
Sure thing! I’m glad you got it working.
1 Like
If you had to create a filters file with includes, then there likely was a link loop.
In Windows there are actually three types of links: hard links, soft links (aka., “junctions”) and symbolic links. They behave differently and also have different constraints.
I didn’t - i work with the Web UI
I had to follow the tip of the comrad above me - of adding each of the path components (of each of the paths) to the includes
To me this seems a bit redundant, seems to me like there must be a simpler way to make a backup scheme that spans multiple drives than this non-straightforward adventure
There also most definitely is no loop, since the “root” folder is on C, but the only thing i include from C is “my documents” basically which is in a totally different place.
How is the difference between them relevant to Duplicacy? I found a post in this forum suggesting to use a symlink and this thread suggested to use a junction… so which is it?
That’s fine. Under the hood it works the same way. The Web UI saves the filter rules to a file so that the CLI can use it during the backups.
This is the part that makes me think there’s a link loop. I created a folder layout just as you and @Compeek described and couldn’t replicate the problem you two had. Duplicacy had no issues backing up without any filter rules involved.
The part I’m unsure of is if your concept of “backup scheme that spans multiple drives” is the same as mine. 
Do you mean you want to back up multiple unrelated drives using only a single backup configuration to a single shared target destination?
If you don’t mind sharing, what was the exact command used when creating the soft links?
And was your final repository layout something like this?..
C:\Root
C:\Root\C
C:\Root\D
From Duplicacy’s (CLI and Web Edition) point of view, all three types are just links (more on this in a moment). Duplicacy follows – “dereferences” – links only in the root of a repository. All subsequent links found below the root are backed up as-is – i.e., during a restore they are recreated as links.
So, which link type to use? – It all depends on the use case and environment. Under the hood each link type is treated differently by Windows. There are also restrictions depending on the version of Windows, but for the sake of our sanity we’ll assume the minimum is Windows 7:
-
If you have Administrator privileges on the computer all three can be used (by default, only Administrators can create symbolic links).
-
Hard links are analogous to a piece of pipe. Just as a pipe cannot directly link to an object that’s separated by a solid wall, a hard link cannot span drives (e.g., link
C:\link.txttoD:\file.txt), can only be used for files, and a target file must already exist. -
Soft links, aka. “junctions”, are almost the opposite of hard links. They can span drives (like a piece of string winding around a wall), link only to folders, and a target folder doesn’t have to exist.
-
Symbolic links were a newer addition in NTFS. They work pretty much like they do on Unix/Linux, linking to files and/or folders that span drives, but one big difference is that Windows allows the target to be a UNC – e.g.,
MKLINK /D C:\Music \\192.168.1.2\Music.
Whether it’s soft links or symbolic links, if one or more drives are external (like the scenario that the OP asked about), I wouldn’t recommend using drive letters for the links if there are going to be multiple external drives.
1 Like
I can give you my exact scenario without revealing any personal data. Assuming my drives are “X”, “Y” and “Z” i have:
- X:\cool
- Y:\awesome1
- Y:\awesome2
- Y:\awesome3
- Z:\go\deep\into\subfolder1
- Z:\go\deep\into\subfolder2
- Z:\go\deep\into\subfolder3
As the raw locations that i wish to backup under a singular backup plan
that’s it
the “root” folder itself is in:
- Z:\root
Which is exactly why there’s nothing circular here
By the way, the official documentation of Duplicacy explicitly states you must include all the components of the path as well
In fact, let me quote it:
Patterns ending with “*” and “?”, however, apply to both directories and files. When a directory is excluded, all files and subdirectories under it will also be excluded. Therefore, to include a subdirectory, all parent directories must be explicitly included.
You can find this doc in the link shared above by our other comrad
My repository itself was based in root (at least that’s how it appears from the Web UI) - so that all the include paths were relative to root, and not phrased in absolute terms.
So the include paths were actually (i had to add spaces for this to render correctly):
- X\Cool \ *
For example, rather then
- X:\Cool \ *
Sure, i went back and forth between symlink and junction trying to make this work - i just went to check and at the moment it seems like it’s a symlink
So the command i used is:
mklink /D Z:\root\X X:
mklink /D Z:\root\Y Y:
mklink /D Z:\root\Z Z:\
None of the drives are external, these are 3 internal HDD’s - one of them the main one on which the OS itself is installed (and also happens to host the “root” of the repository)
Yes.
What does it matter if my data is spread across different folders or different drives?
For the software these are all just locations to access and pour into the backup, right?
Why not imagine that my entire computer is one big “virtual” root and that my different “drives” are actually folders who happen to have one letter names?
Why is it important to give special status to the physical drives when choosing sources for backup?
The reason i want my backups to span multiple drives is that I organize them by importance (and by how many copies of the data in how many destinations i want them to have) — not by their original location, which to me is completely arbitrary
I ran out of space on “Y” so i bought another HDD and named it “Z” -
but they both might contain videos that I want to backup under the same plan
I don’t want to have more backup plans just because i have multiple drives
Got it. My setup is similar with multiple drives under a single Duplicacy repository and backup configuration. The storage destination is also shared by multiple hosts (around a dozen bare metal and virtual machines).
Agreed, so far so good…
Yes, the quote above is true, but the rule only applies when a filter explicitly excludes a directory.
@Compeek 's filter file posted earlier ends with -*, which effectively blanket excludes everything under the repository root, so the only way to counteract it is to explicitly include files and/or subdirectories that are to be added to the backups.
