Let’s say I have a large amount of data and want to back it up to the cloud, over a residential broadband connection. As an example, say everything is in /My_Files/:
My_Files/Folder_A/ (0.5 TB)
My_Files/Folder_B/ (0.5 TB)
My_Files/Folder_C/ (2.0 TB)
My_Files/Folder_D/ (2.0 TB)
My_Files/Folder_E/ (2.0 TB)
My_Files/Folder_F/ (2.0 TB)
My_Files/Folder_G/ (1.0 TB)
Backing up a large dataset like this for the first time is naturally going to take some time.
Let’s say I want to back up the most important data first (e.g., the small folders, A & B), and then add other, bigger folders later.
My question…
Would it be best to:
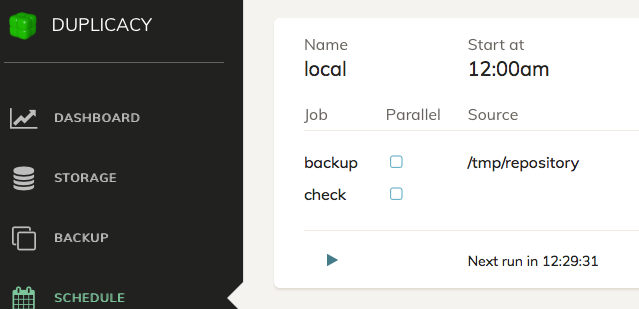
- Create a new backup in the backup tab (Duplicacy GUI)
- Using /My_Files/ as the source folder to backup
- add folders C, D, E, F, G to the “exclude” list for the backup job
- run the backup
- wait days/weeks/months to finish
- remove C, D, E, F, G from the “exclude” list for the backup job
- run the backup
Is this the right approach, or do I need to back up everything all at once?
Any disadvantages?