
Thanks to rclone not hiding hidden files, I just noticed that I have thousands of .davfs.tmp files in my webdav backend (in the chunks folder). I’m assuming that these are the remains of failed upload attempts and I wonder if there is anything duplicacy could do to clean those up?
Wouldn’t a prune -exhaustive do that?
Duplicacy does create .tmp files, but they are renamed to the chunk files after upload and don’t have filesystem prefix. Furthermore, if upload failed, next time it would upload the same file and rename it again, so I don’t see how could accumulation of those files occur, unless the rename operation is broken on the remote in a way that behaves like copy.
But I don’t think even this is the case here: these files don’t look like anything that duplicacy would create — Duplicacy does not append .davfs to the file name; these files look like the artifact of davfs mounter. Do I remember correctly that you are backing up to locally mounted webdav folder using crooked pcloud mounter, as an attempt to workaround their webdav api issues?
Would not this serve as a last straw to finally move to another storage provider 
1 Like
Good point. But does prune -exhaustive delete all files except for relevant chunks or does it merely delete all non-relevant chunks? Note that these tmp files are hidden (i.e. starting with a “.”…
Yes, these files most likely were created by rclone mount which I tried to work around pclouds unreliable webDAV interface.
I’ll rephrase that: rclone serve is my last straw before I’ll consider alternatives. And so far it looks promising:
I know that is what you (@saspus) recommend long ago, but I couldn’t get rcloud serve to work on my Mac, but it wasn’t a big deal on my Debian server.
Disclaimer: by promising I currently mean that my first prune command since month is now running for over 50 hours and it is still running. I don’t know whether it taking so long should worry me, but for now it’s positive that a job runs for so long without error.
These .davfs.tmp were not created by Duplicacy. The .tmp files created by Duplicacy have 8 random characters. But, prune -exhaustive will delete any file with the .tmp suffix so it should delete them.
Unfortunately, those files don’t end with .tmp:
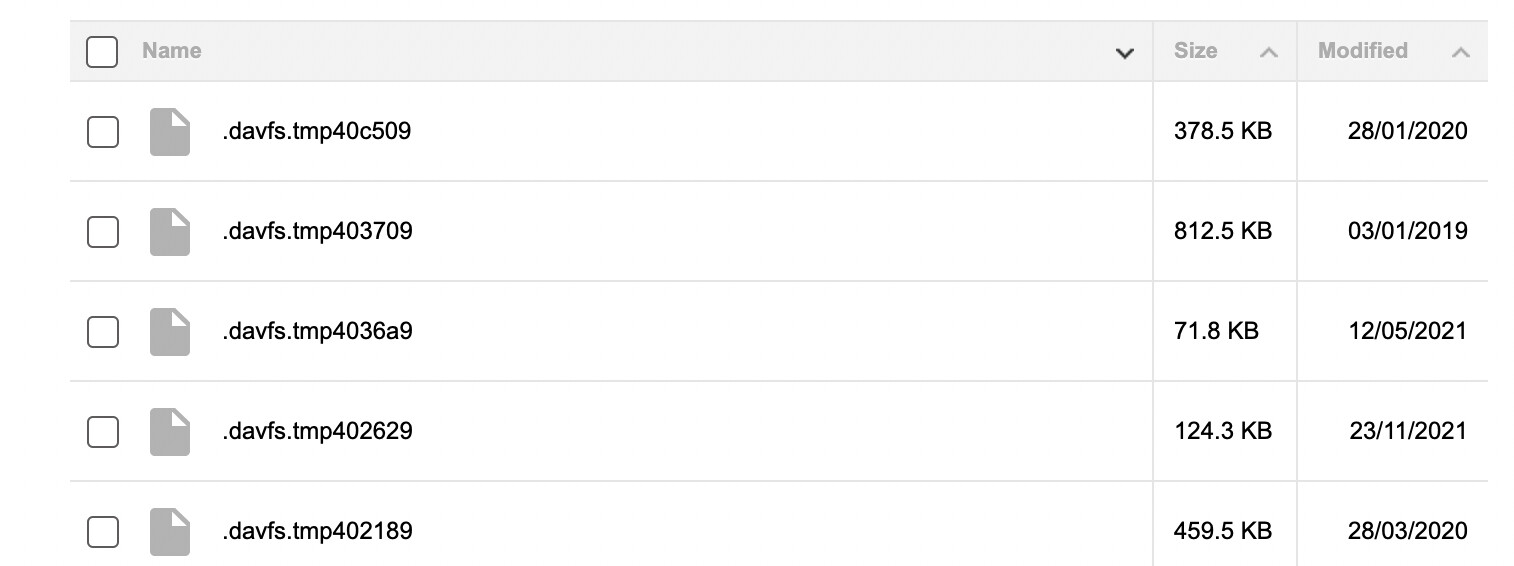
Something else that’s strange is that the files’ last modified date goes back as far as 2018 even though I first tried rclone in 2022. So either these files for some reason carry the original date of the files they were meant to be named after or rclone is not the creator of these files.
