
I’ve got a setup that uses multiple storage pools and different pruning policies among them. I’ll describe the storage and desired outcome first, then what I see in my logs.
Laptops and a server back up to a storage pool on a server at home. Laptops perform backup and a very basic check, the server performs pruning, copying, checking, and a weekly more in-depth check. The initial backups target “pool0” on the server. Once a day the server performs a copy and check from pool0 to pool1, then a copy and check from pool1 to a pool stored on backblaze for off-site storage.
The desired retention period on pool0 is -keep 0:366 -keep 7:90 -keep 1:15 -a . So, every backup until 15 days, then 1 backup per day over 15 days, then 1 backup per week over 90 days, and after 366 days revisions should be dropped.
On pool1, the copy target for pool0, I want retention to be -keep 0:2922 -keep 90:730 -keep 30:180 -keep 7:35 -keep 1:1. So all backups until a day, then 1 backup per day older than 1 day, 1 backup per week over 35 days, 1 backup per month-ish over 180 days, 1 backup per 90 days (quarter) over 730 days, and finally after 8 years revisions should be dropped.
Finally, on backblaze I want the prune policy to match pool1. These storage targets are meant to be longer term destinations, copied here at home and duplicated off site for disaster preparedness. The pool1 storage is meant to keep pool0 more free for user storage space, since pool0 is faster drives with mixed use as a NAS and a few other things.
From Back up to multiple storages I saw
If onsite pruning is more aggressive than offsite pruning, this would work (but is not a great idea).
I’m wondering if I can get clarification on what this means? Because I’m certainly getting messages in my prune logs that are confusing, but perhaps expected? For instance, after a copy from pool0 to pool1, the prune task runs and I get a bunch of messages like this:
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5448 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5983 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5987 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5991 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5995 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 5999 should have been deleted already
