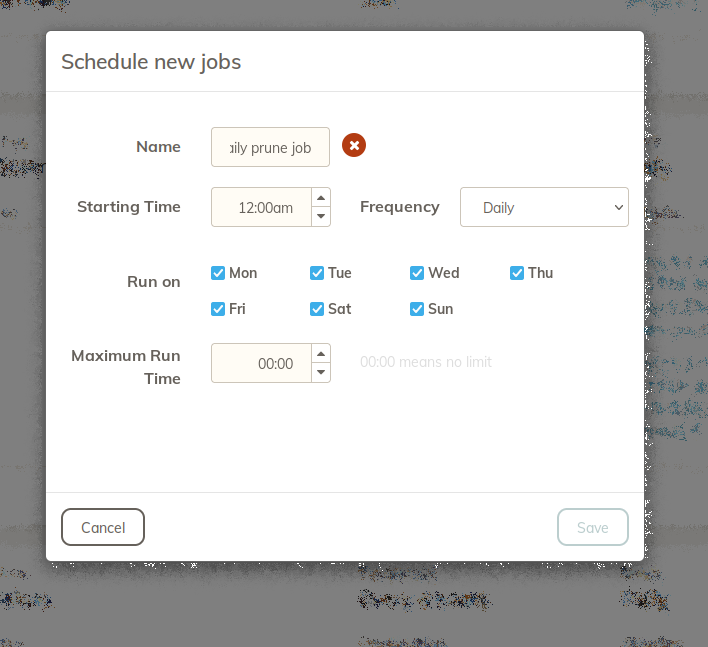
If there are too little fields for your retention policy, just click safe and modify the command line options afterwards by clicking on it:
-keep 1:7 -keep 7:62 -keep 30:730 -keep 365:1460 -keep 0:3650 -id my_backup_one -threads 4
This would delete the snapshots in the same manner like mentioned before, but only with the given id of your backup. You can omit -id my_backup_one and add an -all if you like to have it apply the retention policy on “all” backups. 
Here’s the full help:
$ duplicacy prune --help
NAME:
duplicacy prune - Prune snapshots by revision, tag, or retention policy
USAGE:
duplicacy prune [command options]
OPTIONS:
-id <snapshot id> delete snapshots with the specified id instead of the default one
-all, -a match against all snapshot IDs
-r <revision> [+] delete snapshots with the specified revisions
-t <tag> [+] delete snapshots with the specified tags
-keep <n:m> [+] keep 1 snapshot every n days for snapshots older than m days
-exhaustive remove all unreferenced chunks (not just those referenced by deleted snapshots)
-exclusive assume exclusive access to the storage (disable two-step fossil collection)
-dry-run, -d show what would have been deleted
-delete-only delete fossils previously collected (if deletable) and don't collect fossils
-collect-only identify and collect fossils, but don't delete fossils previously collected
-ignore <id> [+] ignore snapshots with the specified id when deciding if fossils can be deleted
-storage <storage name> prune snapshots from the specified storage
-threads <n> number of threads used to prune unreferenced chunks