Maybe the rclone delete command can solve your problem, with a proper filter.
Run with --dry-run flag to test…
1 Like
Yes, that should do the trick! Sometimes solutions can be so simple 
I’ll try it once my current pruning job is through. It looks like it’ll take a few days. According to nethogs rclone is using about 4-500 kB/s bandwith for the prune job. Not sure if that is a limitation imposed by the pcloud api, but I do wonder why pruning fossilizing chunks takes so long, i.e. between 1 and 10 seconds for a single chunk:
2022-04-07 08:10:10.630 TRACE CHUNK_FOSSILIZE The chunk 88256ce8cdc36831ef7c9b9ad96b3651c03b596e552bd42a3b2ba3cb5eb2b7be has been marked as a fossil
2022-04-07 08:10:20.513 WARN CHUNK_FOSSILIZE Chunk c7a0f270ce329ffa25ba752cc8502a057cef8bf944199570715c4e6cace34dbb is already a fossil
2022-04-07 08:10:23.955 TRACE CHUNK_FOSSILIZE The chunk 5241c4183f3aac2ed622ea49c2cbdb6b4f68fa0cb0676768efd0578f1942f65b has been marked as a fossil
2022-04-07 08:10:31.526 TRACE CHUNK_FOSSILIZE The chunk 89dc56bcac2f8b33d665ad5820203fc17e3e70b123b06e6c4241fd1f18bc3a67 has been marked as a fossil
2022-04-07 08:10:35.026 TRACE CHUNK_FOSSILIZE The chunk 16c0abe078464fc75fed4ccd6514879086286745f4e91b3197fc6d009f5080c4 has been marked as a fossil
2022-04-07 08:10:38.810 WARN CHUNK_FOSSILIZE Chunk 3fc3a83100da9bbc6737ace61187ab2b57a968774010f31fa60854636e228733 is already a fossil
2022-04-07 08:10:45.583 WARN CHUNK_FOSSILIZE Chunk 85746e943a1106fc17082e969aa413450580e6a26beec17c696768dc4ff6bf36 is already a fossil
2022-04-07 08:10:52.723 TRACE CHUNK_FOSSILIZE The chunk 17a5ced7905567d3f23c31655897646f6095cc88b82bcd492daf331fd037dd23 has been marked as a fossil
2022-04-07 08:10:57.210 TRACE CHUNK_FOSSILIZE The chunk 089d2760f105448502137d6f09910c0f36b2717f3962cb1a28999e79b3a7f432 has been marked as a fossil
2022-04-07 08:11:01.226 TRACE CHUNK_FOSSILIZE The chunk f0f87b5d7404c3c33743dc2630ab15a174a2f63edf5faabe3ceafcd18cb45aab has been marked as a fossil
And I don’t quite understand why this would involve so much bandwith either. (But I’m happy, because at least it’s running without errors).
That’s a band-aid, though, the issue is still there. But I guess it’s indeed easier to just keep deleting all that periodically than fighting the losing battle in getting it triaged and fixed.
It’s probably rate limit – the bandwidth use is low because there is no data transfer as such, all is sent are commands. They take very little bandwidth, but you can’t send them too fast. I have seen prune take 2+days on 4TB backup to google drive.
WRT rclone specifically, even if you mount the remote with local cache, deleting files still takes forever as rclone does it in sync mode, deleting stuff from the remote one by one, and would not return until all is done. I would prefer it to delete locally instantly (i.e., build the list of stuff to delete and then sync deletions to remote in the background, but they don’t do that; just like you can copy a bunch of files instantly to the local cache and have it upload later in the background). I’ts one of many reasons I’ve stopped using rclone mount altogether. (one of the other is reliance on kernel extension, which is exceedingly discouraged and deprecated on all modern OSes that already provide special API to implement third party cloud storage natively. There are some third party tools (e.g., Expan’s SugarSync) that implement this API for many cloud storage providers. Some cloud providers, e.g., Box.com, have already rewritten their native desktop client to use that API, instantly making it infinitely more attractive and stable. Some other providers went the other direction – Google Drive switched away from using osxfuse (good!) but instead of using FileProvider API they chose to run a local SMB server to serve data (what!?). As a result, stability plummeted.
