If you don’t run (or plan to run) very large datasets with  (we’re talking 10TB+) and/or not someone who doesn’t look into/make changes to codebase, you can probably ignore this thread
(we’re talking 10TB+) and/or not someone who doesn’t look into/make changes to codebase, you can probably ignore this thread  This is mostly to discuss some implementation details with @gchen (really hope to see some feedback here) and whoever else is interested in improving code. Hopefully, based on this discussion we can make a PR to be merged into mainline. So here it goes.
This is mostly to discuss some implementation details with @gchen (really hope to see some feedback here) and whoever else is interested in improving code. Hopefully, based on this discussion we can make a PR to be merged into mainline. So here it goes.
There was a post not a long time ago by @Shaun, who wanted to use with hundreds of terabytes, if not petabytes, of storage, and it seems that no one really knows how it would behave on that scale. That got me thinking about profiling for large datasets, as I have one that is reasonably robust for that purpose. Here is an overview in a nutshell (numbers are rounded):
- 20TB storage on OneDrive
- 4mm of chunks (default sizing)
- 7 snapshot ids
- 1000 revisions (total, not per snapshot id)
- Mix of file sizes, from many small(er) ones to fewer large ones
- duplicacy codebase is branched off 24c2ea7 (so a bit after 3.1.0)
Current setup is perfectly viable, but I want to make sure that it still is if we push the scale up one order of magnitude, so ~200TB/40mm chunks/10000 revisions. Given my observations so far, this would be problematic in the current version, but can probably be addressed without making extensive changes to the code. Pushing into petabyte territory (so 2 orders of magnitude up) will likely need much more extensive changes, so this is out of scope for now.
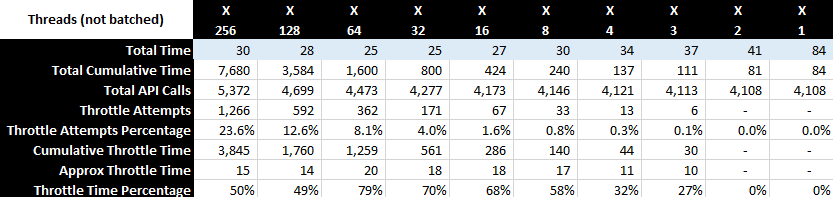
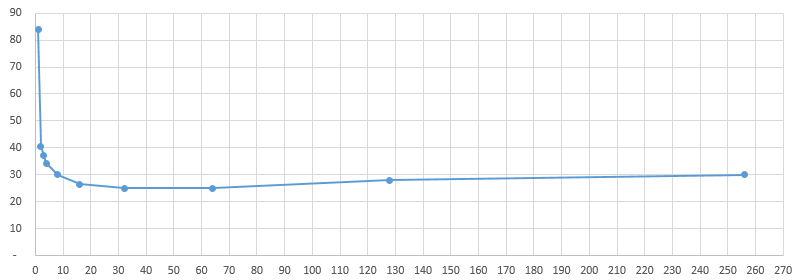
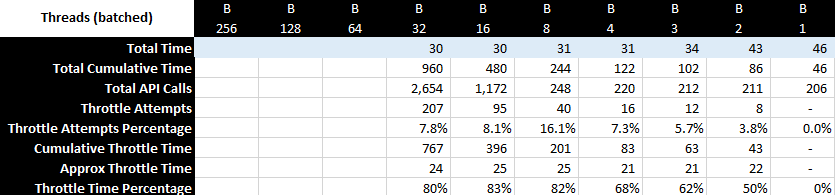
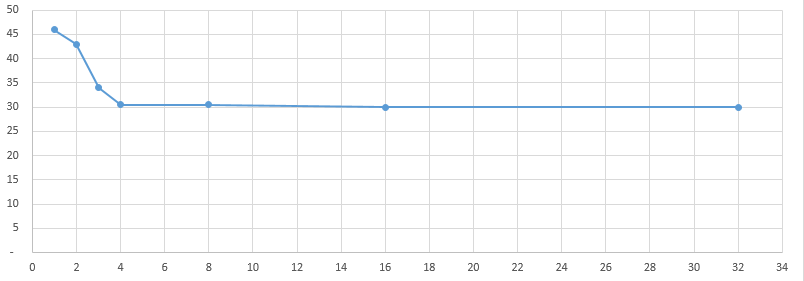
The idea is to look for some low-hanging fruits to make performance noticeable better for large datasets, at least for the most common usecases. There are 3 metrics that roll up into performance: memory consumption, execution time and disk space (caching/temp files). IMO these are in general priority sequence, as exceeding available memory makes it a hard stop for a particular usecase (physical memory is limited, even swap often is), or makes it unbearably slow (even with swap certain operations that require random access would be non-viable). In this context longer execution times can often be tolerated within reason as it rarely leads to hard stops. And disk space for caching/temp files is likely the least of a concern (again, within reason).
Now, for the good news. In my current setup incremental backup has excellent performance characteristics out of the box. I don’t see any significant memory load, execution times are really fast even on a lower-power box and best of all, given what I know about , there is no reason to believe that blowing up the dataset by 10x will make things significantly worse. This is excellent news, considering that this is the most common operation out there. I see no reason to do any additional optimization in this part of functionality, really happy how it works.