Here’s an example… let’s assume we’re going to back up the C: drive and it’s the root of a Duplicacy repository:
C:\
Within C:\ there’s just a single folder and two files:
C:\Music\song.mp3
C:\playlist.m3u
Without a backup filter, Duplicacy will grab both C:\Music\song.mp3 and C:\playlist.m3u.
But now let’s assume that we add a backup filter with just a single rule:
-*
(The pattern above translates to “exclude everything”.)
If we run a backup, Duplicacy will walk the filesystem matching what it finds against our filter. Because our filter matches everything, and we’re telling Duplicacy to exclude all matches, there will be nothing to back up.
So in order to capture both files, we need to explicitly countermand the blanket exclude:
+playlist.m3u
-*
In the revised filter above, C:\Music\song.mp3 will still be ignored because it still matches the blanket -* pattern so we also have to explicitly include it (note that path separators in the filter patterns are always forward slashes, i.e. ‘/’, regardless of the host operating system):
+Music/song.mp3
+playlist.m3u
-*
However, song.mp3 is again still ignored because the blanket -* pattern prevents Duplicacy from descending into C:\Music. What we also need is to tell Duplicacy it’s okay to search the C:\Music folder:
+Music/
+Music/song.mp3
+playlist.m3u
-*
Of course, the example above is an extreme case because the backup results with and without the filter file are identical, making the filter file unnecessary.
Yep, same starting point for both the CLI and web UI.
Yes, it’s because the filter is referencing the syminks rather than the abstract drive letters Windows assigns and all the paths are relative to the repository root (Z:\root).
(Windows tip: The command DIR /A:L Z:\ lists the junctions and symbolic links contained in the specified folder, including each link type found.)
hmmm… so… Z:\root contains a symlink named ‘Z’ (Z:\root\Z) that points to Z:\, and within Z:\ is a subdirectory named ‘root’ (Z:\root) which contains a symlink named ‘Z’ (Z:\root\Z) that points to Z:\, and within Z:\ is a subdirectory named ‘root’ (Z:\root) which contains a symlink named ‘Z’ (Z:\root\Z) that points to Z:\, and within Z:\ is a subdirectory named ‘root’ (Z:\root) which contains a symlink named ‘Z’… [channeling William Shakespeare]… methinks thou doth have a link loop.
Try the following little experiment…
- Find a spare USB flash drive that can be reformatted.
- Reformat it with a NTFS filesystem (I’ll assume the drive letter is
F:, but adjust accordingly). - Add a folder named “root” (
F:\root\). - Add a link that points to
F:\using the following command:mklink /J F:\root\F F:\
You now have a linkF:\root\Fjust like in your example above (Z:\root\Z). - Finally,
cd F:\root\and issue thetreecommand.
How many levels deep does the tree output go? 
That’s good. It’s less risky than shuffling external drives but still subject to quirks in Windows. As you already know, drive letters in Windows are generally assigned in alphabetical order starting with C (for historical reasons). A drive letter can be assigned to a volume, but it’s not permanent. If a drive is temporarily disconnected and a new one is added the new drive will claim the freed up drive letter.
So the longer term solution is to refer to the GUID of a volume (similar to what Linux systems do). There’s more than one way to find out what the GUID is for a formatted volume, but the quickest the command fsutuil volume list which lists the GUIDs for all attached volumes (including any USB drives):
C:\>fsutil volume list
Possible volumes and current mount points are:
\\?\Volume{6651cade-a3f8-11ec-876e-d89ef3105a25}\
C:\
In the example above, 6651cade-a3f8-11ec-876e-d89ef3105a25 is the GUID for the formatted volume, and the UNC \\?\Volume{6651cade-a3f8-11ec-876e-d89ef3105a25}\ refers to the formatted volume that’s currently assigned the drive letter C:.
To create a junction/soft link…
MKLINK /J Z:\root\C \\?\Volume{6651cade-a3f8-11ec-876e-d89ef3105a25}\
… or a symbolic link:
MKLINK /D Z:\root\C \\?\Volume{6651cade-a3f8-11ec-876e-d89ef3105a25}\
The major advantage is that the GUID is drive letter agnostic. It remains the same for the life of the volume until it’s reformatted.
Let’s assume we’ve got a junction/symlink currently pointing to a Kingston USB flash drive and Windows assigns it the drive letter K:. If we eject it → plug in a mix of other different USB drives (and one of them claims the drive letter K: that the Kingston flash drive was using seconds ago) → then reinsert the Kingston flash drive and it’s now assigned the drive letter U:, the junction/symlink will still point to the Kingston USB flash drive even if we daisy chain five new USB hubs before plugging the flash drive into a random port on the last hub.
It also means things aren’t limited by the 26 letters of the English alphabet (nowadays with HDD, SSD, NVMe, USB, drive partitions, etc. it’s quite possible to exceed 26 volumes). Your junctions/symlinks can even be more descriptive and could include external drives that aren’t always plugged in:
MKLINK /J Z:\root\Kingston_USB_flash_drive \\?\Volume{6651cade-a3f8-11ec-876e-d89ef3105a25}\
Got it. My setup isn’t all that different from yours, including what you described in your updated post.
While it’d be a pain to re-rip and re-curate hundreds of music CDs I’ve got safely packed away in totes, they’re part of my “3-2-1 backup” (lossless compression in FLAC format followed by MP3/OGG files depending on the playback device).
