ISSUE
Duplicacy is creating 100’s of new snapshots every day with only a few actually having new data (and thus a reason for existing).
PROPOSED SOLUTIONS
(1) Enable a backup option (eg) -skip-no-unique which does not create a new snapshot if the scan of the repository reports no changes to the data.
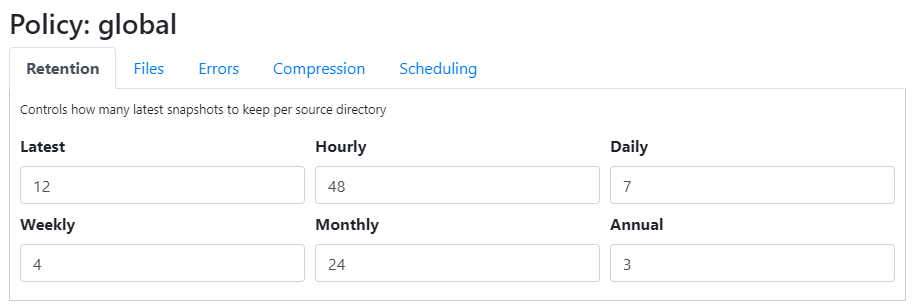
(2) Enable sub-day pruning rules. Eg: #Keep one revision per hour for revisions older than 1 day (1 day = a duration of 24 hours, not just from “yesterday” on a calandar.
WHY
I recently started using Duplicacy on a few client computers to back up directly to the same “storage” on Google Drive. They backup very important project files which change often so the interval in between backups is short, currently every 5-10 minutes. I have already set up a script to run the backups which is working great (CLI 2.7.2), but my issue is the already 100’s of snapshots accumulating after just a few days.
I could adjust my pruning to be more aggressive earlier on in the ageing of the snapshots, but that’s just more hammering on the storage running prune operations, which take a surprisingly long time on this storage (maybe from many ID’s backing up to the same storage so more calculations are needed??), all while backups are continuing to accumulate in the background.
I also worry about more aggressive pruning because of what I would consider Duplicacy’s poor handling of backup plans with more than 1 backup/day. You really only have two options: save all of your backups from a single day, or save one. Also, as discussed here: Prune -keep 1:1 keeps oldest revision, and what I am already seeing in my tests, Duplicacy chooses the oldest snapshot from each day with the oldest data as the one to save instead of the newest. Those two attributes create a nasty combination for sub-day backup intervals and I don’t understand the logic in either of them. Does it stem from Duplicacy working at a calandar-day level when deciding on what to prune as opposed to a duration of time? To say it another way, if you run a prune at 12:01AM, does it consider the backup taken 2 minutes earlier at 11:59PM a day old or 2 minutes old?
What I would love is the ability for Duplicacy to simply skip the backup procedure if there are no new files to back up, and not produce a new snapshot. This would result in at least a >99% reduction in snapshots for me. I’d like to hear if there are downsides to doing this.
Another benefit of skipping empty snapshots would be for restores. Duplicacy is lacking in its ability to easily browse, search, review, etc. the contents of snapshots (frequently-requested feature most recently here: Feature Request: Search Backups for File / See File History). It would be much easier to go back through snapshots and know that at each snapshot new data was added. Otherwise I have to initiate other commands to generate detailed snapshot lists, scroll hundreds of snapshots looking for changes to “unique items,” note those revision #'s, and go back and start restoring (I also can’t for the life of me make the history command play a helpful role in restores).
Regarding sub-day pruning, I do think it should be available as others have expressed a need for it (eg: Enhancement proposal for prune command) and I have found it useful with other backup systems (…pretty much all of them offer something comparable). I do worry about this as a solution for my needs though, given my previously-mentioned issues with  pruning in general.
pruning in general.
I would use my local backup system (Urbackup) to manage these high frequency backups, but I want them to get to the cloud asap and as discussed here I cannot get Duplicacy to play nice with that local backup destination because of the way Urbackup structures its destination storage.
Am I being overly nit-picky? Should I just shut up and let make 100’s (ok, as of posting I have crossed into 1000’s) of snapshots?
Here’s a snapshot list after running for a few hours to give you an idea of what I’m talking about
9700_PRODUCTION_BACKUP_01 | 49 | @ 2021-02-07 21:26 | 460 | 1,774M | 334 | 1,319M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 50 | @ 2021-02-07 21:35 | 1295 | 1,889M | 352 | 1,358M | 3 | 149K | 21 | 39,972K |
9700_PRODUCTION_BACKUP_01 | 51 | @ 2021-02-07 21:38 | 2075 | 1,890M | 353 | 1,358M | 4 | 515K | 4 | 515K |
9700_PRODUCTION_BACKUP_01 | 52 | @ 2021-02-08 02:31 | 513 | 1,864M | 353 | 1,368M | 3 | 84K | 11 | 25,308K |
9700_PRODUCTION_BACKUP_01 | 53 | @ 2021-02-08 02:34 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 4 | 86K |
9700_PRODUCTION_BACKUP_01 | 54 | @ 2021-02-08 02:45 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 55 | @ 2021-02-08 02:55 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 56 | @ 2021-02-08 03:05 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 57 | @ 2021-02-08 03:15 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 58 | @ 2021-02-08 03:25 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 59 | @ 2021-02-08 03:35 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 60 | @ 2021-02-08 03:45 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 61 | @ 2021-02-08 03:55 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 62 | @ 2021-02-08 04:05 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 63 | @ 2021-02-08 04:15 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 64 | @ 2021-02-08 04:25 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 65 | @ 2021-02-08 04:35 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 66 | @ 2021-02-08 04:46 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 67 | @ 2021-02-08 04:56 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 68 | @ 2021-02-08 05:06 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 69 | @ 2021-02-08 05:16 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 70 | @ 2021-02-08 05:26 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 71 | @ 2021-02-08 05:36 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 72 | @ 2021-02-08 05:46 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 73 | @ 2021-02-08 05:56 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 74 | @ 2021-02-08 06:06 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 75 | @ 2021-02-08 06:16 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 76 | @ 2021-02-08 06:26 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 77 | @ 2021-02-08 06:36 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 78 | @ 2021-02-08 06:46 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 79 | @ 2021-02-08 06:57 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 80 | @ 2021-02-08 07:07 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 81 | @ 2021-02-08 07:17 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 82 | @ 2021-02-08 07:27 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 83 | @ 2021-02-08 07:37 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 84 | @ 2021-02-08 07:47 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 85 | @ 2021-02-08 07:57 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 86 | @ 2021-02-08 08:07 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 87 | @ 2021-02-08 08:17 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 88 | @ 2021-02-08 08:27 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 89 | @ 2021-02-08 08:38 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 90 | @ 2021-02-08 08:48 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 91 | @ 2021-02-08 08:58 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 92 | @ 2021-02-08 09:08 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 93 | @ 2021-02-08 09:18 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 94 | @ 2021-02-08 09:28 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 95 | @ 2021-02-08 09:38 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 96 | @ 2021-02-08 09:48 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 97 | @ 2021-02-08 09:58 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 98 | @ 2021-02-08 10:08 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 99 | @ 2021-02-08 10:18 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 100 | @ 2021-02-08 10:29 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 101 | @ 2021-02-08 10:39 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 102 | @ 2021-02-08 10:49 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 103 | @ 2021-02-08 10:59 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 104 | @ 2021-02-08 11:09 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 105 | @ 2021-02-08 11:19 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |
9700_PRODUCTION_BACKUP_01 | 106 | @ 2021-02-08 11:30 | 514 | 1,864M | 354 | 1,368M | 0 | 0 | 0 | 0 |