
If you don’t see a log message “Incomplete snapshot saved to”, then it means Duplicacy isn’t getting the Ctrl-C signal. I’m not sure if PowerShell would pass the signal to Duplicacy when it is running inside a script, but if you run Duplicacy from the command line it should get the signal.
1 Like
I’m not running it as a script. I’m running it directly from the powershell command line.
1 Like
Today the backup failed/stopped because the destination drive became unavailable. I’d assume that in this situation duplicacy had all the time in the world to write the incomplete snapshot, but it didn’t:
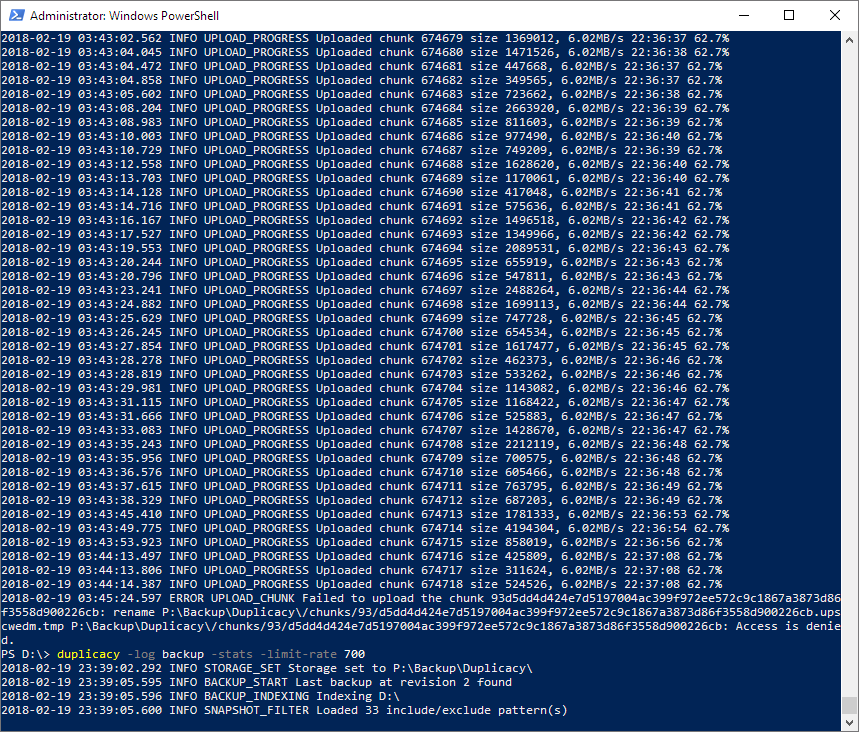
Now it will have to skip chunks again for hours. Is there any way I can get it to save the incomplete snapshots?
2 Likes
Any change you’re not running the latest version?
1 Like
It’s one of the v2.1.0 betas. Not sure if it’s the latest one though. Does it matter which beta?
1 Like
Sorry, I forgot the partial snapshot file is saved for incomplete initial backups only. After the initial backup is done, it always uses the last complete backup as the base to determine which files are new. So if you add a lot of new files after the initial backup, you won’t be able to fast-resume after the backup is interrupted.
1 Like
Oh. Well, that is bad news. Why are incomplete snapshots not saved for subsequent backups?
I have about 1 TB of data to back up and for various reasons, that won’t go through without interruptions. Without incomplete snapshots, I lose several hours every time during which duplicacy just skips chunks. And as the backup progresses, the longer that waiting time becomes.
May I suggest that in v2.1.0 this limitation to incomplete snapshots is taken away? Or if there are some serious downsides of that, to at least make it available as an option, -save-incomplete or something?
2 Likes
This is really becoming a major issue for me.
What if I delete the first two snapshots? As a work around, will duplicacy save the ongoing incomplete snapshot again? If so, would duplicacy prune -r 1-2 -storage <storage url> be the correct way of doing this? Or should I just delete the two files in the snapshot folder? (I obviously don’t want the chunks to be deleted, only the snapshots.)
1 Like
You should manually delete the two files 1 and 2 under snapshots/snapshot_id in the storage.
1 Like
OK, I have done that, but assuming that duplicacy checks for the existence of previous snapshots at the beginning rather than at the end, this will only become effective the next time I start the backup command, right?
Just to give you an idea how serious a problem this behaviour of duplicacy is: It currently takes around 24 hours for the backup to resume actual uploads, i.e. it is skipping chunks for a full day. I really don’t see what the point is of limiting incomplete backups to initial backups only.
2 Likes
Is this problem fixed in 2.1.1? Did I get it right the resuming is only possible for initial backups?
No, resuming is always possible. But with initial backups duplicacy knows which chunks it can skip and the actual upload resumes much faster than when subsequent backups are resumed (because duplicacy has to “rediscover” every time which chunks have already been uploaded.
For smaller backups, this doesn’t really matter, but with larger ones, like I had, it can take a full day or longer until the actual upload resumes (i.e. duplicacy spends 24 hours just skipping chunks).
1 Like
Oh, wait. I now see you were probably referring to this:
And now I’m not sure anymore. My understanding was that while windows may produce additional reasons for the incomplete snapshot file missing, duplicacy by design only attempts to create it for the first snapshot. Is this correct @gchen? If so, could this behaviour be changed?
2 Likes
Is this translated into the Web GUI version as well? Having an API within the CLI for the GUI to communicate with would fix the problem right? If the GUI sends a request for the CLI to gracefully stop.
Are Signals not supported with killing processes in Windows?
Like a graceful terminate that allows the process to close on its own. If I press the stop button in the Web GUI in version 0.2.7 and restart, it ends up scanning what seems like from the beginning of the drive and takes hours on the initial backup before it starts uploading again. For someone with terabytes to backup, it would require them to leave their computer on for days to avoid a long rescan before it starts uploading.
1 Like
I’ve recently added a bunch of data to my existing backup and it’s now taking about a month to catch up. In the meantime, any time I need to reboot, or any power failure, results in it spending hours scanning files to see where it is.
Is there any way the “incomplete” behavior could be extended outside the initial-backup period? Say, write an incomplete file every hour, delete the incomplete file with a successful backup.
5 Likes
Adding my experiences to this thread which I assume stem from the same issues in Duplicacy handling incomplete backups…
Same issue here, it still hasn’t been fixed in the latest CLI version (2.4).
I did a first test backup excluding large folders with filters. Once complete, I have removed the exclusions (hundreds of GB) but running a subsequent backup is taking hours just to skip chunks Duplicacy should know have already been uploaded. Since Duplicacy also does not seem to have any retry logic, the backup process is back to square one each time there is a network disconnection or I put my computer to sleep.
There is really no reason not to write the incomplete file at all opportunities (e.g. after each chunk), so the backup process can be efficiently resumed. This is a low hanging fruit, I hope it gets implemented ASAP (but I am not very optimistic considering that the issue was raised in 2018  ).
).
This isn’t accurate. It doesn’t retry for any and all possible errors. But it does retry with exponential backoff for errors that can safely be considered non-fatal.
1 Like
It definitely doesn’t retry with Dropbox non-fatal errors (e.g. network related), from what I can tell.
I don’t think network connectivity errors currently fall into the bucket of typical rate limiting type errors that duplicacy would retry, so I wouldn’t be surprised.
Depending on the error it might be possible to add retry behavior. And it may not be as simple as retrying the last operation. If the connection is being lost it would probably need to also try to reinitialize the connection to the storage.