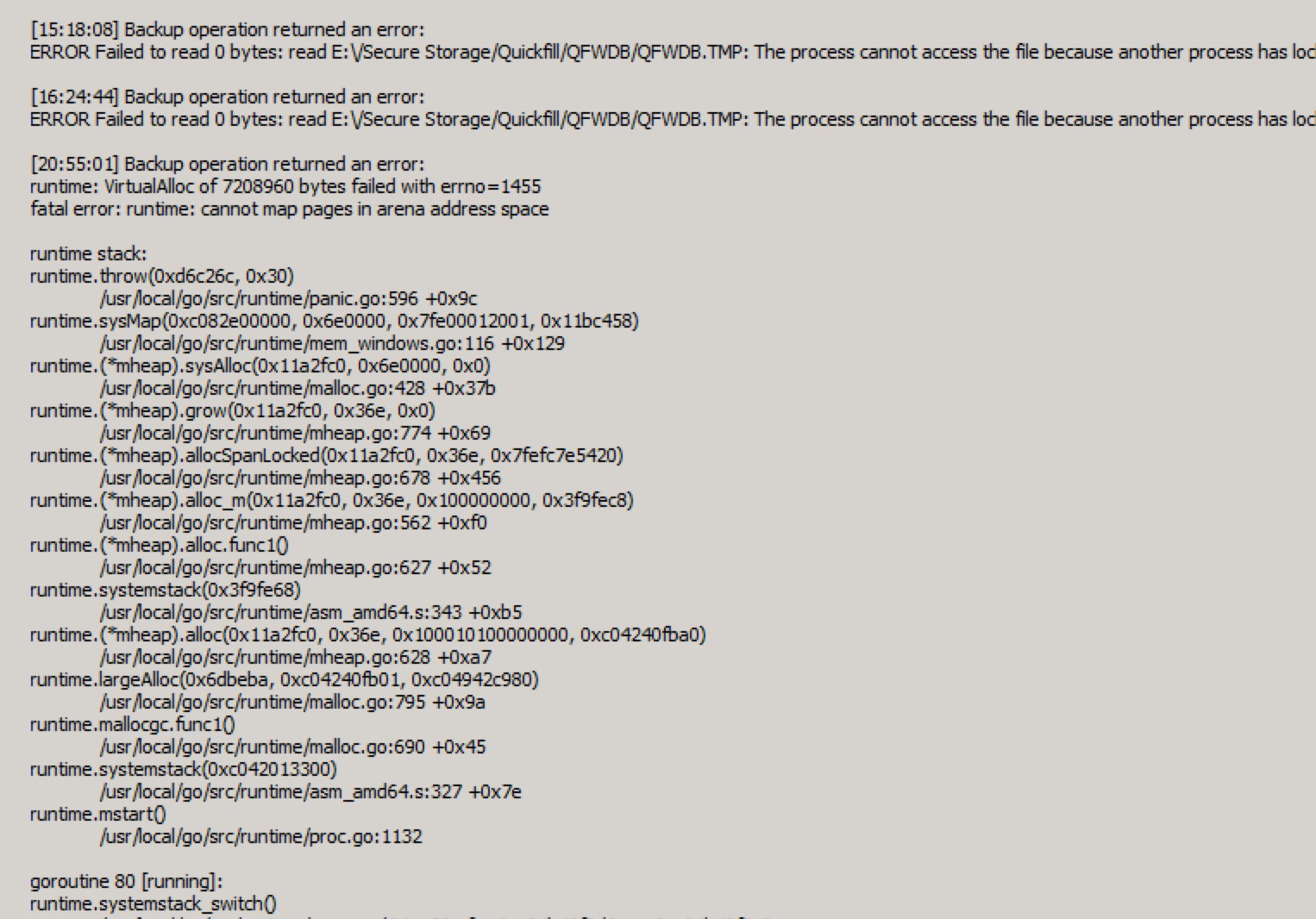
It’s got 3GB of RAM (it’s a VM) and about 160GB across 250,000 files. This is a fairly conservative scenario for a file server. Is Duplicacy simply not going to work without throwing tons of RAM at it? It seems like there should be a way to write a backup app that doesn’t need to keep everything resident in RAM? CrashPlan Pro was always awful with memory faults, but TSM doesn’t even flinch at the 2.5+ million files on one of my other fileservers. I’d really love to be able to move away from TSM (due to cost and other support issues) and I’d also love to use something open source and cross platform. We’ve already got a sizable contract with BackBlaze for endpoint backups, and B2 is really attractive from a cost/billing basis. So Duplicacy seems like a great fit, but I’ve gotta get it working reliably across 25+ Windows and RHEL servers.
I suppose I could create repositories lower in the hierarchy, instead of the root of the storage drive, but that complicates config…and even going one level down and creating repos for each subdirectory, Duplicacy would need to work on a dir of about 100GB and 200,000 files. I really couldn’t go any deeper, or I’d have to create hundreds of repos…and frankly, backup software shouldn’t require that. I don’t think it’s unreasonable to expect to be able to specify a drive to backup and have backup software more or less just work.
Any advice?