
I’ve been running from the CLI. I would like to migrate to the webui. Is this possible? it seems as if it wants to setup a new backup at my b2 bucket.
See here:
Thanks. I had seen that, but it wasn’t clear if this was still the case. If I understand correctly, there is no current migration path?
1 Like
@Chris currently you can’t directly import a repository running the CLI into the web edition. You’ll need to create a new storage and then a new backup to that storage. However, when you run the backup in the web edition it will pick up where it was in the CLI.
1 Like
Oh ok. Thanks! The id should be different, correct? ie instead of mycomputer, I’d use mycomputer-web or similar?
1 Like
Did you figure this out? How did you do it?
@gchen, could you elaborate a bit on what you mean by this:
You should use the same id, but even if you don’t, the new backup from the web GUI should be relatively fast since most chunks should already be in the storage.
To select the same id, when you at this step to add a new backup:
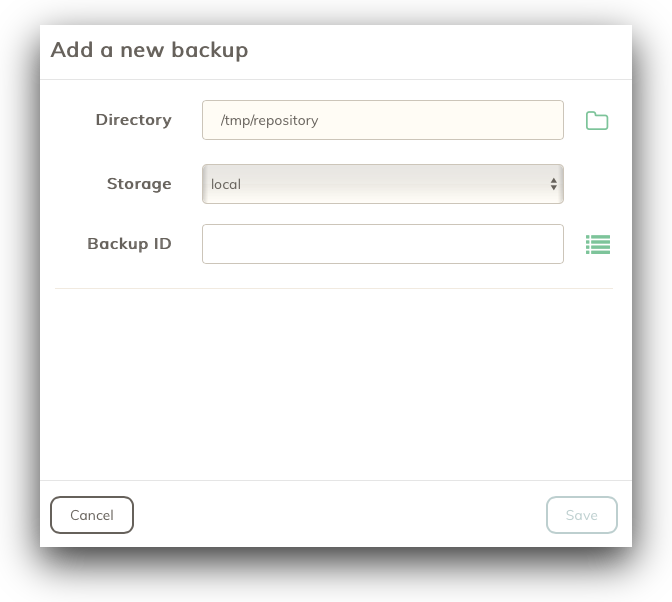
Click the icon next to the Bakup ID input field, and you can then select the old id from the list of existing ids in the storage.
1 Like
Given that I have a functioning backup-process based on the CLI and scripts, I’d like to not change that running system but I’d like to use the web-ui to visualize backup size etc.
So I’d install the web-ui, create new backups with the same IDs as my existing ones as described above but not schedule any backups in the ui and I should nonetheless see my backup statistics in the web-ui, right?
You don’t need to create new backups. Just add the storage and schedule a daily check job. You’ll then see the nice graphs in a few days.
2 Likes
FWIW: I was confused by this step:
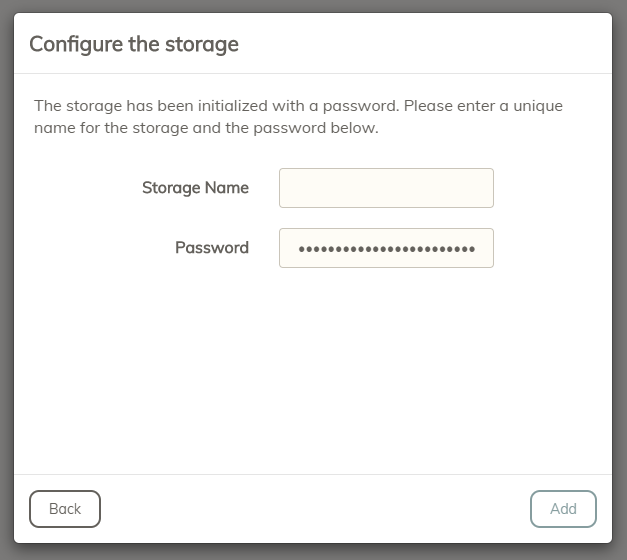
Which password is being asked for is clear. But Storage Name? First, I thought it might be the snapshot ID, but that didn’t make sense since I’m just connecting a storage, regardless of which repositories use it. So I eventually figured it was the optional storage name in the init command. But if my storage is called “default” because I did not use any name at first initialization, does that mean I should enter “default” here? Or does it matter at all what I enter here (when I’m trying to connect my existing CLI storage)?
I ended up putting the storage provider as the storage name (which I didn’t do previously). I’m running a check now and it is “listing all chunks” so I guess it’s working. But I wanted to mention here that the UX could be improved here.
1 Like