It doesn’t, and Duplicacy doesn’t care either. It’s just a matter of pointing Duplicacy in the right direction.
Yep. Mix and match to heart’s content.
That “virtual” root can also contain links/maps to remote storage. As long as Duplicacy sees a filesystem it can access, the sky’s the limit.
One of my servers, for legacy reasons, is running RHEL 4 (circa February 2005). The hardware is almost 13 years old and the 32-bit OS is too ancient to run even Duplicacy (as portable as Go apps typically are, they still rely on the OS).
So in a VM running CentOS 8, I’ve got a directory (/mnt/RHEL4) mounted via SFTP (sshfs module for FUSE) to / on the RHEL 4 server which Duplicacy happily crawls without nary a complaint.
Duplicacy doesn’t give special status to physical drives – any accessible path to a filesystem is perfectly fine with Duplicacy.
One of my Linux machines has 5 SATA drives + 1 eSATA drive dock + 2 USB HDDs + an evolving collection of high-capacity USB flash drives. I’ve got a set of small weather-resistant plastic ammo cases used for storing bare HDDs and SSDs that are occasionally plugged into the eSATA dock. Everything is mapped to /media and then selected directories are bind mounted read-only to /srv/Duplicacy.
If needed, in a pinch I could easily add a directory from a remote server that accepts nothing but FTP connections and is only accessible over a VPN passing thru a SpaceX Starlink satellite before it relays through a smartphone used as a Wi-Fi hotspot by a laptop in a tent in the middle of Yosemite National Park. 
It makes zero difference to Duplicacy and is all under a single backup plan. I also use Duplicacy’s tagging feature to label snapshot revisions so I can easily identify backups that were done by automated backup, triggered manually, special revisions that are to be preserved, etc.
So the issue isn’t Duplicacy, it’s with Microsoft Windows relying on drive letter assignments.
according to the docs, if the pattern has only include statements, it would effectively exclude everything else, which is my working hypothesis as to why it behaves as if i had the same rule as our comrad
right, but why do we have to engineer all these symlinks etc. ? why not just have the software allow us to pick the drives we want?
When i select folders to sync in “Google Drive” i don’t go around creating “fake folders” or symlinks — even if those folders happen to span multiple drives
…but it does.
I cannot select folders from multiple drives without this symlink trick.
yet i can select any folders i want from the same drive (without symlinks).
Hence the different treatment.
Sure but any other kind of software that functions inside windows and allows to pick folders across multiple drives, doesn’t have this problem.
That would be like going to Britain, driving on the wrong side of the road, and then saying that the British history of transportation is the problem.
Well, maybe — but if you want to drive in Britain, you better get adapted to how it works.
Similarly, if you choose to work in Windows, you need to take into account that it might work differently than linux.
As i said, no one could suspect that Google is Microsoft’s “ally” in any way, yet its “Google Drive” program effortlessly copes with folders across multiple drives, whether they have “letters” or not - in Windows.
That is of course not a loop in practice, because I don’t actually try to backup Z:\ or Z:\root themselves.
It’s true that Z:\root itself contains a loop, since it points to the same drive the “root” is contained in,
but as long as i’m not trying to back up Z:\ itself or Z:\root itself — what is the problem?
there’s no loop in my declared backup source –
I tell it to go directly to:
Z:\root\Z\potato
and back it up to some destination.
at no point should it ever try to go and “discover” or “run into” Z:\root itself on its way to “Z:\root\Z\potato”
i.e. - the path:
Z:\root\Z\root
For example, should never come up - since i don’t try to back up root itself
I am telling it where to go inside “Z:\root\Z” - and that is: “Z:\root\Z\potato” - a path that contains no loops.
Anyway, if the loop was the problem, why would adding the intermediate paths solve the problem?
Add -d as a global option to the backup job. Then you’ll see in the log why the directories pointed to by the junctions are not included.
1 Like
@gchen as expected, this is what my test yielded:
2022-09-02 15:56:04.644 DEBUG LIST_ENTRIES Listing
2022-09-02 15:56:04.644 DEBUG PATTERN_EXCLUDE Z is excluded
2022-09-02 15:56:04.644 DEBUG PATTERN_EXCLUDE Y is excluded
2022-09-02 15:56:04.644 DEBUG PATTERN_EXCLUDE X is excluded
2022-09-02 15:56:04.644 ERROR SNAPSHOT_EMPTY No files under the repository to be backed up
No files under the repository to be backed up
My test pattern contained a single include entry for a folder in “Z” that is 3 “layers” deep, e.g.:
Z:\my\cool\sub\folder
After some more testing I discovered what I already know by now - that for this folder to be included I have to add:
+Z\my\cool\sub\
+Z\my\cool\
+Z\my\
+Z\
+Z
to the list of includes
Talk about redundancy…
Relevant discussion
@saspus Doesn’t seem like any headway was made there toward a solution 
I think it’s perfectly fine to support complex regex-based, rule based or voodoo based filteration,
but the most basic case is that of simple inclusion and exclusion of specified folders, across drives – that would (i would venture a guess here) probably cover 95% of actual use-cases in the wild.
in fact, the most basic case doesn’t even involve exclusions (Google Drive for example doesn’t have them, nor does Acronis iirc) - that is - imho - a “bonus” feature,
So way-to-go duplicacy for having exclusions unlike most software, but nay for not supporting multi-drive backup plans out of the box, or even - for that matter, deeply nested folder selections without complex (and truly redundant) manual configurations
1 Like
Technically multi-drive backup is supported via first level symlinks; not ideal — but it’s something.
