Can you elaborate on this? What are you rebooting? The server or the client?
How does the disk IO look like on the destination? When prune appears “stuck” its’ enumerating files. If there are a lot of files – it may take signinficant amount of time with no traffic if metadata is not cached on the server.
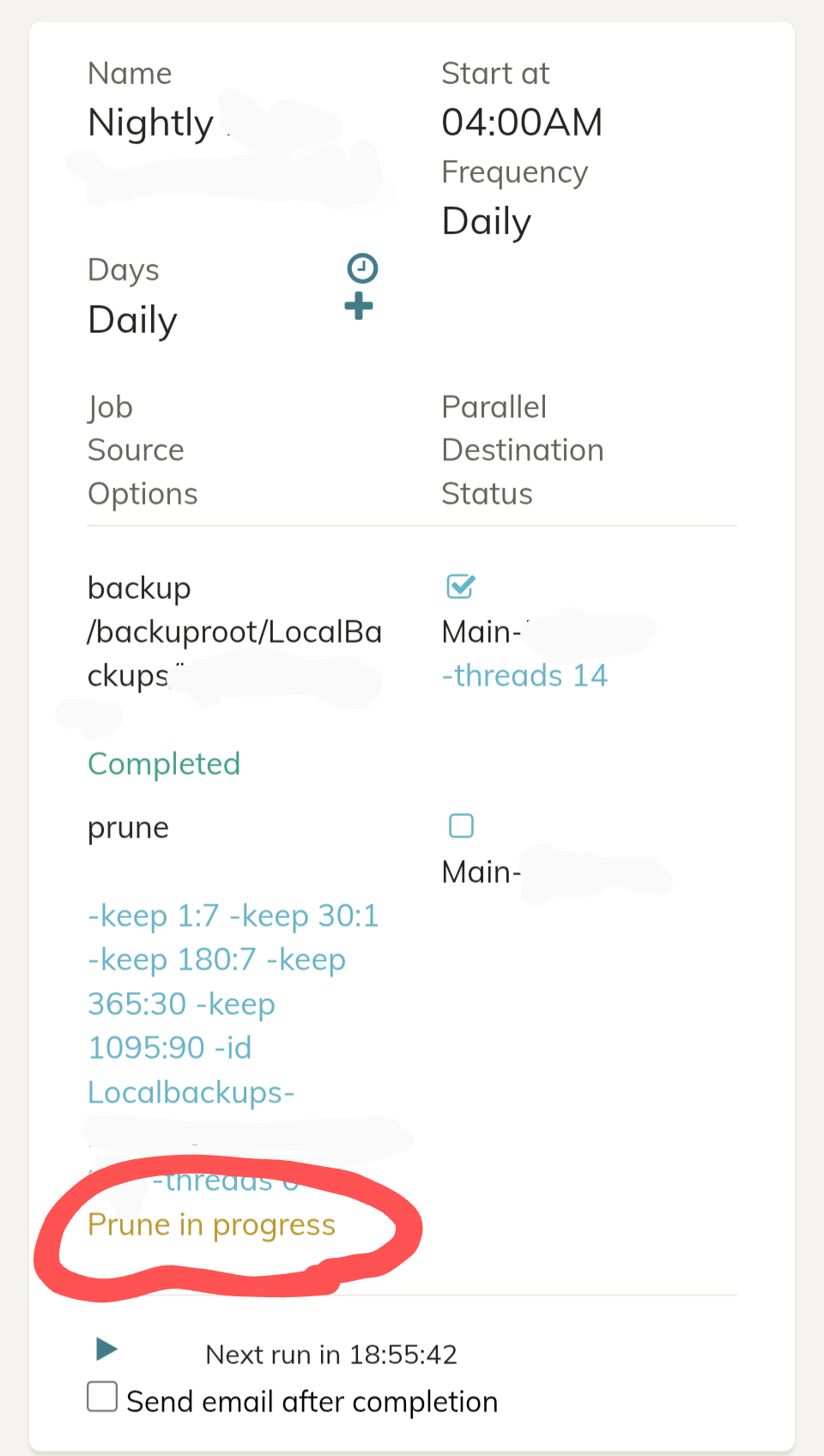
Duplicacy applies every prune argument in order to every file it tests. Your first argument will apply to filels older than 7 days. Therefore all subsequent argumetns won’t have any effect. See more here: prune · gilbertchen/duplicacy Wiki · GitHub
First, you need to decide between -keep 180:7 and -keep 1:7: for filles older than 7 days, do you want to keep one every half a year or every day? Proably the latter.
So you would want to transform your prune command into
prune -keep 1095:90 -keep 365:30 -keep 1:7 -keep 30:1 ...
Still quite a weird, and contradictory prune schedule.
For example, you want to keep a file every month for files from last week, but keep one every day for files older than 1 week? That woudl be impossible to acomplish.
Maybe explain in words what are you trying to acomplish?