
I didn’t know that, interesting! I’ll evaluate in more detail, thanks for the tip.
This update would theoretically make it even easier for Duplicacy to integrate with S3
1 Like
Sorry I’m replying to a bit of an old / infrequently accessed problem but my experience:
The problem with intelligent tiering, is it’s not very dynamic at waking up cold files again. It’s a bit one-way isn’t it? Cold files have to be “copied” back to a hot tier.
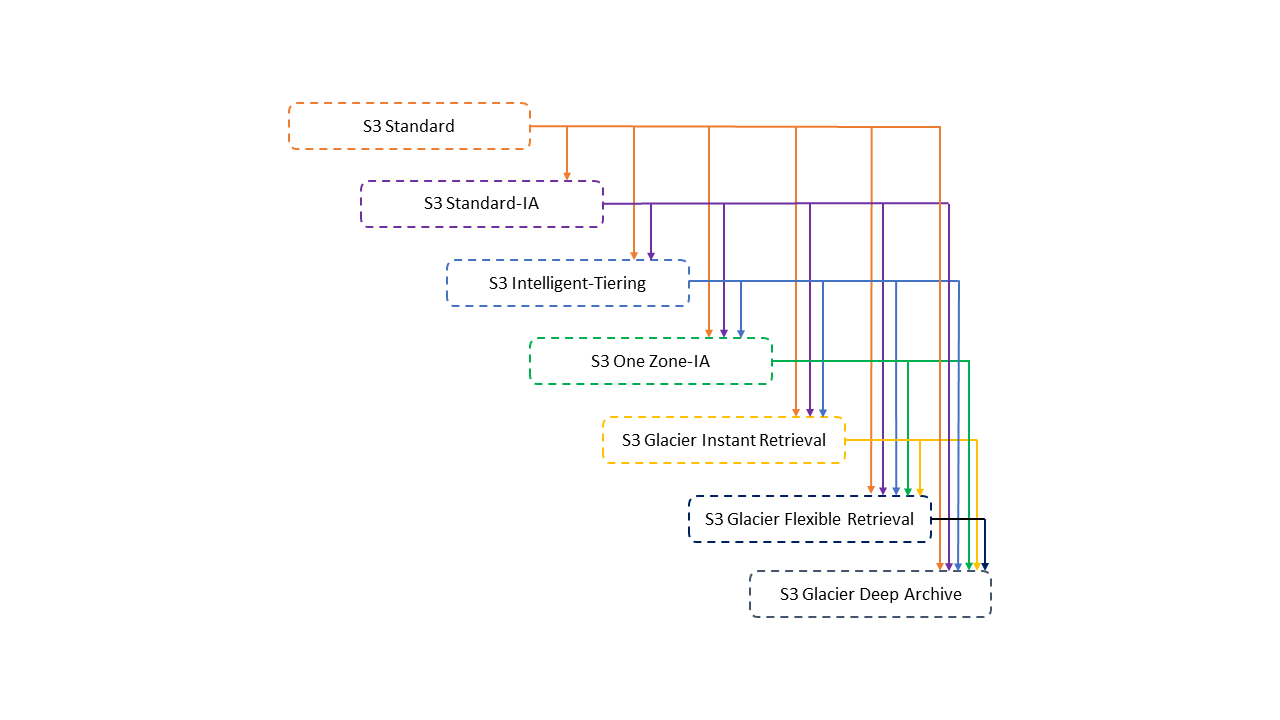
See this page: Transitioning objects using Amazon S3 Lifecycle - Amazon Simple Storage Service
So you can work around this by having conservative settings (which increases costs by keeping more than necessary on hot storage) or perhaps do frequent backups to keep reading/writing to those key files that Duplicacy needs to talk to.
At the time I was manually copying to S3 occasionally, because I had a slow DSL line and this caused problems for me. Occasionally a file that Duplicacy needed R/W access to, would basically be read-only.
