
I have the following purge schedule set to run daily :
-keep 0:365 -keep 30:30 -keep 7:7 -keep 1:1
As far as i understand, this should 
keep a daily backup up to 7 days,
Keep 1 snapshot every 7 days for anything older than 7 days
Keep 1 snapshot every 30 days for anything older than 30 days
Keep nothing once it’s over 365 days…
But… when i go to restore i seem to have options going back daily for much longer than 7 days :

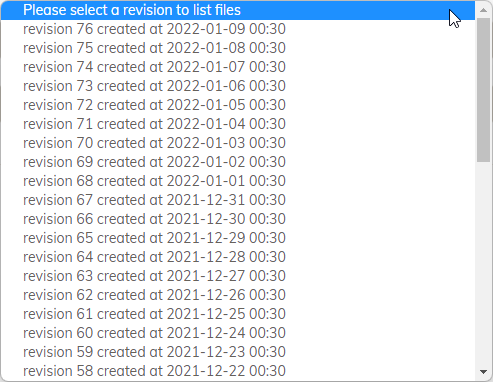
What am i doing wrong here?
The log for the job shows the below… which as far as i can tell is just plain wrong :
2022-01-09 08:00:36.821 INFO RETENTION_POLICY Keep no snapshots older than 365 days
2022-01-09 08:00:36.822 INFO RETENTION_POLICY Keep 1 snapshot every 30 day(s) if older than 30 day(s)
2022-01-09 08:00:36.822 INFO RETENTION_POLICY Keep 1 snapshot every 7 day(s) if older than 7 day(s)
2022-01-09 08:00:36.822 INFO RETENTION_POLICY Keep 1 snapshot every 1 day(s) if older than 1 day(s)
2022-01-09 08:00:37.394 INFO SNAPSHOT_NONE No snapshot to delete