Restore functionality is important, but is rarely if ever used, so I haven’t looked into that. Unless memory consumption blows up (it shouldn’t for restore), performance is unlikely to be critical.
Which leaves us with 2 other components where you can foresee issues: check and prune. Prune is something I will look into later as I rarely run it, but check I like to run after every backup (so daily). So let’s take a look at check functionality (to be continued).
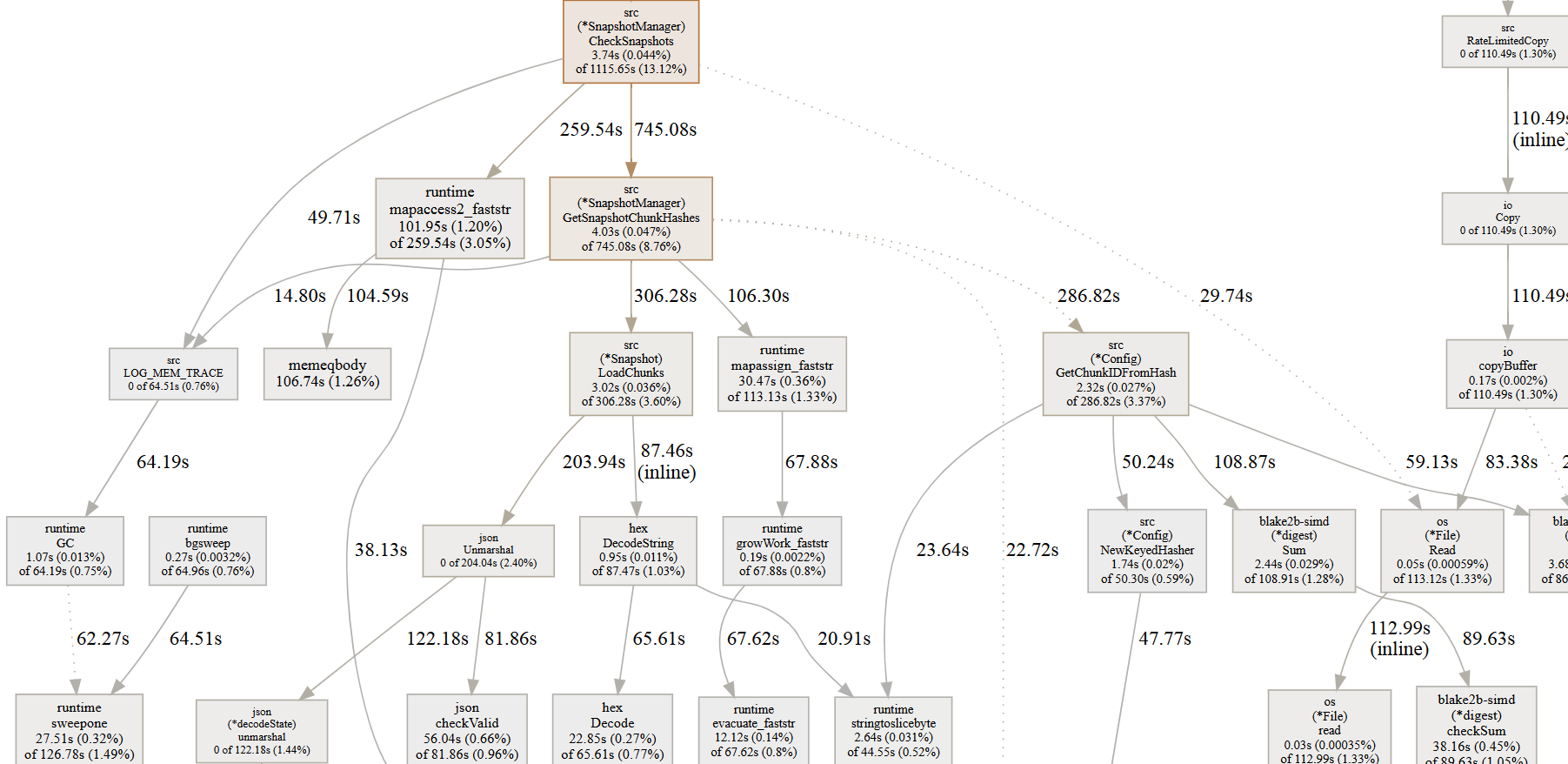
