Hello, everyone! I have been evaluating Duplicacy for the last week or so as I contemplate switching over from Duplicati. Everything that I’ve asked Duplicacy to do, it seems to do faster than Duplicati – except for this one task, and I feel as if I’m missing something extremely basic. Nonetheless, my frustration is mounting.
(In the interest of full disclosure, I am not a “techie” or command line wizard. Part of the appeal of Duplicati was that it was extremely intuitive, but in the end, corrupt databases and endless Warnings were making me nervous.)
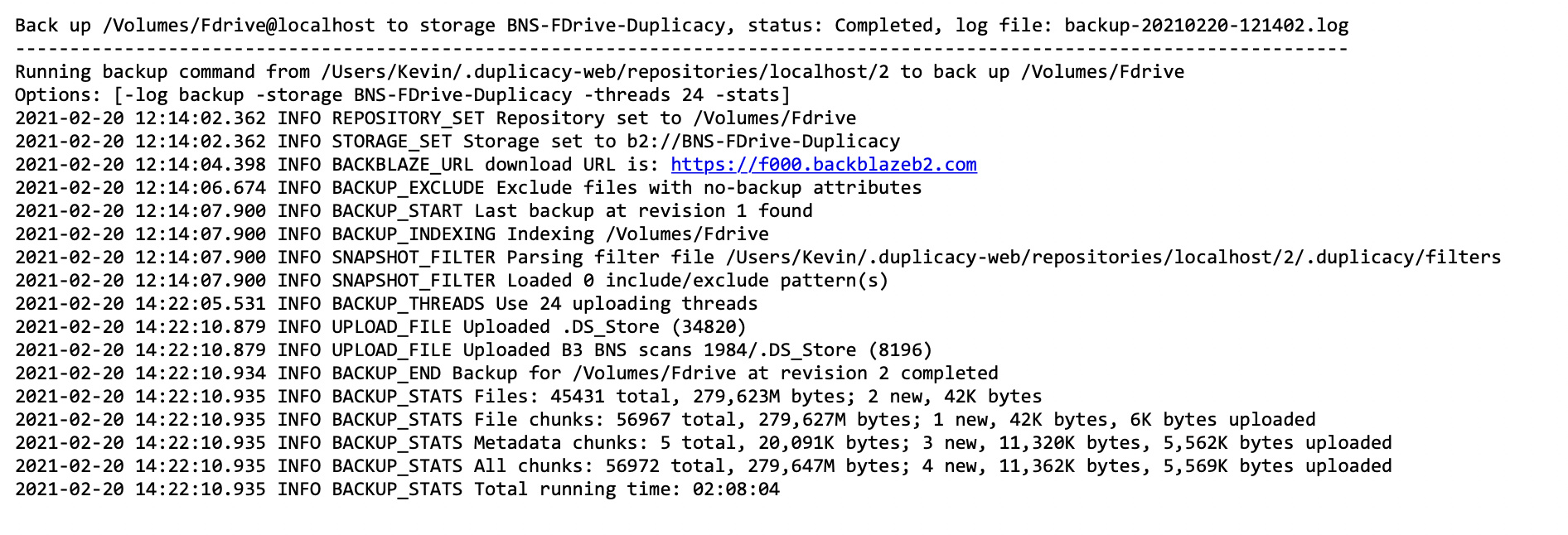
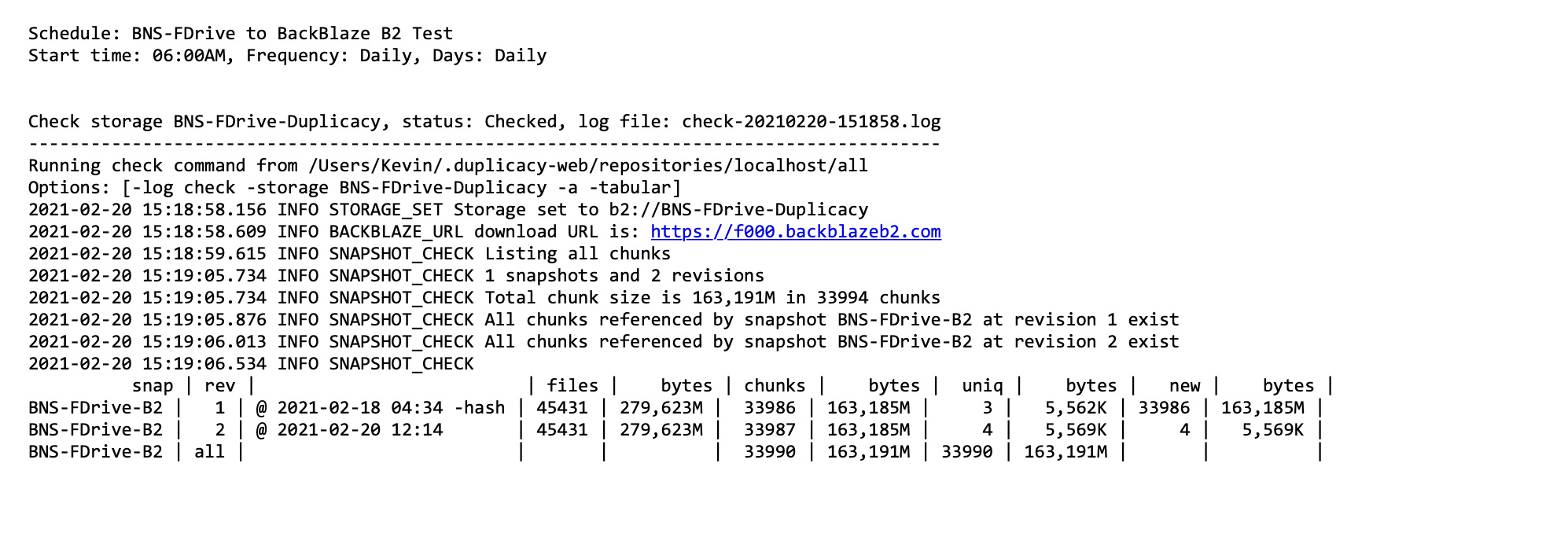
What I’m trying to do is move an entire shared folder – about 20GB worth of data – that is a mounted volume on my iMac to a BackBlaze bucket. This is one of two shared folders I use for work, and the smaller one of the two (about 5GB) indexed and uploaded in about 2 hours initially. That seemed reasonable and was similar performance to what I recall the initial Duplicati upload taking. However, this larger folder is taking 2-3 hours to index, and then Duplicacy estimates needing between 3-4 days to complete the upload! I have a fast Internet connection (1GB down / 25Mbps upload) and I’m not attempting this task via Wi-Fi – my computer is connected via ethernet.
After perusing the forums here, I’ve tried tinkering with the number of threads (1,10, 32), I’ve tried adding the “-hash” option (not sure what it does, but it didn’t seem to make a difference on this particular job), and I’m not sure what to try next.
Duplicacy seems like an excellent tool, but I cannot fathom why a 20GB initial backup would take 3-4 days to complete? Are certain options that would make this a breeze unavailable to me because I haven’t bought a license yet?
Thanks in advance for advice you can provide.
Kevin