
I’m curious to know where you can get storage for $1 per TB per month?
I’m using Amazon Glacier Deep Archive, however duplicacy does not (yet?) support archival storage.
I never expect to need to do a full restore from that backup, hence cost of the full restore is irrelevant (it can be significant, due to the nature of this storage tier). Cost of small restores under 100GB/month – is zero, this covers day to day use, if necessary (which is rather unlikely too).
Thx for the quick response. I see, yes that is indeed quite cheap, but would it be suited for something like User directory backup without good filtering. Where there’s many small files changing everyday?
Number of small file changing does not matter in the end – they are all collected into a long sausage that is then sliced into chunks.
I can describe my usecase:
I backup (with another backup tool) my entire /Users folder (about 3TB in size) without specifying any exclusions, other than exclusions by Time Machine attribute, responsible for that half-a-terabyte difference, daily. Most of the transient stuff is handled by Time Machine exclusions, and few misbehaving apps don’t amount to enough data to bother with writing additional exclusions.
There are 4 active users that are being backed up (not all use this specific Mac, but their data is nevertheless synced via iCloud form other machines.
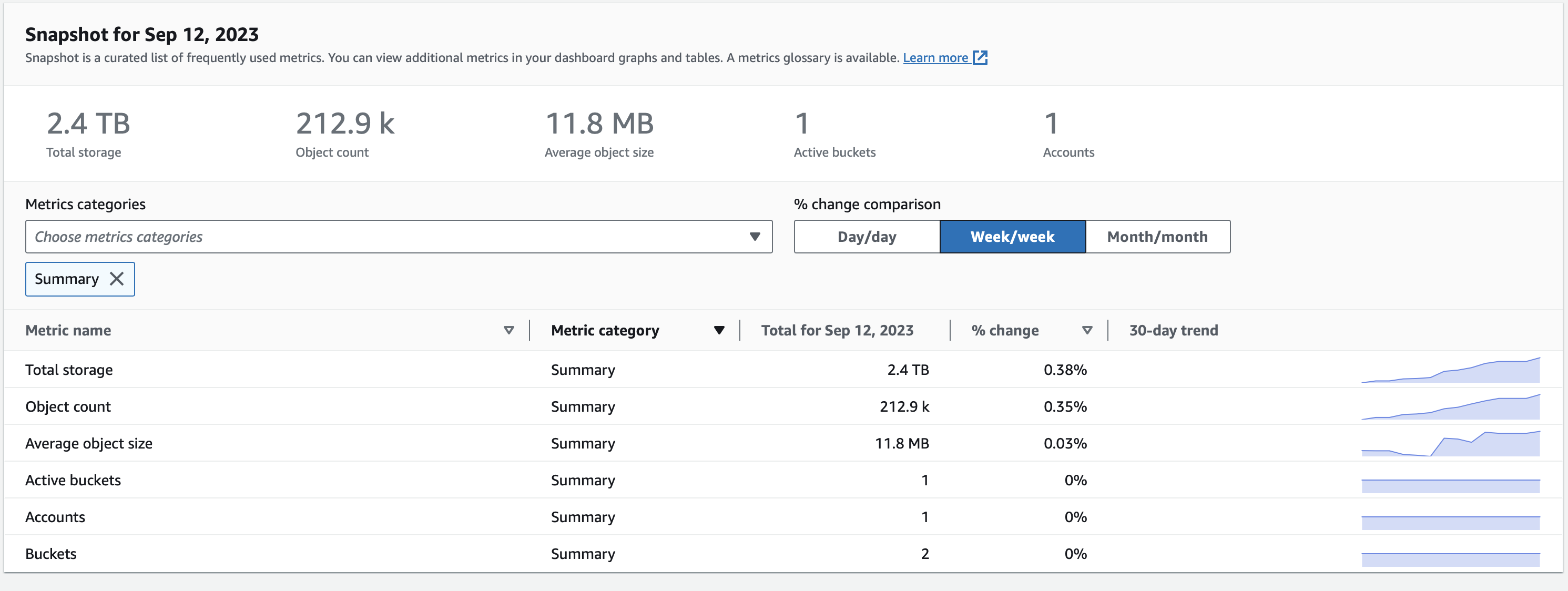
so week over week increase is 0.38%. And vast majority of it is high bandwidth videos and photos.
