
Bingo!
% ./gcd_delete ./gcd-token-duplicacy-arrogant-full-access.json 'test1.txt'
2021/07/18 21:15:15 test1.txt: 1_GpYzHvj608U7OqKg0wUzuJjb1DAi491
2021/07/18 21:15:16 test1.txt has been successfully deleted
% ./gcd_delete ./gcd-token-duplicacy-saspus-shared-access.json 'test2.txt'
2021/07/18 21:15:34 test2.txt: 1l8ACiJHfnuMowm-4g58wDF2munddPkmk
2021/07/18 21:15:34 Failed to delete test2.txt: googleapi: Error 403: The user does not have sufficient permissions for this file., insufficientFilePermissions
Now, both test1 and test2 are created by user x@arrogantrabbit.com and the shared folder is shared to user x@saspus.com, as a content manager, which is supposed to have delete permissions, according to the screenshot
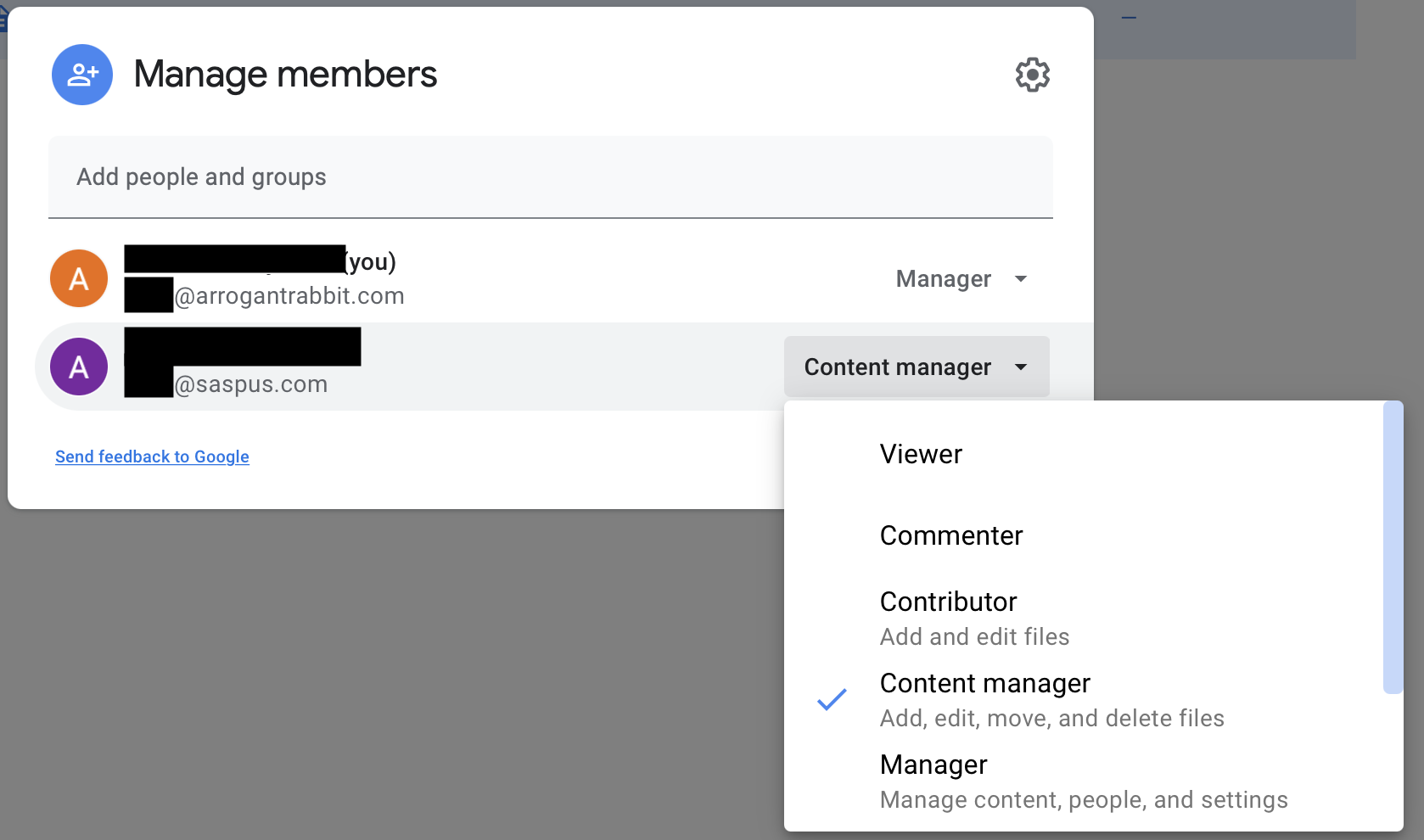
Why can’t we delete file then?
Edit. As a matter of testing, I switched the sharing to Manager (as opposed to “Content Manager”) and deletion succeeded:
% ./gcd_delete ./gcd-token-duplicacy-saspus-shared-access.json 'test2.txt'
2021/07/18 21:27:29 test2.txt: 1l8ACiJHfnuMowm-4g58wDF2munddPkmk
2021/07/18 21:27:29 test2.txt has been successfully deleted
Then I uploaded a file again, changed the sharing mode to Content Manager again, and it failed again:
% ./gcd_delete ./gcd-token-duplicacy-saspus-shared-access.json 'test2.txt'
2021/07/18 21:28:39 test2.txt: 1Zu6PBhDtlOEFVzo39o8ZvQ59_pNIWp_H
2021/07/18 21:28:40 Failed to delete test2.txt: googleapi: Error 403: The user does not have sufficient permissions for this file., insufficientFilePermissions
So, is this is google bug? Content Manager is supposed to be able to delete files, or it is duplicacy/test app/go google module issue by perhaps requesting too wide permissions to perform delete? (logging in to drive.google.com with x@saspus.com account allows to delete the file in both cases, so the google permissions seem to work correctly; it has to be some programmatic issue on the app or library side)
Edit. And lastly, perhaps when pruning duplicity should delete snapshots first, and chunks last: otherwise my datastore is now in a bit bad shape – the chunks were deleted, but snapshots not, and now check fails due to those ghost snapshots. This could also happen if the prune is interrupted. The idea being that it’s better to leave extra chunks behind than end up with a visible snapshot referencing missing chunks.