
Hi everyone,
I’m new to the world of backups, so I hope you can bear with me as I navigate through this learning process.
I own a large amount of critical data, including business documents and Lightroom photos, and it’s absolutely essential that I can never lose this data. To achieve this, I’m working on implementing a robust backup solution that protects against hardware failures and even bit rot.
Currently, I’m using Duplicacy on an Unraid NAS with an XFS file system. Below is an overview of my setup (I’ve included a drawing for reference):
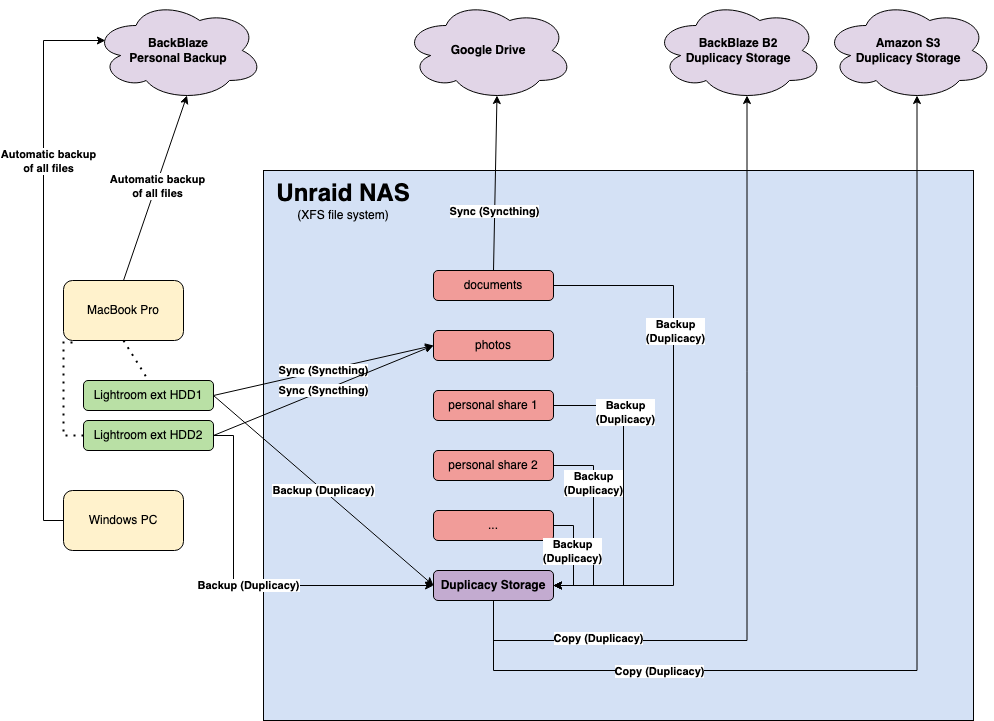
My Backup Flow:
- Primary Backup Location
- Duplicacy storage resides on my Unraid NAS.
- I back up data from various sources, including other Unraid shares (~directories) and external hard drives.
- Offsite Backups:
- I copy the Duplicacy storage on my NAS to two cloud storages: Backblaze B2 and Amazon S3.
- For this, I just run the copy command. Note that I haven’t enabled the “bit-identical” option.
- Backup Maintenance:
- I run check -chunks daily on my NAS storage and also daily run check on the offsite backups.
- I haven’t used the prune command yet, as I’m concerned it might inadvertently compromise my backups.
In addition to this, I sync photos to the NAS for immediate access, documents to Google Drive, and back up local machines using Backblaze Personal Backup. However, these flows are less relevant for this discussion.
My Concerns:
This setup has been running smoothly for a few months, but as I’ve started learning more, I’m beginning to question whether it’s truly resilient against all potential disasters.
Here’s one scenario I’m particularly concerned about:
If my NAS hard drives suffer from bit rot, a corrupted chunk in my NAS Duplicacy storage could render the backup unusable.
My Questions:
-
Propagation of Corrupted Chunks:
If a corrupted chunk appears in my NAS storage due to bit rot, will this corruption propagate to my offsite backups during the copy process? Does Duplicacy perform any checks before copying to prevent corrupted data from being uploaded? -
Recovery Options:
If my NAS storage is corrupted, is there any way to repair it using my offsite backups? I understand the chunks between my NAS and offsite storages differ since I haven’t enabled “bit-identical.” Would enabling this option allow me to repair corrupted chunks on my NAS by copying them back from the offsite storage? -
Erasure Coding:
Would enabling erasure coding help mitigate the effects of bit rot or prevent corrupted backups in this scenario? In what scenario would this option be usefull? -
Integrity Checks:
Does running check -chunks identify bit rot within the chunk files themselves? -
Storage Reliability:
I understand Duplicacy assumes the storage provider ensures data integrity, but that’s not the case with an Unraid NAS using XFS. Would it make more sense to:
a. Transition to a ZFS file system in a separate pool on my NAS server for Duplicacy storage?
b. Simplify things by removing the NAS storage altogether and backing up directly to offsite repositories?
Final Thoughts:
I know this is a lengthy post, but I’d really appreciate any insights or suggestions on how to improve my setup. Data integrity is my top priority, and I want to ensure my backup solution is as foolproof as possible.
Thank you in advance for your help!
Cheers,
Philippe
 Here are what I consider the strong points of Unraid:
Here are what I consider the strong points of Unraid: