
Hello,
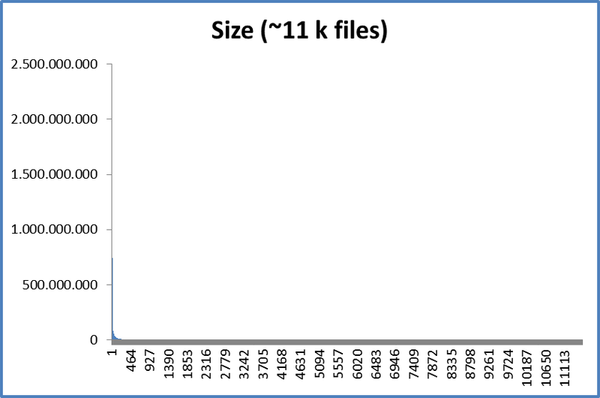
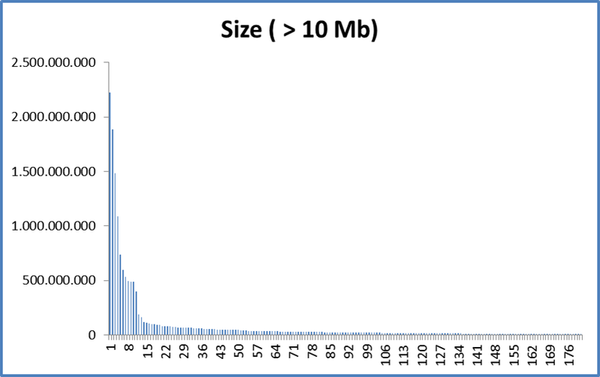
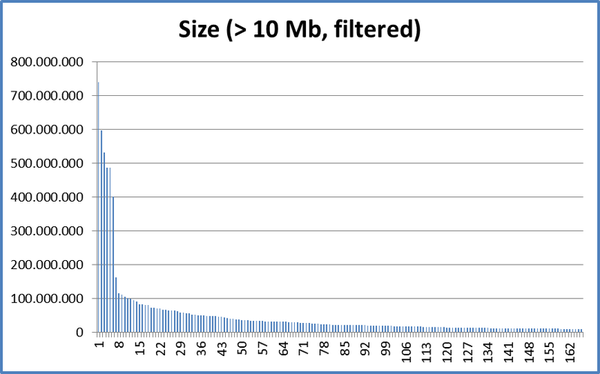
I understand Duplicacy uses a default chunk size ration of 4, so if the default average chunk size is 4M, then the minimum chunk is 1M and the maximum chunk size is 16M (please correct if I am wrong).
But what are the pros and cons of changing this ratio e.g. average chunk size is 1M, minimum chunk size is 128 KB, maximum chunk size is 10 M.
I have a lot of small text files (50KB-200KB) that change a lot therefore my thought process in having a small minimum chuck size would reduce the number of chunks which need to be uploaded when the files change, but also most of my files (say 99%) are static and don’t change at all, and they could be captured in the larger chunks.
cheers and thanks
 .
.