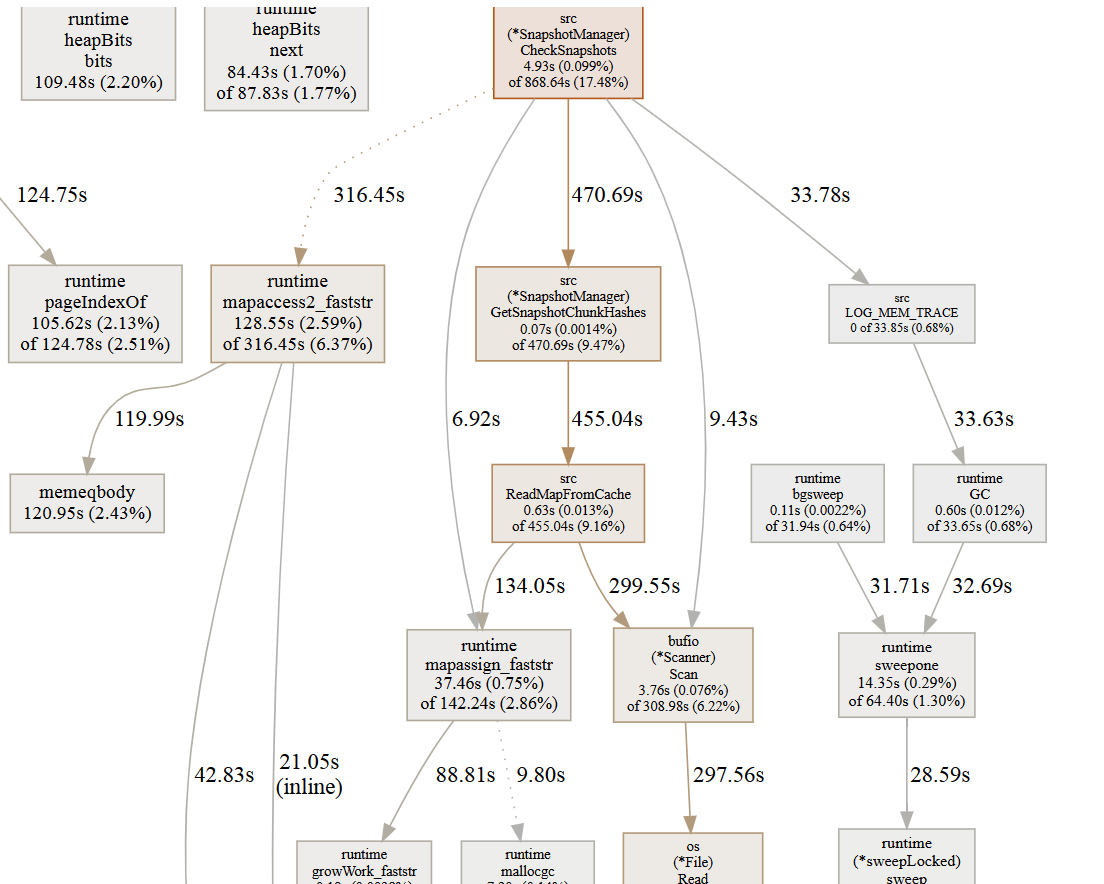
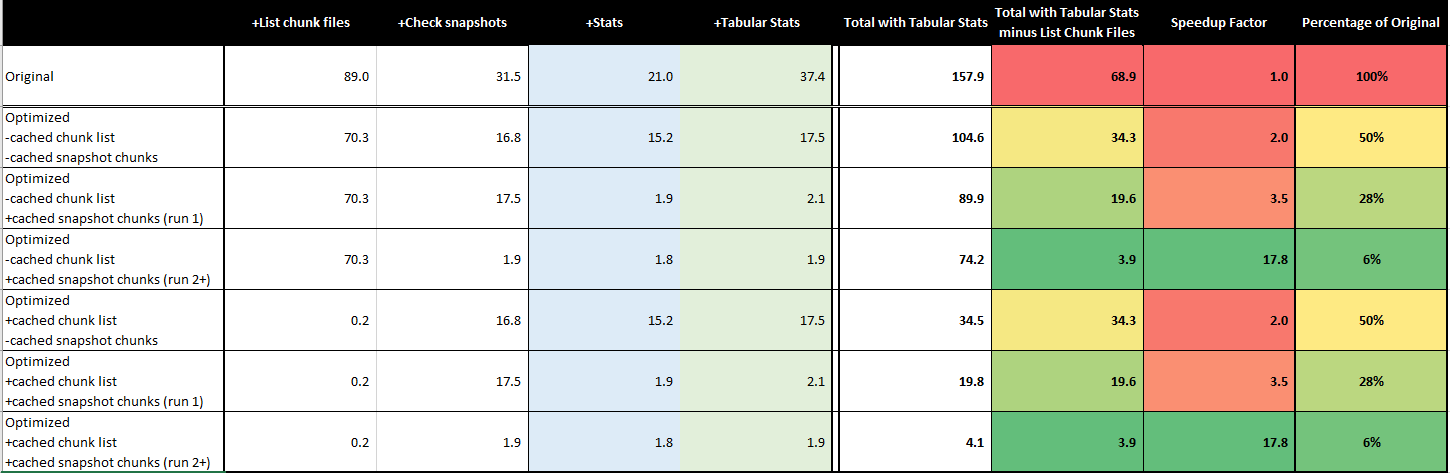
 Am aware of the scalability issues, regardless of backend, but the point I was making is that simply listing files is really one of the big pain points that could and should be solved universally.
Am aware of the scalability issues, regardless of backend, but the point I was making is that simply listing files is really one of the big pain points that could and should be solved universally.