When I list my current revisions, I can see new revisions are still being added every day. When I try to prune, to remove some older ones, I get an error:
[...]
Deleting snapshot secretslug at revision 100
Deleting snapshot secretslug at revision 107
Deleting snapshot secretslug at revision 158
Chunk 39fc2e096db01751a4f8e67848bf3d41b53448890d5fdf2a44bf54a6bd54bb03 is a fossil
Failed to download the chunk 39fc2e096db01751a4f8e67848bf3d41b53448890d5fdf2a44bf54a6bd54bb03: URL request 'https://f123.backblazeb2.com/file/AnotherSecretSlug/chunks/39/fc2e096db01751a4f8e67848bf3d41b53448890d5fdf2a44bf54a6bd54bb03.fsl' returned 404 File with such name does not exist.
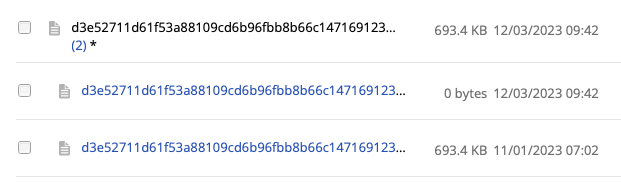
I’ve checked on the Backblaze server and the referenced file looks different from others. It’s marked with (3)* and when expanded I see 3 files with the same name of different dates. The most recent one is 0 bytes. None of these files actually have the .fsl extension referenced above though.
I’ve followed some guides and forum posts here, trying to resolve it. But no matter what I do, it keeps coming back with that 404. I’ve wasted enough time, and am now of the mind to just clear out the B2 bucket and start afresh.
But I’m not sure how to do that. Delete files from the bucket, delete the cache directory, and run duplicacy backup again?