2023-09-21 00:37:28.445 INFO FOSSIL_GHOSTSNAPSHOT Snapshot rhodes_home revision 6003 should have been deleted already
If I launch the restore selector from pool1, I don’t see these revision numbers because the prune has run and it presumably deletes them. My guess is that these are being copied from the pool0 source every time the copy runs, and the prune step in my schedule just immediately deletes the copied snapshots? My concern is what happens on the inverse end of the spectrum? The copy isn’t deleting anything, so as long as my prune rules are in effect, snapshots, chunks, and the revisions they contain should all remain on my pool1 storage right? I might get some odd messages in the logs, but nothing should be too crazy?
What happens when those snapshots are out on pool0 though? They’ll already exist in pool1, but will pool0 also continue to contain them if I run a check job that resurrects data? I assume pool0 has no knowledge of what’s on pool1 so it shouldn’t make any difference whatsoever? But what about chunks that change, how might this impact the pool1 data?
Finally, the copy from pool1 to backblaze is just a copy and the prune should be pretty straight forward. I’m assuming it shouldn’t complain about fossil ghost snapshots because it’ll just be following from the last copy out of pool1 where that error has presumably been cleared up already? Again, the purpose of this destination is to keep an off site copy of data in the event that the worst happens.
I’ve attached my schedule page to better show what the server’s activity looks like. As I said, the laptops simply back up to the same pool0 target storage, so there isn’t much to see there.
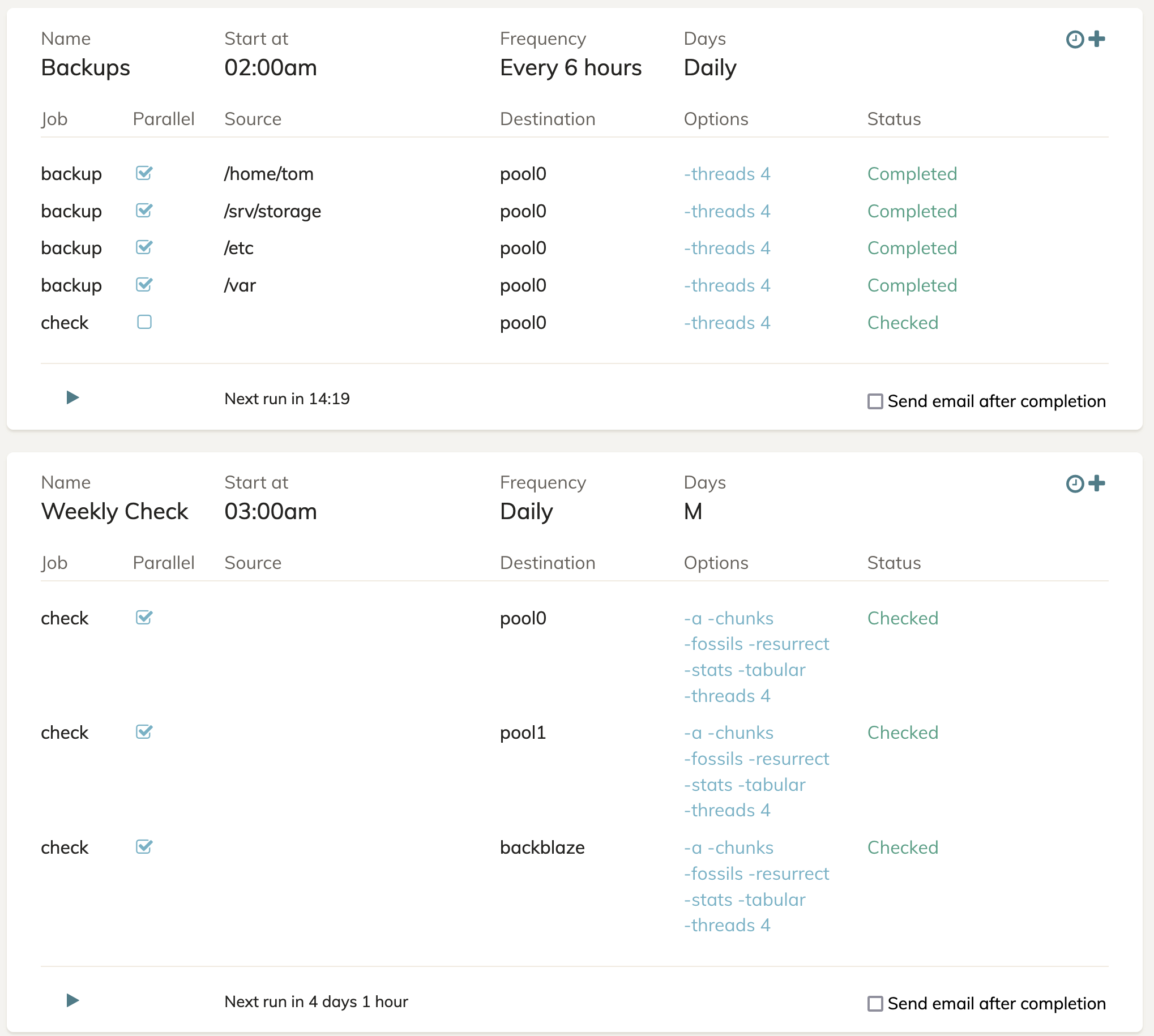
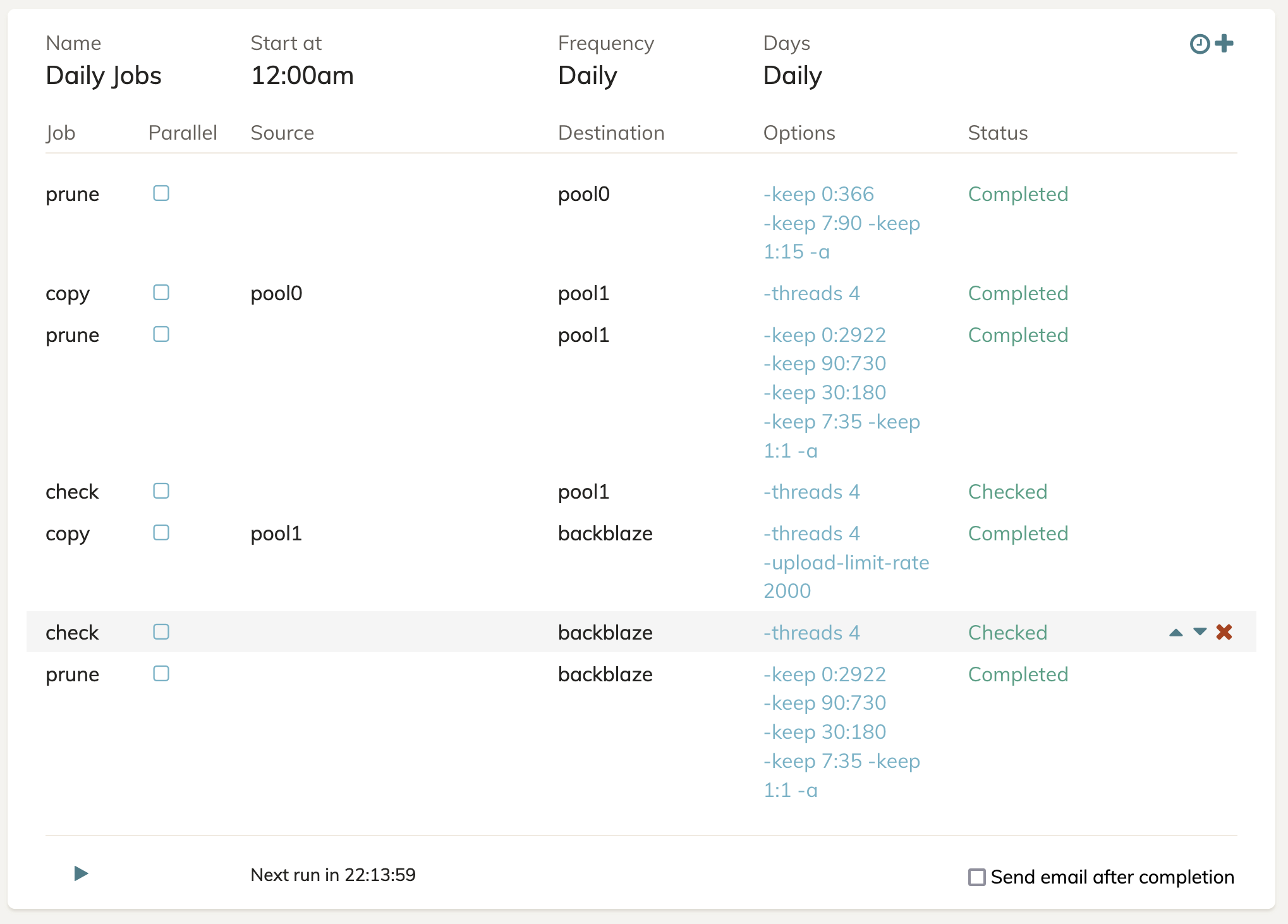
If someone could look over this and just verify it makes sense somewhat. I’m trying to keep generations of data with different retention policies. The policy and copying make sense in my head, I think, and I believe I understand why the app is complaining about snapshots that appear but the prune believes shouldn’t exist. But I want to make sure I’m not doing an extreme anti-pattern here and causing potential corruption. There’s a couple TB of data being backed up, so I want to make sure I’m handling it properly and checking it regularly.