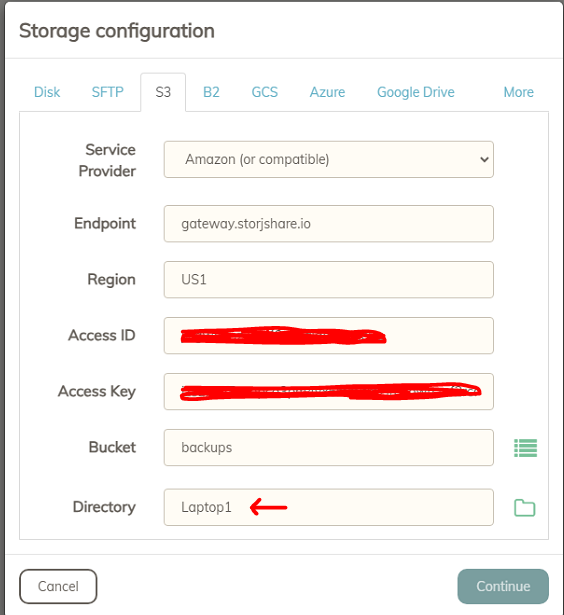
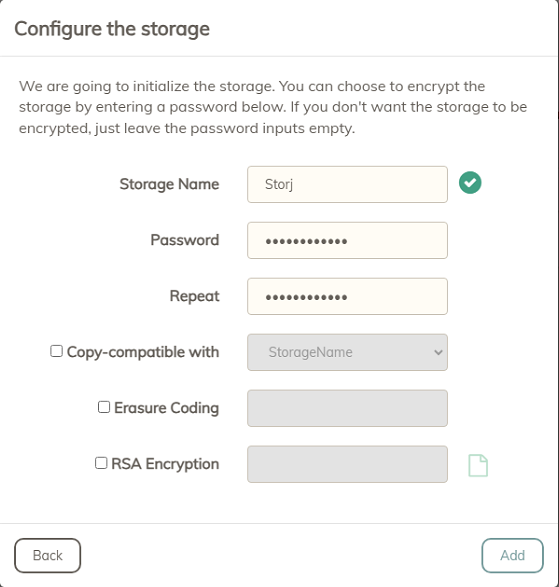
I see that we can now set up Storj in Duplicacy if selecting the Amazon S3 type from the web-ui. Is it recommended to create a single bucket and use the same Access ID and Key to backup all machines into that single bucket? Or create one bucket for each machine? More importantly, if I backup to multiple buckets, will the deduplication work as effectively as if I were backing up to a single bucket? Storj allows me to setup multiple projects and then multiple buckets within each project.
Example 1:
Project Name > Bucket Name (computer 1)
Project Name > Bucket Name (computer 2)
Project Name > Bucket Name (computer 3)
Project Name > Bucket Name (computer 4)
Example 2:
Project Name 1 > Bucket Name > Folder Name (computer 1)
Project Name 1 > Bucket Name > Folder Name (computer 2)
Project Name 2 > Bucket Name > Folder Name (computer 1)
Project Name 2 > Bucket Name > Folder Name (computer 2)
Logic tells me that for best dedup, to use a single project with a single bucket and then use multiple folders within the bucket that are named after each computer I’m backing up. But maybe that’s not how Duplicacy works so I wanted confirmation.