1 Like
Prior discussions:
So it appears that it is possible to do backups with duplicacy to glacier, provided you manually set different storage class on config file, and always backup with -hash flag.
Next best thing would be if separate folder for metadata chunks is implemented, so they can be stored in hot storage, and avoid the need for -hash flag.
Restoring, however, will be pretty much impossible without implementing more support in the duiplicacy itself – generating the list of files to thaw, thawing them, and then proceeding with the backup will need to be implemented.
Until that is done, users have to pay 4x for storage (STORJ being the cheapest supported storage provider today)
Thank you for the detailed write-up. Very informative. I’m currently reevaluating if I should stick with Google Drive with Enterprise Basic or switch to an alternative.
If Google drive works for you – keep using it. As the saying goes “not broken – don’t fix”.
Google drive is the only “drive” provider that happens to be robust enough even in this weird use-case (few folders with massive number of small files). It may not be as cost effective as it used to be, but if you already happen to pay for the subscription, using unused storage for the backup makes it essentially free. And free is hard to beat…
Just don’t use the Shared Drives – there is a limit of 400,000 objects per shared drive that is very easy to hit with duplicacy.
1 Like
While it can’t beat $1/TB/Month, IDrive’s E2 comes pretty close if you pay annualy and seems hard to beat for hot S3, especially when you consider that there are no egress fees (unless you download several times your storage allocation). Perhaps I’m missing something here?
If I’m not mistaken it comes out to $1.67 / TB / Month (or $20/TB/Year).
Worked pretty well last I tried it. Both upload and download.
I’ve had good luck with IDrive E2 as well, but I’ve only been using them for about 6 months.
I personally recommend staying far away from idrive. Review this thread: IDrive e2 now integrated with Duplicacy - Fast S3 Compatible Cloud storage
Saw that thread before, but it looks to be improved since then. Personally I’m still fine with it, but I have two separate cloud backups from two separate software (I use E2 with Arq and B2 with Duplicacy for redundancy), but it’s a good thread for others that are using E2 exclusively.
That’s not the point though. What has been improved? Did hire more support? More QA? More reliability engineers and architects? Changed how they operate?
The point is that the company is competing on price, cuts corners, and when something happens — is unable or unwilling to resolve the issue.
This is one of those cases when just one negative testimony is enough. With iDrive is not an isolated incident either. Search iDrive on this and other forums.
If you hope that it will more or less work for some time — that’s fine for storing active files and sync. But backup shall be rock solid. Backup to iDrive is anything but.
Honestly, I would not trust B2 for backup either. They allow issues to happen that are not acceptable at this stage of product maturity. But then again, company is operating on thin margins, that have never been profitable in its entire history since inception, and is willing to lie to customers (the whole “we never accepted any cent of outside investments, and yet their sec filings tell different story) — your data is not priority. Making ends meet and hyping stock price is.
Do you trust any of them not to tweak erasure coding to reduce cost at the expense of increased risk to customer data? Oops is Daisy, your file rotted, sorry about that, here is refund.
In fact, in spite of my general hatred towards Wasabi, they are one of more suitable ones as backup destination out of the usual suspects people are considering today. Their cheapest storage tier is aligned with backup type scenarios — long minimum retention (3month) and capped egress. And they are profitable today.
Don’t use them for backup. Instead, use large established companies. Those that banks and large institutions use. Otherwise it’s not a backup, it’s a feel-good illusion of one. You should be able to restore a file 15 years from now. I guarantee you this is not happening with iDrive.
Anyway, I’m grumpier than usual, feel free to ignore the whole write up, but the general idea still stands. Backup shall be long term, and ultra reliable. Therefore all those small players are non-starters.
1 Like
Thank you for sharing your views @saspus. I quite enjoy your grumpy posts. 
As a tech-enthusiast I think I often fall victim to my own need to tinker and optimize (be it space or cost or whatever is shiny and new) and I tend to change cloud providers and backup software more often than I should.
