
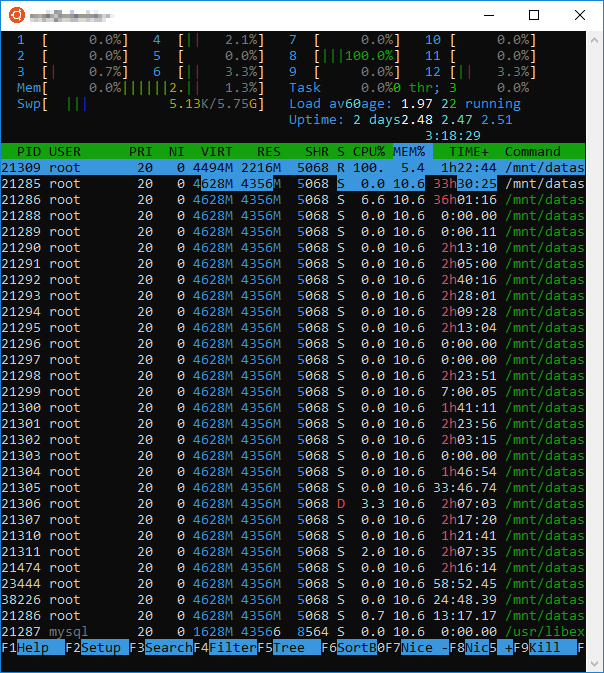
So according to my task manager, duplicacy seems to be using all of my memory and then some. There are 28 processes running, each at 4.6 GB each for a total of about 128 GB/ over 300% of my memory (40 GB). Only 1-2 processes and cores ever seem to be in use at a time (I guess since most time is spent chunking and this is single threaded). I have it set to 8 threads and to write to a log file. It’s about 8 TB of data.
I found the post about the DUPLICACY_ATTRIBUTE_THRESHOLD. Should I really set this to 1 or try to find a sweet spot. I don’t want to thrash the disk with a ton of individual reads in the main loop since the OS seems to be handling memory management and staying performant.
I’m just a little surprised at the moment and wonder if there is something more going on than a static 1 million attributes, unless they are loaded per process… not to mention I just moved this all over from a Windows machine and it only had 12 GB of memory. Also, why are there 28 processes? Are they all spun up and pending in a queue?
My questions are scattered, but I’m just looking for advice and an understanding of the software.
RELATED POSTS: