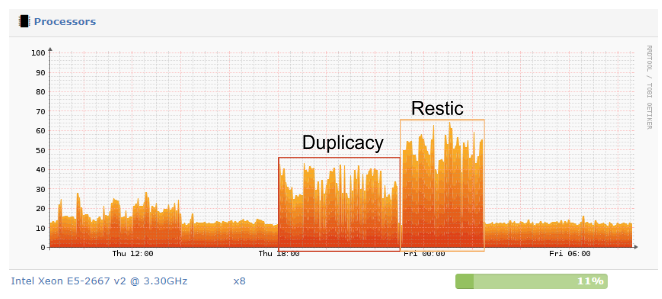
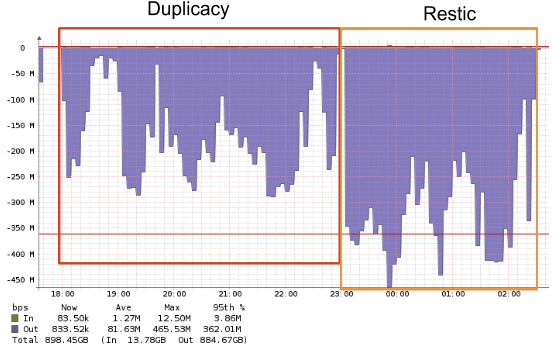
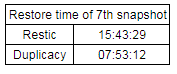
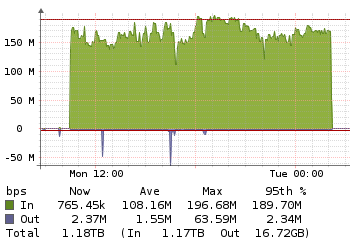
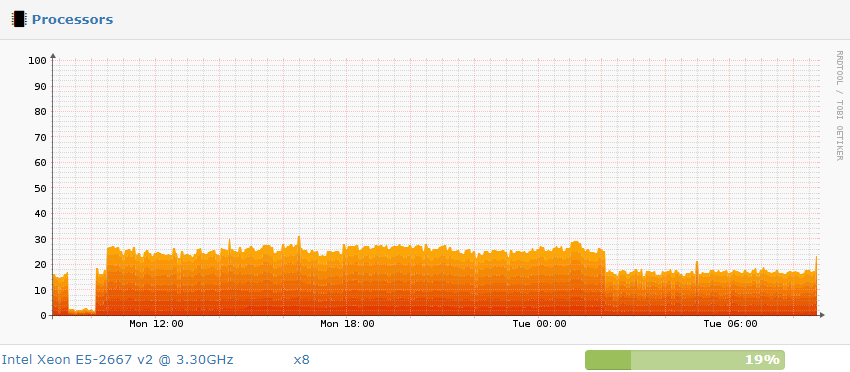
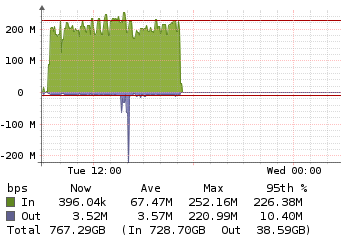
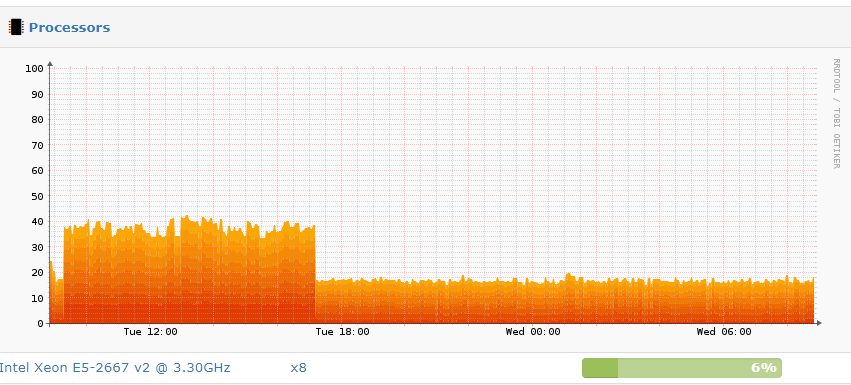
 Such as half the restore time, lock free dedup and lower backup sizes.
Such as half the restore time, lock free dedup and lower backup sizes.