But I agree, simple file inclusion and exclusion is a very basic requirement that has benefit of being
- Simple to understand, and therefore used successfully
- Sufficient for most users.
And therefore should be a no-brainer to support.
Then there is the whole separate discussion on merits of having dedicated standalone exclusion list in the first place: it will always require maintenance as more data is written to disk, it’s not portable, and just a hassle.
The alternative is to keep metadata (“don’t backup” flag) close to data; for example, applications that create temporary files is in the best position to mark that file for exclusion. This approach is used on macOS where a special extended attribute is used to exclude files from backup. Duplicacy supports it. Now my exclusion list is empty. And it “just works”.
Windows does not have that standard way of excluding files. But IIRC Duplicacy supports a special .nobackup file that can be placed in folders that need to be excluded. This may be an alternative to managing the unwieldy list.
I would say it’s more of a workaround than a “support”, I had to basically engineer my OS/Filesystem in a way to cheat the program into thinking that something that isn’t a folder (but a drive) - is a folder
The entire reason someone would pay and use a GUI version of the software is because they don’t want to deal with CLI’s (let alone OS-level CLI commands)
Both things (drives and simple inclusion/exclusion) need to be fixed, in my eyes, since both of them require a lot of manual, error-prone labor that is (or should be) simply unnecessary for the software to fulfill its most fundamental role: select a bunch of sources (regardless of where they are), select a destination, and backup from A to B
1 Like
I’ve reread your earlier posts multiple times on this thread and the other (Best practice for single NAS + Cloud backup?). I thought I had a good grasp of what you’re looking for, but perhaps I still don’t.