To solve this lack of proper glacier support, I do the following - a simple Lifecycle rule for “chunks”
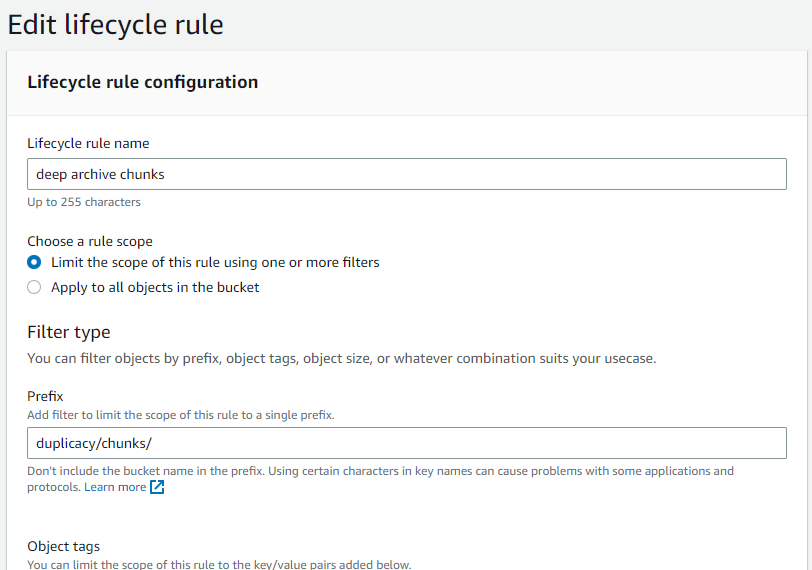
But I would caveat this by saying Duplicacy is not aware of Amazon at all - I backup to a local HDD and then just copy it’s contents to Amazon and immediately transition it to S3 GDA.
Well, I assume your glacier storage is for cases where your local HDD storage gets corrupted/destroyed, right? If that’s the case, I think you will need to copy the whole storage from the glacier in this scenario (e.g. no partial usage), which might be very expensive. Obviously, this depends on what kind of data is in your backup.
Yes that’s right, I do. As far as I know it’s just about the cheapest off-site storage and you can kind-of make work for Duplicacy with some faffing. It may not be “Supported” but it can be made to work.
I think of it as a periodically synced replica of a USB disk here in my house… it’s just done with scheduled tasks and the S3 CLI.
My data rarely changes (it’s just family photos, videos etc) and my Duplicacy disk is ~7TB full. AWS works out about $8 to $9 a month - I don’t tend to pay too much attention to the bills, but it’s always in that region.
I simply don’t bother pruning aggressively (no pruning of anything less old than 6months / 180 days or you get early delete fees) and in a true DR situation, I’d simply call all of the chunks back to S3 standard storage and download them all (and pay the incurred bill  ) to a local disk and initiate the proper restoration from that.
) to a local disk and initiate the proper restoration from that.
I don’t do backups every 15mins either - sure it doesn’t create chunks, but with my static data it’s hardly worth doing more than once a week. If I change a load of stuff I can always run it manually 
I’m currently migrating my data from Windows to Unraid, but once I’m stood up again here I can share my scheduled tasks / powershell scripts etc, and how I made it all work for anyone else who’s happy to hack around the current shortcomings.
My point was about restoring, not about backups. You may want to calculate how much it is going to cost you to restore 7TB from the Deep Glacier…
I feel we’re going a bit off topic here but yikes, you’re right… I ran it through the calculator - but more thoroughly this time. Storage/Recovery costs of $150ish if I remember what it said correctly. I could swallow that.
But, egress charges to download it all back to somewhere outside? Brought the bill up to about $750!!! 
Time to re-evaluate and… maybe split my backup into seperate storages and perhaps upload to B2 or somewhere, and just do the data I really care about rather than just “all of it”
Thanks Sevimo - I think lol 
1 Like
My solution was an off-site SBC that wakes up on schedule, connects to my local network via VPN for a scheduled Copy job, then shuts itself off when complete. Essentially a remote USB disk.