Edit:
I do sometimes wonder how IDrive is able to offer such “too good” pricings… Does anyone have any actual insight into their operations? Do they self-host or use AWS?
1 Like
I hear you, but as you kind of eluded to, most low cost storage providers that consumers will use have tradeoffs and issues at some point (which is why I have two separate backup programs sending to two separate cloud storage companies).
IDrive E2 is cheap enough as a secondary cloud backup for me that I’m not too concerned about their previous challenges when they launched. Ironically, I actually migrated to E2 from Wasabi after some Wasabi bucket issues that they were unable to resolve in a timely enough manner.
Out of curiosity, aside from E2/B2/Wasabi, what would you personally consider a good consumer option for backing up?
1 Like
I had the same experience with wasabi few years ago. It never worked for me properly either. But hey, it was cheap Which sort of reinforces the point
I feel that my data is more important that what financial institutions are storing on cloud providers of their choice, Banks are insured. My photos on the other hand are irreplaceable. So I want solution more reliable than what banks use. I don’t want tradeoffs. I want the very best. It’s therefore clear that all those iDrives, pclouds, wasabis, and backblazes won’t cut it. The choice is really AWS, Google, or Azure.
Paying for two Mediocre solutions is not really an option either – I’d rather pay slightly more for a much more reliable one. Because these small providers are in the rat race to the bottom, even a tiny increase in price buys significant improvement in reliability.
Now what tier of storage to buy. While I do want the very best storage – I don’t want to pay through the nose.
It turns out, the storage tiers that are expensive – are expensive for their properties and performance characteristics that are irrelevant for the backup use cases. You don’t need sub-ms access time and ridiculous on-demand throughput. Nearline and cold storage will do just fine. Even archival storage will do great – like Amazon Glacier and Glacier Deep Archive. Amazon specifically recommends those to tiers for backup applications. The storage cost compared to hot storage can be 20x less. Cost of restore – can be 200x more. But when you multiple this by the probability of needed to do full restore – it goes back to being negligible.
Duplicacy does not support archival tier unfortunately, (hopefully, yet). So I’m forced to use use a third party backup tool that does support Amazon Glacier Deep Archive. I’m storing about 2.7 TB there and pay about $3/month. Occasional restores are free, up to 100GB per month.
Even the cheapest hot storage tier would cost me at least 4x more.
With duplicacy options are limited to hot and nearline storage.
There is another kid on the block though, unlike any other. storj.io, that I have been low-key testing with duplicacy and tools like Mountain Duck for the past year.
It is an interesting project that uses underutilized resources on existing servers all across the world to provide cheap, distributed, end-to-end encrypted, extremely fast (because you are always close to some nodes, the whole network behaves like a huge distributed CDN) storage. It’s $0.0004/GB/Month to store and $0.007/GB to egress.
So answering your question – that’s what I would recommend for home users. My experiment using it with duplicacy so far it has been flawless. Not a single issue related to data integrity, availability, or performance. I did hit technical limitations of my cable modem when upping parallelism way too high – the protocol involves creating a lot of peer to peer connections and the cable modem just has a stroke. There are ways around it of course, like increasing average chunk sizes, and/or using S3 gateway, but it’s noteworthy that it’s the first time I hit that limit.
I need to find time to write the “lesson learned” type of post to increase awareness and have some sort of tutorial for newcomers. Best backup program meets best storage 
2 Likes
Thanks for sharing your thoughts!
Interesting that you’re gravitating towards storj – I’ve seen recent discussions from people providing storage to storj looking to back out given the inadequate payment structure they get, so I’m personally not convinced that storj has a long-term business model at this time (at least as it stands today), but it’s definitely something I’ve wanted to at least try out, even just the free tier for my experience.
Just to clarify, I personally do this not because I use E2/B2, I do it primarily because I do not place all of my remote backup trust exclusively to just one software or cloud destination (i.e. I’d be using two cloud storage providers no matter who I use).