(The screenshots below are of Windows 7 + Duplicacy Web Edition 1.6.3 + Google Drive + Firefox on a virtual machine I created to mimic the example host system you described earlier.)
First up, Windows Explorer showing 4 internal drives (C:, X:, Y: and Z:) plus 1 virtual drive provided by Google Drive (G:). Nothing special about the Windows installation which is entirely on C:…
Next up, accessing Duplicacy’s web interface. Dashboard panel…
Storage configuration panel with a single target destination. As a twist, it’s pointing to the virtual drive (G:) provided by the Google Drive desktop client…
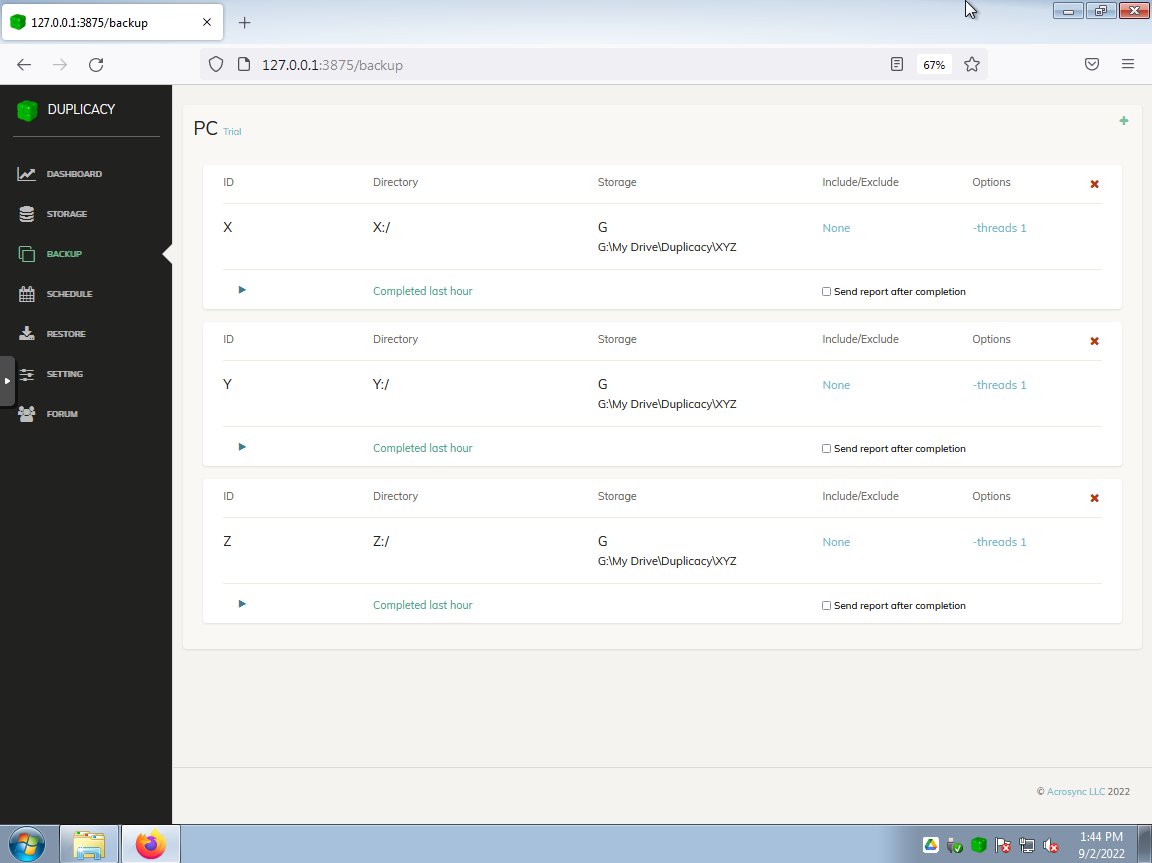
Backup configuration panel with the selected drives to be backed up…
Schedule configuration panel with a single daily backup at 1:00PM, 7 days a week that backs up each selected drive…
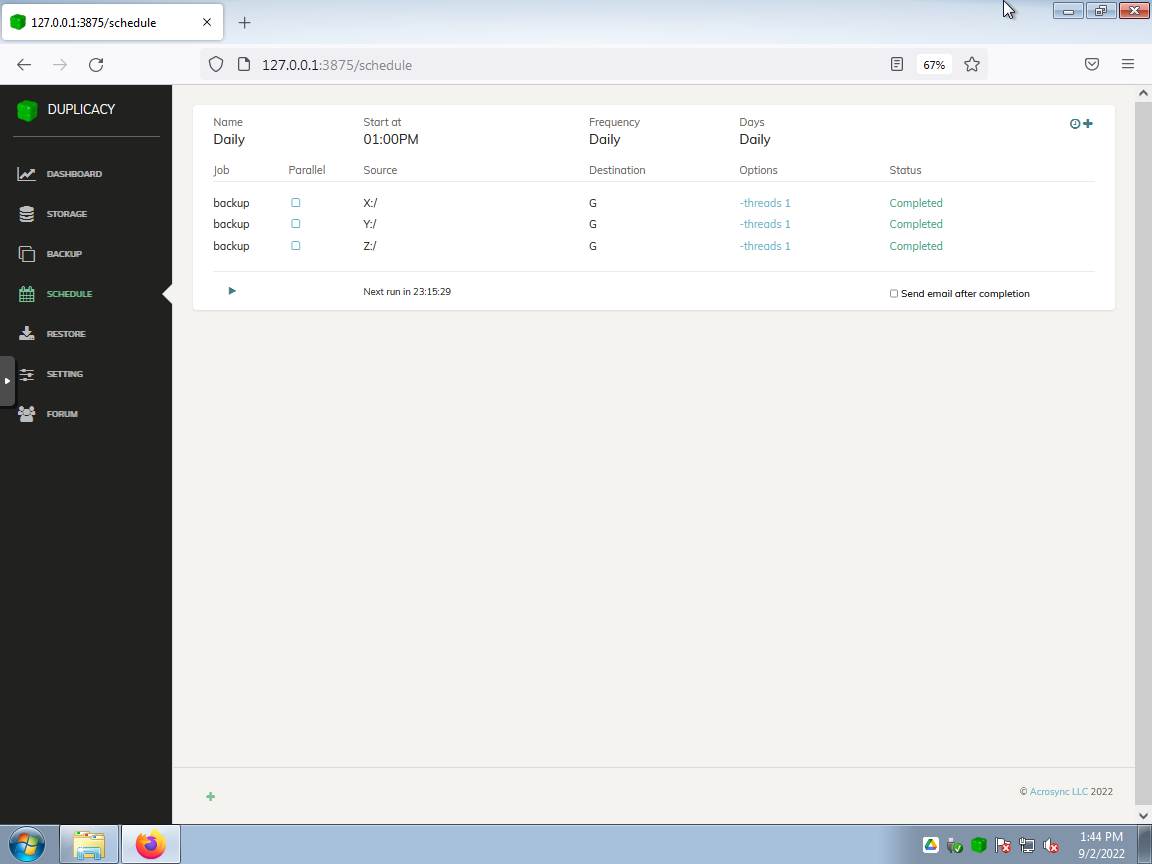
Restore panel showing the contents of snapshot revision 1 for the X: drive…
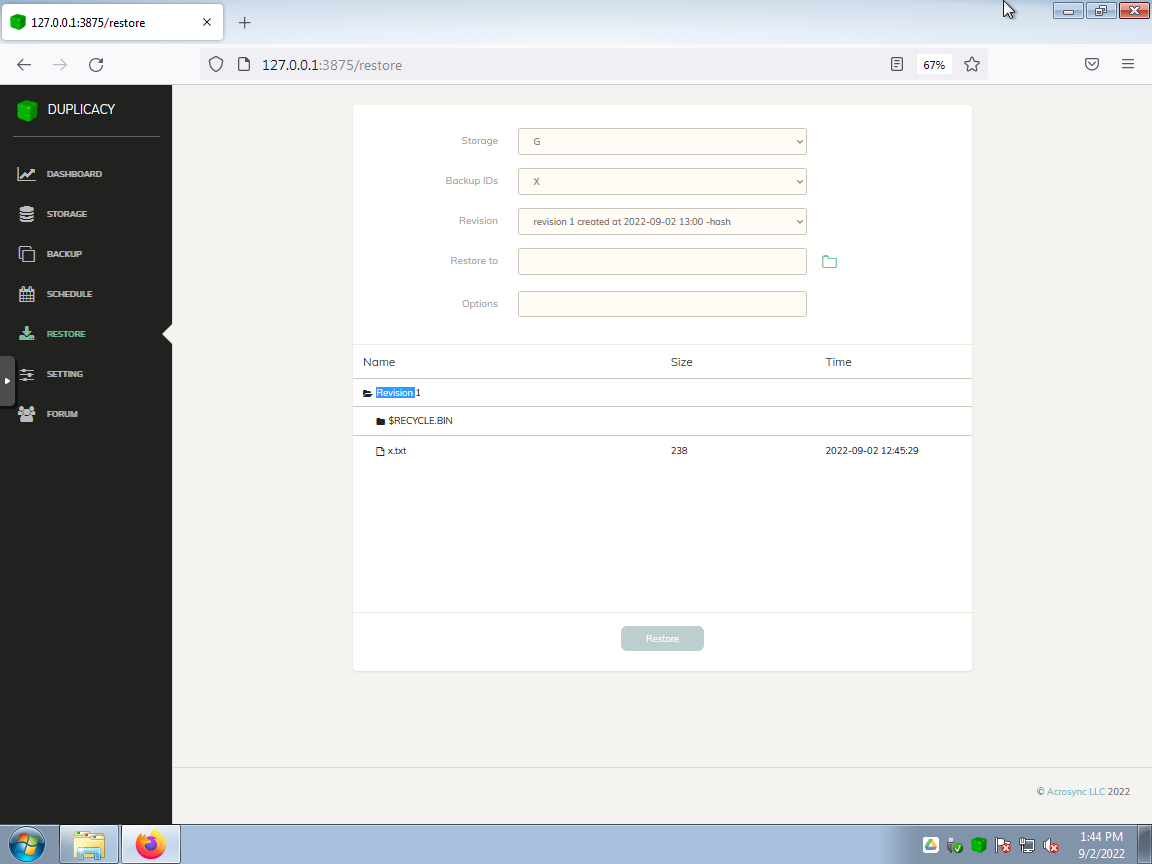
Back to Windows Explorer for a quick tour of the contents of G:\My Drive\Duplicacy. I added a “XYZ” folder for Duplicacy to save backups into…
(Although G: is a virtual drive provided by the Google Drive desktop client, the storage destination could just as easily be Backblaze B2, Wasabi, OneDrive, etc. via a S3 API.)
Exploring a little deeper, here are the chunks and snapshots folders along with Duplicacy’s storage config file inside the XYZ folder…
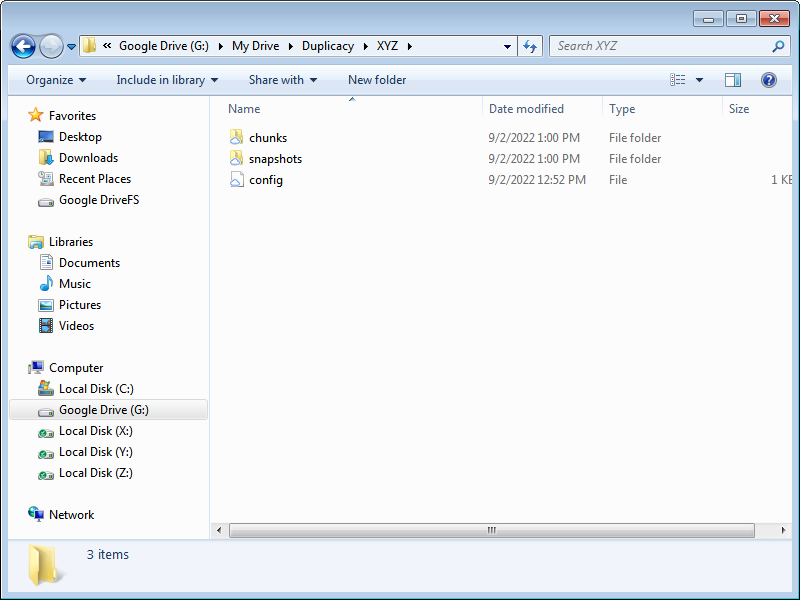
The chunks folder contains the tree of chunk files…
Inside one of the chunks subfolders is a chunk that was recently uploaded by a backup…
Recapping…
- Set a storage destination.
- Selected a bunch of sources (could have easily added a few folders too).
- Set a backup to upload the sources to a shared storage destination (taking advantage of deduplication).
