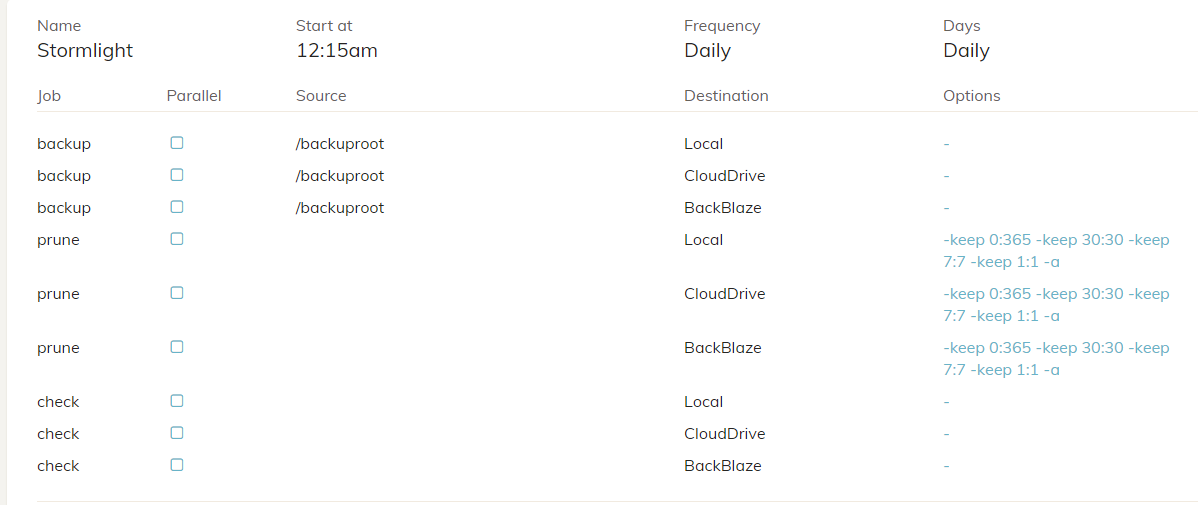
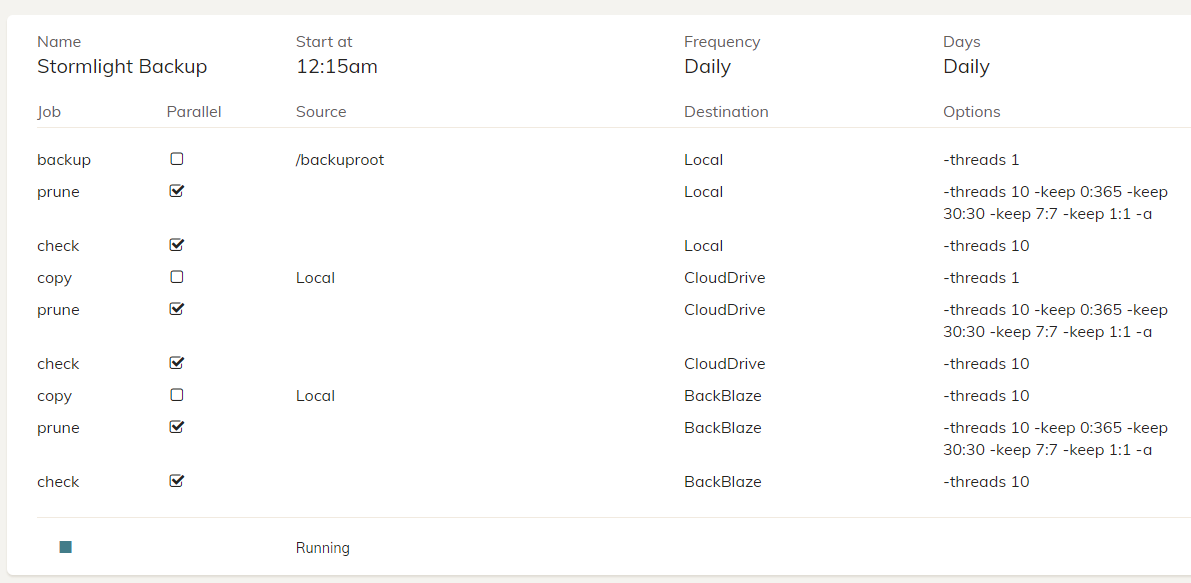
I just recently started looking into Duplicacy, and I think it could be a very viable option. I was just trying to make sure I understand how the software is working compared to something I was using before: Acronis TrueImage Home.
In Acronis, I had set up a backup policy that would create a full backup, do 6 incremental backups, then start a new chain (full + 6 increments). I could then specify how many “chains” of backups I wanted to retain. On the other hand, if I used their cloud storage, it would do an initial full backup, then every subsequent backup would just be an incremental one.
Is the way Duplicacy working similar to the Acronis Cloud Backup policy I mentioned above (one full, all subsequent as increments)? While efficient, I was always concerned that if any backup (link in the chain) ended up corrupted, then all further backups down that chain would become useless. Is that a possibility with the way Duplicacy does backups, or am I misunderstanding something?
If that is indeed both how it functions and a possible risk (even if it is remote), is there a way to schedule a “restart” of the chain, i.e. a full backup? I set up the default pruning retention policy on the web page (-keep 0:1800 -keep 7:30 -keep 1:7 -a), but are these applying just to the incremental portions? I guess my difficulty/confusion is seeing how the concept of full/increment/chains are translating to Duplicacy terminology. Not sure if revisions and snapshots are the same thing.