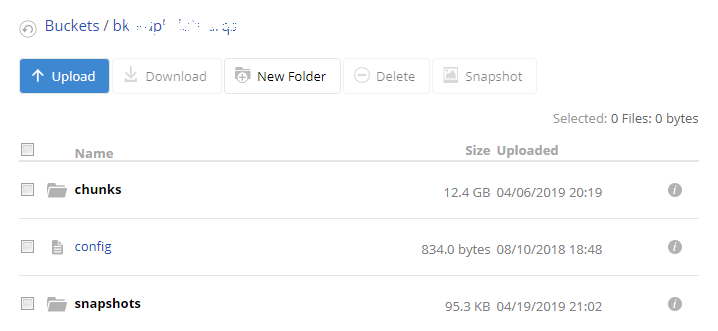
In a bit more detail, what you’d do is first create a new empty folder for the repository. Or, if you’re restoring files to a fresh but existing file structure, use that instead.
(Although be mindful that, restoring - say - a Windows user profile directly into a new Windows install, very probably wouldn’t work cleanly or as expected. That’s hardly a limitation of Duplicacy though, so be prepared for a bit of manual intervention after a restore, and I’d advise restore to a clean folder structure anyway.)
Then you’d:
cd "D:\Restore"
duplicacy init -encrypt <snapshot id> b2://bucketname
duplicacy set -no-backup
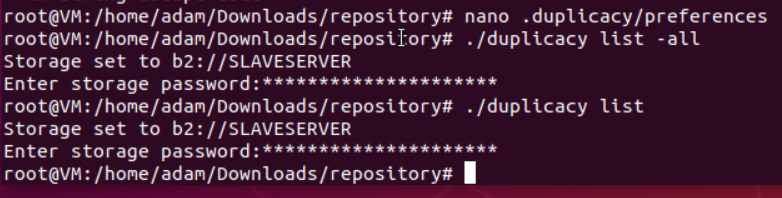
duplicacy list
Instead of list, using list -all will help you identify what revision numbers, but more importantly, what other snapshot id’s are available. Thus if you got the <snapshot id> wrong, you can correct it by editing the .duplicacy\preferences file with a text editor.
For a full restore:
duplicacy restore -stats -r <last_revision>
For a partial restore:
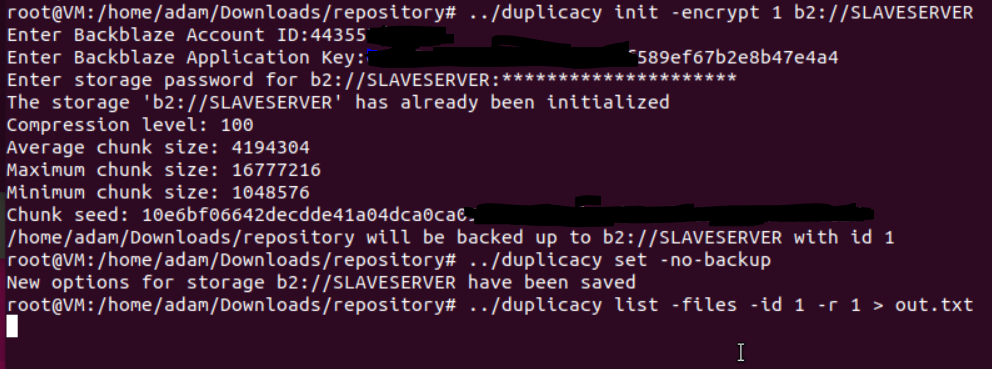
duplicacy list -files -id <snapshot id> -r <revision> > out.txt
Look through out.txt to find the full pathname or pattern for what you want to restore, e.g.:
duplicacy restore -stats -r <revision> "AppData/Roaming/Thunderbird/Profiles/zyxwvuts.default/*"
You can do all this armed with only the B2 url and storage password.
Give it a try - create an empty folder structure and test the process out for a restore. (Careful not to restore over your existing repositories.  )
)


 Which is odd, because I set them, using the
Which is odd, because I set them, using the  However,
However,