- Showed that a particular snapshot revision for a source can be restored.
So if the requirement is to “select a bunch of sources (regardless of where they are), select a destination, and backup from A to B”, what’s missing from the example above?
(Setting up the virtual machine, installing Windows and other software, grabbing and editing the screenshots took 2+ hours… setting up the backup in Duplicacy took 2 minutes.  )
)
@gadget These are 3 different backup plans
I want to have one backup plan for all 3 drives
Imagine that in each drive there is a folder that is a certain color (e.g. Z:\Red and X:\Red etc. as well as Z:\Blue and so on).
I want a single backup plan per color, not 3 backup plans per color,
because then if i have 3 drives and 9 colors i would have 27 backup plans instead of 9 backup plans.
Why do i want a backup per “color”? because it is exactly this property (i.e. obviously it’s not an actual color or even a folder with a color-name, it’s just a “code” for some arbitrary categorization of the data that spans multiple drives. In my personal case it’s a code-name for importance of the data, which warrants different treatment) that might influence things like destinations, the frequency, and other properties
I want to have for example a plan named: “red → gdrive” and a plan named “red → NAS”
I don’t want to have a plan named:
“Z-drive-red-gdrive”
and
“X-drive-red-gdrive”
and
“Y-drive-red-gdrive”
and
“X-drive-red-nas”
and
“Y-drive-red-nas”
and
“Z-drive-red-nas”
and then have the entire set — for blue as well (maybe with different destinations)
This separation to drives makes no sense
And then, let’s say there’s a new drive added to the mix, now I have to create maybe 19 new backup plans instead of just adding it to the very few I have that already describe exactly the logical type of source (rather than a physical location) and the destination.