Folks, you are looking at this wrong.
The restore charges depend on urgency. Bulk restores are cheap. But even with that, you are supposed to multiple the cost of full restore by the probability of having to need to do said full restore, within the specific time period. Which is close to zero. Monthly cost of storage you pay with 100% probability — optimize that high probability event, not a rare obscure one, that likely will never occur. It’s a fallacy (loss aversion).
Calculate total cost of backup over, say, a decade, and use realistic probability of total loss. You’ll see hot storage is massively overpriced for this task. In fact, you break even in about 2 years, and after that its all gravy.
Small day to day restore are covered by Amazon provided 100Gb monthly free egress allowance.
I would never even consider using hot storage for backup. Even if I was made of money.
1 Like
Yeah agreed, I started running the numbers of some other hosting options and they soon add up, and compared to how often a house burns down I think chances are, it’s better off to suck up the humongous bill from S3’s GDA if it happens.
$1/TB/Month is just too good to miss really - be nice if this type of storage could one day be implemented in Duplicacy directly somehow.
The way OP’s backup is set up, there is no chance of piece meal extraction (without manually mapping and unfreeze individual chunks), he will need to thaw the whole storage before he can restore anything. This is not the case for other egress-expensive, but still online storages.
Yes, my next question to @saspus was for some details on the setup there. What do you do for off-site?
@sevimo you could in theory run many different storages with repositories, and backup to many different buckets. That would let you ‘piecemeal’ it to a degree, but if your house burns down, you’re probably going to recover all of it? otherwise why back it up offsite?
Until Duplicacy supports GDA properly, I’m going to break my backups up - I was storing rips, downloads, CCTV footage - you name it, in GDA. It was wasteful (but easy to manage)
I’m going to now only store irreplaceable stuff off-site.
Yeah, good point. Ultimately, until duplicacy supports it natively, there is no reason to try to hack the solution around its shortcomings.
My only offsite it Glacier Deep Archive.
I don’t use duplicacy for this: if the app does not support the workflow I desire, I change the app, not my desires. Until duplicacy supports glacier storage natively, I’m sticking to Arq7.
My setup is more or less straightforward: all data that I need more or less frequent access to lives in the cloud (iCloud), and syncs to variety of devices I use daily, at work and at home. All machines at home backup to NAS via Time Machine. NAS also hosts less important/old data—such as media library and archive of old projects.
One of the computers at home runs Arq7 to backs up everything—iCloud content, and stuff from the NAS via network share(other than Time Machine)—to Deep Archive. (You can remove the Time Machine backup and the NAS from the picture entirely, the rest remains the same)
If the house burns down—I have hot data in iCloud, so I grab a new mac and continue working as if nothing happened. And since all data keeps existing in AWS—I likely won’t bother restoring archived stuff that used to live on the NAS, until I require it. But if I do—well, that’s not a problem either, part of the mountain of money I saved not paying for hot storage over decades I can now give to Amazon to get my data back.
I doubt you would absolutely have to restore all data at once—what are you going to do with it? Most of the data for most users is archival in nature, it can just keep existing at the glacier. Stuff like old photos, videos, other media, projects, documents, etc. I can’t think of a use case where you need to always maintain instant access to entire dataset locally.
In the house-burning-down scenario, likely you would only need to restore a very small subset of the data, and keep on restoring the rest piece by piece, when and if the need to access those pieces arises. Some data likely will never get restored, and that’s fine. There is no need to rush to restore everything just for it to sit unused on your local server.
2 Likes
This approach (only worrying about frequently backup of hot/in-use/synced files) is what led me to abandon my NAS. Just leave the old unused files in the cloud (2 copies) and you don’t even have to worry about the house-burning-down scenario. If that happens, just buy a new computer (to access the synced files), without the need for any restoration.