There are talks about supporting it on rclone forums for the past 3 years at least, but all threads end with “somebody needs to implement that”, so I don’t hold my breath…)
2 Likes
I finally did this and it worked perfectly using rclone -v --max-size 0 delete pcloud: --include "*davfs*"
BTW: The reason it took me so long was that my first prune command took two weeks:

And the second one (to actually get those old chunks deleted) another week:

I probably should be so annoyed at the slow speed, but I’m not. This is the first time in years that pcloud works for me without any flaws (except for the speed, if that’s a flaw in this case). I’m so relieved. (I still need to see, though, how the actual storage performs. I hope that all the many problems I’ve had with missing and zero size chunks were due to webDAV so that those will disappear now. But who knows…)
So, to anyone with a lifetime plan struggling with pcloud: forget about webdav and use the pcloud api via rclone (if you’re not on a lifetime plan, you should follow @saspus advice and switch to a better provider).
Well, I guess I’m the champion now (I also have 4 TB).
Thanks for explaining. This is good to know. (In the case of pruning, most operations were renaming files, but I guess the same principle applies there).
3 Likes
Just chiming in with a story similar to what @Christoph shared. I have been using Synology Cloud Sync to copy files from a Synology drive to PCloud via WebDav. I discovered recently that it was creating thousands of davfs* tmp files e.g. name-of-file/.davfs.tmp1a8d41 during file copy operations. Over 51,000 temp files, which were eventually consuming over 30% of my space on PCloud.
@towerbr solution worked for me, i.e. first find the files with
rclone --dry-run -v --min-size 0 delete pcloud: --include "*davfs* -P
…then, when you’re happy with the dry run output, delete them with:
rclone -v --min-size 0M delete pcloud: --include "*davfs*"
You can also send results to a log file with the options -P --log-file log.
Yes, it’s slow. Deleting 51,418 files took 44 minutes. But it worked.
I’ll need to switch away from WebDAV, perhaps to rclone if I can get that working between Synology and PCloud. Or switch away from PCloud. Sigh.
Thanks for the very informative thread, much appreciated and a huge time saver for me.
2 Likes
Glad you found it useful. I can say that so far switching to rclone seems to have solved all pCloud issues. I had one failed check the other day (missing chunk) but when it ran the next day again, everything was fine so that I’m filing the incident under minor glitches for now.
Well, unfortunately I have to correct myself. I now seem to have a corrupted chunk once again.
2022-06-10 03:41:44.005 WARN DOWNLOAD_RETRY Failed to decrypt the chunk 3d2ccf8b078b4c9652334d6b62b5d7ed44d49cacb8b0fb2dd988ecdec93ba6cf: cipher: message authentication failed; retrying
2022-06-10 03:41:44.011 WARN DOWNLOAD_RETRY Failed to decrypt the chunk 3d2ccf8b078b4c9652334d6b62b5d7ed44d49cacb8b0fb2dd988ecdec93ba6cf: cipher: message authentication failed; retrying
2022-06-10 03:41:44.025 WARN DOWNLOAD_RETRY Failed to decrypt the chunk 3d2ccf8b078b4c9652334d6b62b5d7ed44d49cacb8b0fb2dd988ecdec93ba6cf: cipher: message authentication failed; retrying
2022-06-10 03:41:44.033 ERROR DOWNLOAD_DECRYPT Failed to decrypt the chunk 3d2ccf8b078b4c9652334d6b62b5d7ed44d49cacb8b0fb2dd988ecdec93ba6cf: cipher: message authentication failed
Failed to decrypt the chunk 3d2ccf8b078b4c9652334d6b62b5d7ed44d49cacb8b0fb2dd988ecdec93ba6cf: cipher: message authentication failed
Will need to figure out this erasure encoding thing
I think at this point the right thing to do would be to stop the cat and mouse chase, admit that by now sheer amount of time spent working around pcloud issues exceeded any potential savings the existing lifetime account provides (this gets very close to the sunk cost fallacy), stop spending even more time designing ever more complex partial workarounds, and move account to Amazon s3.
Erasure coding does not guarantee success, you still would not be able to trust the storage, it would just reduce the probability of failure in some specific circumstances. If pcloud indeed allowed the file to rot — that would be unacceptable; what I think happened instead perhaps their api failed and they returned bad/truncated file. Or maybe they are experiencing outage. What happens if you clear the cache and try again?
(To be clear, the only motivation for the last paragraph is sheer curiosity. I don’t recommend spending time debugging this further. You have been unpaid pcloud QA long enough)
I appreciate both your curiosity and your relentless advice to give up on pcloud. I wouldn’t see my stubborn resistance to your advice as a case of the sunk cost fallacy. I am not sticking to pcloud because I paid for it but because everything else will incur significant costs (especially if I go for Amazon S3, but even B2 would be more than 200 USD per year).