I really don’t understand what’s complicated about this?
Instead of each backup in that list saying : “I am a backup of stuff of type RED but only those that happen to reside in X drive and i go to destination D1”
I want it to say: “I am a backup of stuff of type RED and i got to destination D1”
A new drive/source appears? great - i just add it to the include list of each relevant category (if it has any data of the relevant category) - and i’m done
Physical locations → described in include/exclude lists
Logical categorisations → Warrant creation of distinct backups
The existence of a new drive should not warrant creation of new backup plans, since it perfectly fits already into existing logical division of the data (e.g. “Movies” or “important stuff” or “Grandma’s docs”)
Is that any clearer?
Why does grandma’s docs span over 3 drives? who knows - maybe grandma is a bit disorganized, it doesn’t matter. For any other Windows program it’s a trivial feat to let me select multiple drive sources per a single “plan”.
Just like it makes no sense to have a backup plan per “folder”, it makes no sense to have a backup plan per drive.
In a perfect world, I wouldn’t need to create multiple backups per destinations either, i could just provide each logical backup scheme a list of destinations as well. That way for example the same include/exclude list wouldn’t need to exist 5 times if i have 5 different destinations for a certain logical division of my data.
Here’s a short “algorithm” of creating a new backup scheme that would perfectly capture what I’m trying to say:
- Name your backup scheme (e.g. “Important Stuff”)
- Choose sources for the backup (any drive(s), any folder(s) within any of the drives, etc.)
- Choose destinations for the backup (from a list of pre-defined destinations)
That’s it
Now there’s a logical single entity to describe what would otherwise need to be “N x M” back up schemes, where N is the amount of possible physical sources (e.g. drives) and M is the amount of possible destinations (i.e. storages).
Simple.
Now i know that “important stuff” includes so and so data from so and so drives, and goes to these and these destinations.
I can easily add more data to the scheme with a single change, or add/remove destinations with a single change.
I don’t need to manage 18 different backup schemes (in case i have 3 drives and 6 destinations).
If i had 5 different categories (which i do), that might mean (in the worst case) i need to manage 90 (!!) different backup schemes, each with its own (duplicated) include/exclude lists.
Why?
Let me manage five backup schemes (one per logical category), because this is exactly what distinguishes them: their logical role, not their physical source or destination.
Since you’re still editing your post I’ll wait a bit before rereading it thoroughly, but the short answer to your question above is “Yes”.
What you just described wasn’t what was detailed in any of your earlier posts. You asked about creating a single backup plan that had multiple sources and a single destination. Even during the discussion regarding filesystem links and filters, the only mention of folders was not wanting to have to individually add filter rules to include them in a backup.
I think what you’re looking for can be done with Duplicacy (CLI and Web edition). But as I mentioned in an earlier post, the stumbling block here is Windows’ reliance on drive letters – Linux, macOS and other Unix-like operating systems are built on the “one big ‘virtual’ root” you were/are trying to achieve. It’s not that you can’t use Windows; it’ll just take a little more effort to make it do what you want.
Text-based online forums lack the audio and visual cues that are a part of normal conversations so I could be wrong, but I sense frustration and perhaps even some irritation. There’s no need for either. Everyone on this forum is here for the same reasons. I cannot speak for anyone else, but I don’t have mind reading mutant powers, so bear with me if I have to ask a lot of questions in order to help you.
You yourself referenced my previous post as well, which clearly indicated that I have multiple destinations and multiple logical “divisions” of my data based on its importance, so the combination of the two posts should indicate exactly what i’m trying to do.
The fact I tried to solve the problem of including multiple drives within a single backup (with a single destination) is simply because it was my understanding that Duplicacy doesn’t support more than one destination per backup-scheme.
I could live with having to duplicate my backups to account for multiple destinations for the same “source”, but having to ALSO duplicate them per drive was too much to cope with (it also defied any logic, in my eyes).
I didn’t want to confuse the forum with 3 different problems when i was focused on solving one. It’s customary to try and tackle one problem at a time.
The issue of filter patterns is another issue i encountered along the way which also forces duplication and manual labor.
But just from me discussing it you can easily surmise I have multiple folders in different drives (i even explicitly gave such a scenario in the examples i provided)
My point is that it shouldn’t. Other Windows software deal with this “problem” of drives perfectly well without forcing users to create virtual roots or symlinks. It’s rather wild to even suggest that it should be necessary…
Being misunderstood about something quite basic can be frustrating.
Asking questions is fine, if that’s all you did I would gladly answer each one to alleviate any lack of clarity about my explanations or examples.
What you did is mostly assume I’m trying to do “B” (after explaining rather in detail how i’m trying to do “A”) - and then to show me some non-solution and say: “See, easy!” and that is frustrating
Having you literally wasting 2 hours just to prepare the visual example you did only did more to add to my frustration. It’s like ordering an orange juice and having the salesman come back after a while with a chicken soup they toiled on for hours in the kitchen. I just wanted juice.