1 Like
That’a a very vocal minority of thoroughly confused folks with expectations unburdened by reality. Storj is not meant to pay for hardware, maintenance, and take their kids through college. If it was possible to make renting storage profitable – storj could rent servers on their own, in bulk, at much better prices, cutting out the middlemen. Backblaze does something even better – run datacenter themselves, on scale, and they are yet to make profit.
The point of running a node is to make use of underutilized resources on existing, already running servers. Resources, that would go to waste otherwise. Nobody sizes hardware exactly for their needs for today. There is always a buffer. If you anticipate that you’ll need 20TB of storage next year, you’ll buy drives and configure pools for 40TB of space. And at the end of the year, add more capacity if you used more than you anticipated. There is always extra idle capacity all over the world.
So the question is not whether I can sell my storage for profit, instead it is a trivial choice a) let it sit idle - disks spinning, CPUs running, electrical meter counting, or b) run an app to share that extra space and get compensated something, for doing virtually nothing.
Storj keeps repeatedly reminding their small node operators not to buy hardware specifically to storagenode use, but people do it anyway, they think it’s some sort of crypto get rich scheme (but token!!!), and then whine on forums that the revenue does not pay for the hardware, electricity and their time. To run storage node you really need a good performant array that can handle millions of file with very low latency. Slapping USB HDD onto a raspberry pi won’t take you far.
In other words, your “investment” is 15 minutes of your time to set it up (guide contains 3 steps) and return on “investment” is steady passive income every month. As time passes, the profit, expressed in percents, approaches infinity, at any compensation rate.
If anything, I think they still pay too much.
Personal anecdote. My home serfver is on 24/7 for past 10 years. Its primary role is my and friends and family backup target. It has a high performance redundant ZFS pool, enterprise disks, special device on intel datacenter class SSDs. (all purchased used on ebay btw). CPU utilization is almost never above 5%. Today I have about 30TB of free space there. About 14 months ago I have allocated that unused space for storagenodes. Today whatever storj pays, almost completely covers cost of electricity the server consumes in the HCOL area I live every month. Without running the node I would be paying that cost myself anyway. I consider it 100% profit. That thing runs and I never have to maintain it.
Expecting the node to pay for the server, drivers, maintenance, and profit on top is just completely unrealistic.
But that is the perspective of some random dude, me. I know at least two small/medium datacenter operators that run nodes on their spare capacity. Same reasoning – servers are spinning anyway, might as well do some good and offset some costs.
Then there is non-monetary gratification of not wasting resources, offsetting need for extra capacity being deployed elsewhere, yada yada. I would be running a node even if it paid nothing. Actually there used to be a project over a decade ago, called Wuala, that allowed users to share space peer to peer. It was poorly managed, and ahead of its time. Storj is doing a solid job.
But I digress.
Understood. I don’t think amazon is going anywhere and I don’t think risk of them banning my account out of the blue justifies paying double. I do have a second (first, actually) local backup with long version history anyway. So I guess that’s the second destination similar to what you are doing. Plus all data lives on a cloud anyway, so if I lose all machines, local backup, and amazon bans me – I still have my data in its current state.
To be clear, I happen to do that, but for different reasons. Data lives on the cloud because I have a lot of computers and devices I need it to accessible on. I backup to local server because I already have the local server for other needs. So essentially amazon is my only dedicated backup.
I perceive risk of losing data on amazon (be that due to Yellowstone eruption, or fat fingers banning by account) to be small enough, to not be worth lifting a finger. But I agree, this is a personal decision, and does not have to entirely rational. We are talking few bucks per months. If backing up to second cloud lets someone sleep better at night – it’s a very cheap solution to increase quality of sleep, I’d say go for it
1 Like
I’ve also been migrating my backups from Wasabi (yes, hot, saspus don’t read this  ) to Storj over the last few months, and so far without any problems.
) to Storj over the last few months, and so far without any problems.
I was also a Wuala user, I had noticed the similarity of the approach, but I didn’t know it was the ancestor of Storj
I mean, it isn’t, it’s just was based on the similar idea.
BTW, on the iDrive conversation. Here is another reason: Exhaustive prune on idrive e2 deletes needed chunks