
I noticed a very large increase to my duplicacy backup storage without a large backup that seems to coincide with this significant increase. Is it possible there was a corrupt backup? How could I delete these extra chunks? Here are a couple screenshots:
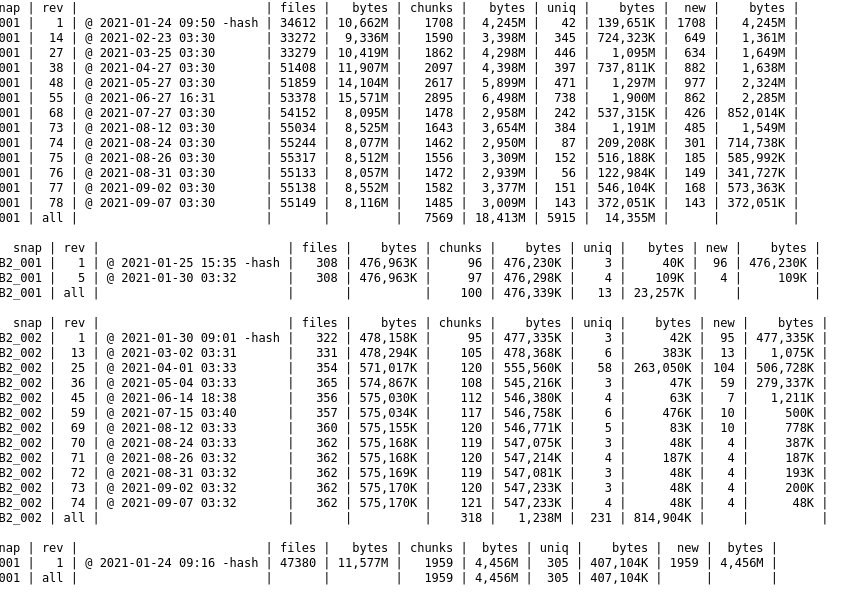
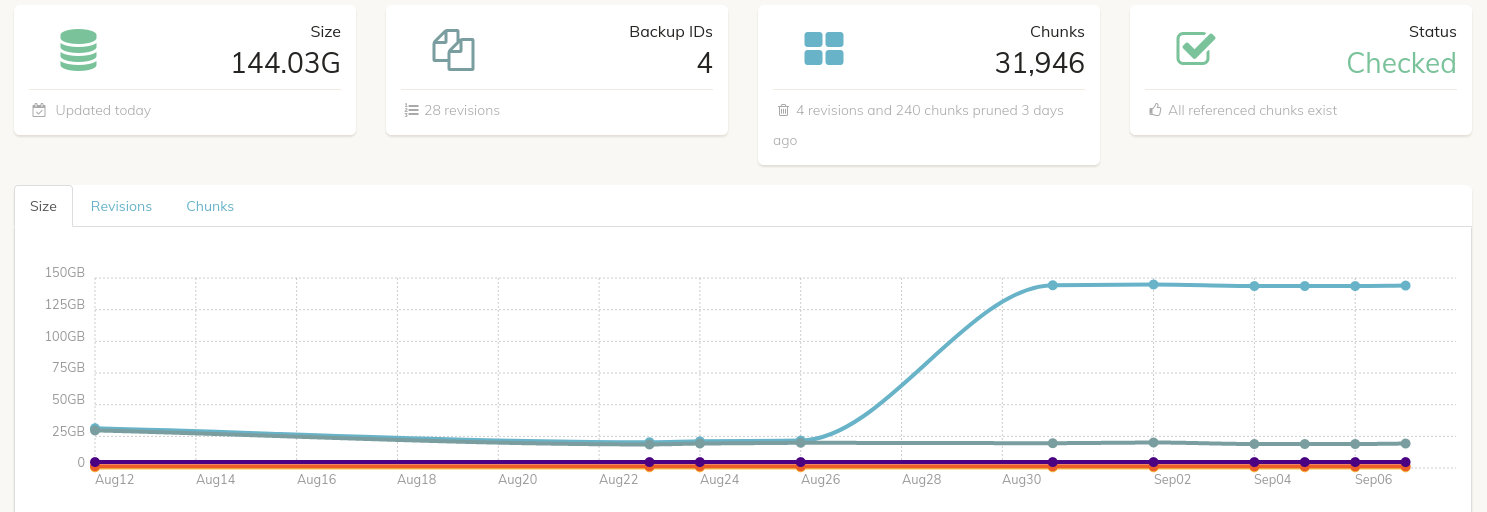
I guess there was an aborted backup which left a lot of unreferenced chunks. You can run a prune job with options -exhaustive -dry-run to check for unreferenced chunks.
Thank you! The -exhaustive command deleted all those unreferenced chunks. Seems obvious now.
Hmm. It is it obvious at all to me. If the backup was aborted and then re-run the same chunks would have been uploaded on that next run.
The only scenario that comes to mind is if you started backup of completely new dataset to the same destination and aborted it. Was this the case?
I guess it isn’t obvious as to the cause, just what got it to cleanup those files.
If I remember around this time, I had a Docker container (mealie) that created its own backup that was extremely large (300 GB or so) and pretty much made my server unresponsive. I had to disable the entire docker service to figure out what was going on, and maybe duplicacy was attempting to backup that seemingly corrupt database at that time.
1 Like
Ah, that is indeed plausible explanation. thank you.
BTW do run check after that prune, just to make sure nothing extra got deleted.
This topic was automatically closed 10 days after the last reply. New replies are no longer allowed.