Again, what i’m talking about here isn’t some crazy suggestion — the “logical” division of backups is the most generic and universal implementation possible - since it even includes the present state of things (if anyone wished to divide their backups that way).
e.g. - want to have a backup scheme per source drive AND per destination?
With my suggestion of the “perfect” implementation - you could.
Want to have a backup schemes that includes multiple source drives, multiple destinations,
---- making the only difference between the different schemes - the question of which source folders are included in each scheme?
with my suggestion - you could.
and so on.
It allows the most flexibility since it doesn’t bind you to either a single physical source, nor a single physical destination.
===
and - again, regarding the frustration, you spent what seems to be hours also crafting the reply regarding the issue with the filter patterns ---- talking about loops, giving intricate examples that are completely irrelevant to the case, etc.
It’s not rocket science: it can be replicated with an easy - single folder - that is nested 3 layers deep —
and without the extra rules to account for intermediate paths – it simply doesn’t work.
Why? probably because there’s an implicit “Exclude everything” rule when there’s only include rules.
it has nothing to do with loops, with CentOS 8, with RHEL 4 with music libraries, with USB hubs or disk-on-keys or with the drive GUIDs — all these are completely foreign to the issue at hand and only serve to complicate the discussion.
It feels like you’re creating monologues or toiling on a visual user-guide instead of being laser focused on what i’m actually saying or what the problem at hand even is.
These are not “questions” to try and understand my use-case, these are long fables.
(I’m still reading and thinking about your recent post above, but just wanted to comment on one thing and ask a quick question.)
While I understood that you classify different types of data into various levels of importance, what wasn’t clear to me was which approach you wanted to use to achieve the desired goal (i.e., NAS to cloud, or virtual “root”).
Plus there was also no earlier indication that you wanted a particular backup to cover only a subset of files grouped into “logical divisions”, classes, etc. that span multiple sources, or as you most recently described, a “backup plan per color”.
You’re obviously well-versed with your backup plans and needs, so it’s perfectly natural that your earlier posts before today are clear as day to you, but it wasn’t to me – it’s why I posted the screenshots above because it demonstrated an approach that met the requirement to be able to…
However, backups analogous to a color-coded scheme is something else entirely different and not commonly done, even though some others might want the same thing.
A typical business might have email accounts, customer accounts (e.g., names, credit cards, etc.), and back office records (e.g., account receivables, inventory, taxes, etc.).
A typical company might choose to lump it all together by working via network drive shares from a central NAS that’s backed up to offsite storage. Much less complicated than backing up multiple computers and/or disks directly to a shared cloud destination.
My current employer used to take a similar approach… NAS plus a huge onsite robotic tape library that user devices (>10,000) uploaded backups to that eventually gave way to a hybrid local + cloud system before transitioning to a cloud-only model with every device syncing to Box/Drive/OneDrive (the company has all three) and backing up separately to CrashPlan (deduplication only between devices used by the same individual). There’s no stratification of user data. It’s all just a big digital pile per user.
I used to be a sysadmin for a research facility that had to comply with SOX, HIPAA and an alphabet-soup list of other federal and state regulations. Some of the instruments generated a terabyte of data per day – there was so much data that a Backblaze Storage Pod was assembled to keep up with the storage requirements. Emails, user files and instrument data were kept in separate data silos with the latter having the highest priority and more frequent backups.
Having used a lot of different backup software both free and expensive, I wish there was one that could easily do what you’re asking for because I’d want it too. I’m at a loss trying to name one that does exactly what you described.
Which brings me to my question… what is/was it about Duplicacy that drew you to it compared to Borg, Arq, Restic, Kopia, CrashPlan, Carbonite, Mozy, Backblaze (not B2), etc.?
And if there’s something about Duplicacy that makes it your first choice, wouldn’t a slightly more complicated setup be worth it?
+Z\my\cool\sub
+Z\my\cool
+Z\my
+Z
+Z
This filter setting isn’t right. The correct one would be:
+my/cool/sub/*
+my/cool/
+my/
The changes are:
- all paths are relative (to Z:/, assuming Z:/ is the directory to backup)
- the path separator is
/, not\ - with only
my/cool/sub/you include this directory but not any files under it. Append a*to include all those files too.
The second you want to add an exclusion, though, things get more complicated quickly.
The filter guide says:
If a match is not found, the path will be excluded if all patterns are include patterns, but included otherwise.
If I’m understanding correctly, that means that the minute you add any exclusion, you now automatically include anything that isn’t explicitly excluded.
That’s why I have my patterns set up the way I do, as I posted earlier. I had to add -* at the very end to exclude anything I don’t explicitly include.
I also found that once I do that, my/ (in your example) is no longer sufficient, although it might only be if my is a symlink/junction. I also have to have my by itself (no trailing slash), or otherwise it’s excluded by the -*. I think it’s probably because the symlink is seen as both a file and a directory.
A shortened version of my filters I posted before looks like this:
-C/Users/Compeek/AppData/*
+C/Users/Compeek/*
+C/Users/
+C/
+C
-*
I just tried again, and I think this is the minimal set of filters I can write (without considering regex at least) to include everything in C/Users/Compeek and all of its nested subfolders, except for C/Users/Compeek/AppData.
It took me a while to figure this all out a few years ago when I did it, but it’s been working great, so I can’t really complain. However, a simpler syntax for the filters would definitely be nice. (I’m not saying it’s an easy problem to solve–I’m a software engineer myself so I can certainly understand why it is the way it is.)
1 Like