I do once in a while consider alternatives but I think in order for me to go down that route and add that extra fixed cost to my living expenses I will probably need some additional benefits. Google One, for example, comes at around the same price as B2 (though fixed cost, regardless of actual storage used) and I could share that space with my family, but we don’t really need it and I might regret it if I end up giving up my Android phone as my last non-apple device… And I don’t know how good google drive actually is for backing up.
Indeed, but if I understand rot correctly, it would affect older files, right? And the currently corrupted chunk is just a few days old. So it’s probably something else, as you suggest:
Probably not an outage, as the check failed three days in a row.
This didn’t occur to me as an option but since the check failed on two different machines (my server and my mac), it seems unlikely that it’s the duplicacy cache. - Then again, both machines are going through the same pcloud serve instance, and I’m not sure what kind of caching is going on there… (I’m using ´–vfs-cache-mode full´)
It would be nice if this were just a cached api glitch.
But for now I’ve already started the usual procedure of moving the (allegedly) corrupted chunk and the affected snapshots. I have also added the -chunks option to my check command.

I would not call B2 “even” because while it’s one of the least expensive hot storage providers – its’ still a very expensive hot storage, meaning we pay for features that are not used and do not benefit the backup in any way.
We shall wait until duplicacy supports archival storage. This IMHO should be made a priority. And once it’s done - Amazon S3 is 4x cheaper than b2. I’m paying about $2.5/month for about $2.3TB of stuff (this is storage + incremental backups; the initial backup cost me about $14). When duplicacy supports archival storage – I may give it another go.
It isn’t very good, in-spite of what many here, including me in the past, would tell you. People want it to be good, because it appears to be cheap – but the service is designed for different purpose and piling millions of files into single folder is not what it not aligned with that purpose. Using it for a backup is a misuse of the service, and even if it happens to work OK today – this means nothing; it’s an unsupported use-case, and can break any time.
I’ve meant rot in a general sense, but yes.
They could have cached the same bad data when the service had an outage.
I would not use any VFS caching with serve for duplicacy: this not only removes atomicity of your backup, but also adds another point of failure. If that is on windows – then the filesystem corruption affecting data in unpredictable ways is always a real possibility. (I had chkdsk c: /f fix weird issues countless of times for the decades I’ve used windows. Why does it still keep corrupting filesystem in 2022 and how is it not a priority for Microsoft to fix is beyond my understanding. And no, this is not my faulty hardware, this happens both a generic PC and various Macs in BootCamp. Last it happened yesterday - corrupted textures in a specific game. Run check disk – it fixes something, reboot – bam, all works fine. Windows stability is horrible.)
This is terrible if you think about it. That this is an “usual procedure”, I mean.
I would turn off the caching in rclone. Duplicacy does not seek in files, it swallows them whole, so there is no benefit in having them enabled. Maybe this will be enough to prevent the failure from reoccurring – either by eliminating the middleman cache, or by changing timing of pcloud api access.
1 Like
So this is arq, you’re talking about?
Yes, Arq7. (Arq5 was an unusable misunderstanding and embarrassment…).
I use Glacier Deep Archive tier for data that never changes (such as family photos and videos) and Glacier for other stuff - like documents. There is slight difference in cost and early deletion fee; the deep archive has 180 days min retention.
There are other storage classes, such as Intelligent Tiering that may be useful depending on your data, but if you have clear distinction between data types (for me it’s photos-videos-archives vs everything-else) manually setting storage types works better.
Here is pricing: Amazon S3 Simple Storage Service Pricing - Amazon Web Services
It’s worth paying close attention to restore and transfer fees: they can be quite significant, especially if you want all data back at once quickly. Since this is rarely the case, and since this is a secondary last-resort type of the deal (I have local Time Machine backup of everything to the server in the closes) this is pretty much an insurance policy: Low cost high “deductible” so to speak
@saspus could you help me interpret this:
When I run check with -threads 4 -fossils -resurrect (via rclone sftp) it works fine, but when I add -chunks it eventually fails due to “server not available” error.
I should probably post this to my thread on the rclone forum but to do so, I should understand what duplicacy does differently when I add-chunks Is it just that produces more traffic because it downloads all chunks?
few things come to mind.
If this is repeatable I would run rclone serve with verbose logging in interactive mode and see if it complains about anything.
Without -chunks all it does is enumerate and sometime rename files. With -chunks it actually tries to download them.
Depending on how duplicacy is accessing the sftp server – I’d think ig just downloads a file, so it shall “just work” but if they do anythign else (like range request – not sure if it is even a thing with sftp) then the existence and/or type of the rclone cache could make a difference.
I would start with enabling verbose logging in both duplicacy and rcloen and correlate what happens before the failure. Maybe rclone is using server too aggressively, maybe there is some other shenanigans…