
Hello, I’m a bit confused with how recovering from a Missing Chunks error is performed. I’ve been browsing around the form and have also read Fix missing chunks. There was also mention about changing the ID of a repository?
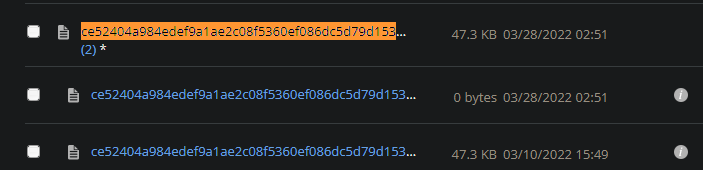
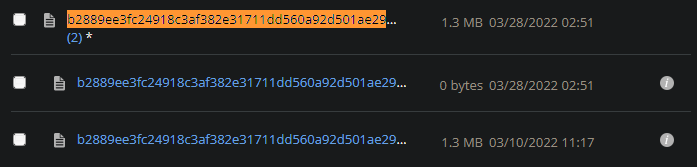
When I tried locating the some of the files it shows duplicates, one with a file size of 0 and the other with varying file sizes. Would deleting those 0 size files resolve the error? And Im not sure if it’d be practical deleting them manually as there are 100+ of these missing chunks.
I have 3 backup locations; a local NAS, Wasabi, and B2. The Missing Chunks are only occurring on my B2 bucket.
Daily Storage Check Schedule:
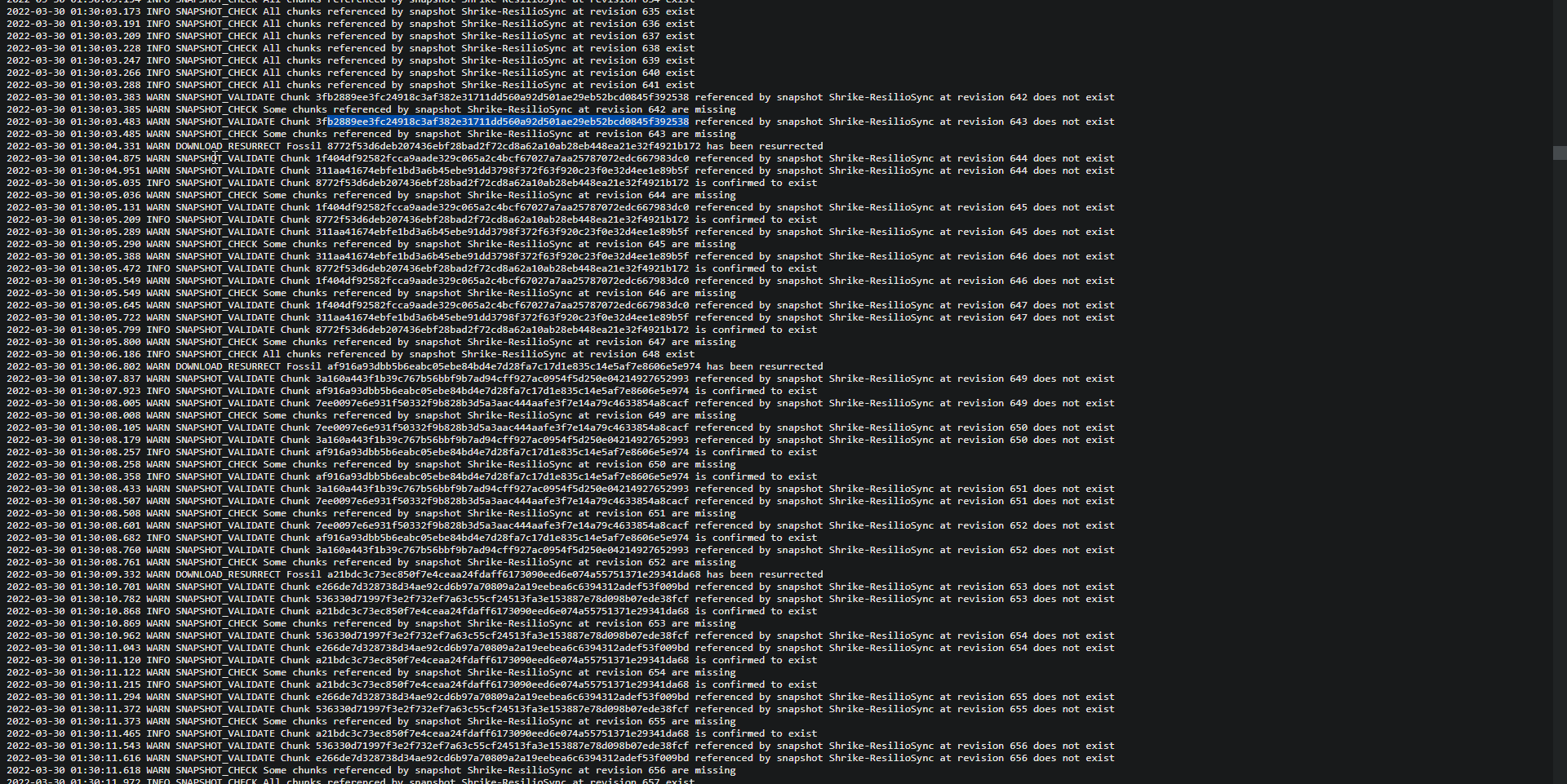
This is from the B2 check log:
Here are a couple of those duplicates:
This is my entire Schedule:
