Hi all! I am trying out Duplicacy to see if it can become my backup tool, it’s been working great for the first few days but a local backup failed overnight and I am not sure what or why this happened, and couldn’t find any other posts with the same error message.
Please describe what you are doing to trigger the bug:
A scheduled backup and accompanying check to a local secondary hard drive failed, citing that a chunk hash isn’t a valid hex string. I tried re-running things just to see if it was a timing issue or just a hiccup, but I’m consistently getting this error and both backup and check tasks fail to complete. Here are the logs for the failed backup command:
Running backup command from /cache/localhost/3 to back up /storage/8TB
Options: [-log backup -storage 8TB-backup -stats]
2020-05-10 08:50:21.621 INFO REPOSITORY_SET Repository set to /storage/8TB
2020-05-10 08:50:21.621 INFO STORAGE_SET Storage set to /storage/8TB-backup
2020-05-10 08:50:26.125 ERROR SNAPSHOT_PARSE Failed to load chunks specified in the snapshot 8TB-backup at revision 16: The chunk hash f728d630253c47554b578edb355db404555f0fa08fff31ebf2d7fc85;7dc657b is not a valid hex string
Failed to load chunks specified in the snapshot 8TB-backup at revision 16: The chunk hash f728d630253c47554b578edb355db404555f0fa08fff31ebf2d7fc85;7dc657b is not a valid hex string
And the check command (trimmed somewhat for reading convenience):
Running check command from /cache/localhost/all
Options: [-log check -storage 8TB-backup -a -tabular]
2020-05-10 08:50:26.169 INFO STORAGE_SET Storage set to /storage/8TB-backup
2020-05-10 08:50:26.184 INFO SNAPSHOT_CHECK Listing all chunks
2020-05-10 08:50:30.030 INFO SNAPSHOT_CHECK 1 snapshots and 16 revisions
2020-05-10 08:50:30.048 INFO SNAPSHOT_CHECK Total chunk size is 5398G in 1136748 chunks
2020-05-10 08:50:34.425 INFO SNAPSHOT_CHECK All chunks referenced by snapshot 8TB-backup at revision 1 exist
2020-05-10 08:50:38.264 INFO SNAPSHOT_CHECK All chunks referenced by snapshot 8TB-backup at revision 2 exist
(...snip...)
2020-05-10 08:51:23.214 INFO SNAPSHOT_CHECK All chunks referenced by snapshot 8TB-backup at revision 14 exist
2020-05-10 08:51:26.961 INFO SNAPSHOT_CHECK All chunks referenced by snapshot 8TB-backup at revision 15 exist
2020-05-10 08:51:28.572 ERROR SNAPSHOT_CHUNK Failed to load chunks for snapshot 8TB-backup at revision 16: The chunk hash f728d630253c47554b578edb355db404555f0fa08fff31ebf2d7fc85;7dc657b is not a valid hex string
Failed to load chunks for snapshot 8TB-backup at revision 16: The chunk hash f728d630253c47554b578edb355db404555f0fa08fff31ebf2d7fc85;7dc657b is not a valid hex string
Please describe what you expect to happen (but doesn’t):
The backup to successfully run and complete, or at least for subsequent runs/checks to be able to fix what might have happened here.
Please describe what actually happens (the wrong behaviour):
The backup and subsequent check fails.
Some additional information:
I’m running Duplicacy 1.3.0 inside a docker container with my machine running 24/7, and I am running Ubuntu 19.10. Both the backup source and destination are local drives. My cloud backup tasks have successfully run and completed, but they back up only a subset of the data the local task.
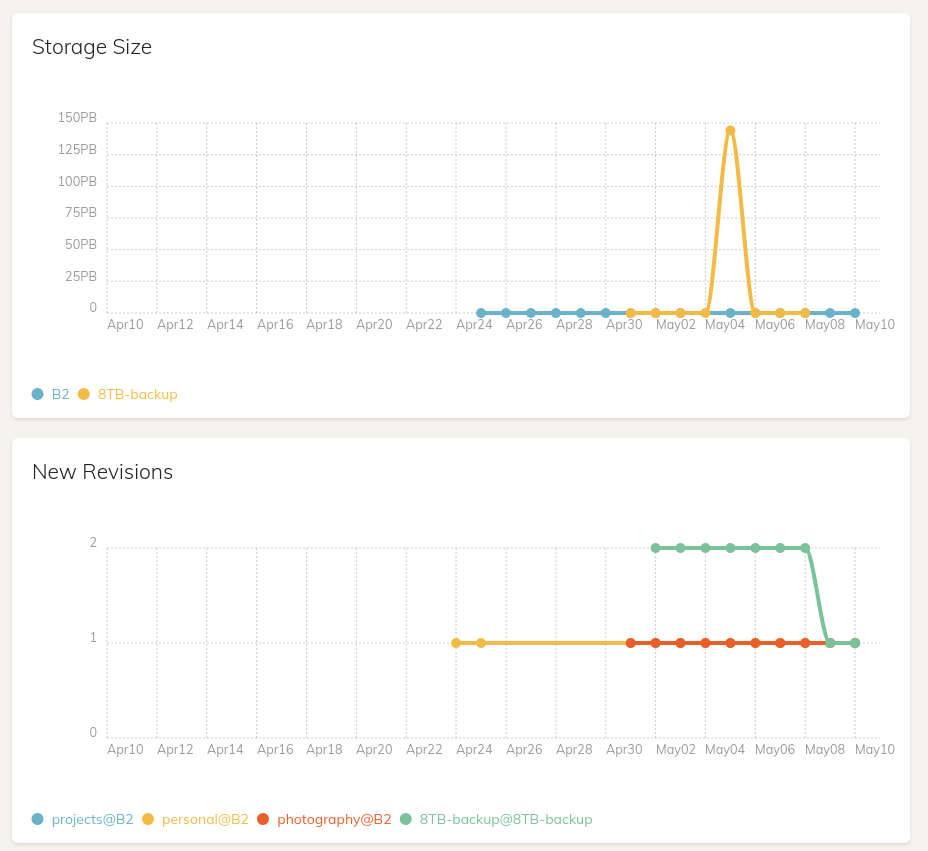
Just a quick follow-up as I just noticed this; My dashboard view now shows a crazy graph with a peak almost up to 150PB (!?). My actual backup should be under 6TB. The new revisions graph also shows one revision is missing, I guess that’s also related to this bug.
That hash isn’t valid because ‘;’ isn’t a valid hex character. That is obviously caused by a bit rot. Can you check under /cache/localhost/all/.duplicacy/cache to see which file contains this hash string? The easiest fix is to nuke the entire cache /cache/localhost/all/.duplicacy/cache and run the check again, but you may want to save the corrupted file first, so you can compare it with the regenerated file once the check runs to completion.
I checked and the invalid hash does not show up anywhere in the cache. I tried searching both for the entire hash ( ; included) as-well as just the part before the semicolon, but nothing shows up. Manually reading through the `snapshots/8TB-backup/16 JSON file also shows a list of seemingly good looking hashes.
Does the Duplicacy web UI use its own caching for hashes that could end up with a corrupted or badly parsed hash by any chance? As the files themselves seem to be fine. I have not yet restarted the container, mostly also because I’d like to understand why this happened in the first place (and honestly, I’d like to be able to set-it-and-forget-it, not have to remind myself to restart a container every now and then).
I just realized that you’re using a local storage so caching is disabled. That means the bit rot must happen before calculating the chunk hash by the backup operation. Is this error repeatable?
Yes it’s repeatable. I manually re-triggered the backup and check commands a few times (before posting here, too) but it consistently fails.
I just went ahead and restarted the container, but as can be expected this did not fix anything. Backing up and running a check still fail, and the invalid chunk hash listed is also still the same.
Are there any specific logs or files I could provide that might be of help perhaps?
If I understand this correctly – the hash for the chunk in question comes from a snapshot file, correct (snapshot is binary file, so I’m not sure)?
If that snapshot file is rotten, does not matter how many time you try – it will always fail at the same place when trying to make sense of a corrupted hash value.
Is there any consistency verification for the snapshot files themselves, if anything to detect the bit-rot?
If the rotten hash comes from a chunk file – then the same reasoning applies.
And question to the OP:
What is the filesystem/raid arrangement for the target? Does it provide data consistency guarantees? If not, its highly recommended to use bit-rot aware storage – such as btrfs or zfs, if not for your work drive but definitely for backup drive. Furthermore, you would want to run periodic filesystem scrub to keep data alive, especially when long term infrequently accessed data is involved; otherwise bit-rot that will inevitably happen will stay undetected until you try to restore, and at that point its’ usually too late.
It’s a single drive formatted as Ext4, just like the drive the data is coming from. I basically wanted to use this local-to-local backup as a delayed raid of sorts, with some longer-term preservation in case I (or a tool I use) deletes a file on the primary storage drive that I may want to find back later. I could have just set up a direct RAID with these two drives, but I’d like to be able to use one solution both for local as-well as off-site backups, and it would just add another layer of complexity requiring time and effort. At a larger scale this could totally make sense, but at this data scale a simple local drive-to-drive backup ought to work.
As I only started trying out Duplicacy about a week ago, could this actually be bitrot that’s causing this issue? And if so is there an extra option perhaps that I can enable within Duplicacy to have it work with additional parity files for providing backup recovery or restoration in such cases?
While I could reformat my secondary storage drive to use something like ZFS, this actually gives me concern as it means unless the cloud storage solution is and will keep doing the steps you described, long-term my backups might somehow end up breaking, with (seemingly?) no built-in way to recover recent-most chunks, nor a way for Duplicacy to continue backups after a situation like this happens until presumably files are manually deleted. It means if I were to be away from my home for several days in a row for example, the entire backup might halt, which seems like undesirable behavior.
In case it helps, both drives are still quite new, with the oldest one having been in use for just about 6 months. Neither show any errors or issues with their SMART data, but I know that that’s not a guarantee they are 100% OK.
@saspus there isn’t consistency verification for snapshot files unless the storage is encrypted, in which case a corrupted snapshot file will fail to decrypt. All chunk files are automatically verified by the chunk hashes.
@davejansen you’ll need to remove the snapshot file snapshots/8TB-backup/16 and run duplicacy prune -exclusive -exhaustive to clean up chunks only referenced by revision 16 (make sure no backup is running when using the -exclusive option)
Unfortunately this arrangement does not make things better; instead your data is now subject to twice the risk – once at the source, and then second time at the destination. And there are generally two hardware induced corruptions we are talking about – unreadable sector and bit rot.
With unreadable sectors things are easy: if that happens on the source you fail to read the file. The disk will literally report failure. Then you know which file was that and you can restore it from your second source, assuming that the file on that drive has not been affected by another bad block there.
That behavior, albeit manual, somewhat resembles what raid array would do: encounter read failure on one drive, give up quickly (that’s why one should use NAS or enterprise drives in th raid array, not desktop drives) and let the raid controller (hardware/firmware/or software) to handle that by fetching good copy from the other drives. there is no ambiguity here – drive that reported failure has bad data. the other ones have good data.
The is unfortunately way too trivial and easy to handle failure.
Bit rot is much worse, and for long terms storage it is not a possibility but certainly. When bit rot happens the disk does not report failure. It thinks that the data it returning is correct. If this happens on your source drive – you may or may not notice depending on the type of data. Couple of bits in the movie file likely will go unnoticed, but in a zipped archives of your tax statements – not so much.
When it happens on the drive with Duplicacy datastore – the decryption will fail at the time you try to restore. That’s a bit too late and you don’t have recourse.
To prevent this you need to do periodic archive maintenance – aka scrub – to read and verify all data periodically and fix rotten blocks. More on this later.
Would raid help here in your situation? No.
When two mismatched copies are read from the arrays the controller has no way to tell good data from bad one, so it will assume parity is wrong and recompute new parity. While it could have been entirely possible that in that particular case it was the parity that was correct and data was wrong. It has no way to knowing. As a result Ext4 based raid will with 50% probability be unable to recover, and in those cases will murder the remaining good copy of the block by overwriting it with the bad one.
The solution here is to use modern checksumming, raid-aware filesystem – such as BTRFS or ZFS. Those incorporate raid management and filesystem into one entity and are aware of individual drives and can keep checksums of data and metadata written and therefore when disks return conflicting data they are able to tell corrupted one from the correct one.
Since your backup should be more reliable that your storage data, and since it is supposed to store data indefinitely, BTFS/ZFS with periodic scrub is not an option, but a requirement. Or you can use cloud storage where all that is taken care for for you.
I normally don’t link to YouTube videos, much less long ones, but this one is totally worth watching – the guy explains and demonstrates what happens when bits rot.
yes, bit-rot happens all the time , but most of the time is undetected. Its a silent killer. In this case it happened to be in the metadata had is being checked. Note, finding the rot is while important is not very useful – you still can’t restore your data from the affected chunks.
I’d argue it’s not duplicacy’s job to provide data redundancy and compensate for bad stroage; Storage provider must ensure that what you wrote today is read unmodified tomorrow. Otherwise where will you draw a line? Verify data in the ram? (There is ECC ram for that). Verify CPU correctness? PCIE data transfer?
Even if you did – what if two bits rot? You will still fail. You can’t possibly write data twice and double the storage requirements, while using raid with the correct filesystem will provide you the same protection at a fraction of the cost.
Your backups will break and you will lose data if you don’t use checksumming filesystem. It’s not a matter of if, or even when – its a certanty that it will happen with data you intend to store long term.
The best Duplicacy can do is skip those bad chunks and recover what it can. And I think there is a feature request to make this default behavior as opposed to stopping at first failure.
And thats’ why bit rot is so sneakily evil. It cannot be detected by the drive, you need higher level content aware entity to manage that. With ever increasing data density (and especially SMR disks) that will start becoming much more often.
In the same vein, as it t is way harder than 10x to create disks with 1% failure rate vs 0.1% failure rate, what caused the storage industry to move towards highly reliable redundnat arrays of low reliability drives – the same idea applies here – it’s OK if bit rot happens more often, people will use checksumming filesystem, while reducing the threshold allows to cream way more data into the same physical structure.
The bottom line – there is no way around using BTRFS/ZFS and scheduling periodic scrub.
Good cost effective solution is Synology NAS (the one that supports BTRFS, not all do).
I’m not an expert but I think ReFS is also an alternative acceptable file system (at least when also using Storage Spaces and redundant storage.)
Anyway, in my system in practice it’s been outperforming (both in response time and in hassle in normal use) my NETGEAR NAS.
Also FWIW I’m going to use ECC DRAM in my next laptop. I don’t really have any idea how often that might be an issue but I have seen bitrot in the past with my older laptops, but none recently.
It does appear to be the case, even though I’m also not an expert on Microsoft technologies. But I guess if you run window sever on your storage appliance then its the way to go.
In a laptop that is not that important, unless your laptop happens to be use as a server running high performance database or computations for months.
Recent laptops all have SSDs which constantly runs cell refresh cycles to prevent decay effectively preventing bit rot from happening. Or should I say: they decay so much faster than HDDS that separate maintenance tasks to keep data alive is part of the design; end result is that they don’t rot under normal use. (SSDs are extremely complex beasts; the process that servers user reads and wires is one of the many tasks it’s running all the time and not the highest priority one at that – ), and as long as you use your laptop occasionally these maintenance tasks will keep data alive. If you however remove SSD and shelve it for a year or two – it’s very unlikely that you will read you data back from it intact.
Thank you for your detailed reply and sharing your thoughts, it’s helpful indeed. While I don’t think this is a direct solution to the issue of Duplicacy’s way of handling a situation such as this one (meaning, not being able to recover or continue from an scenario like this without having to take manual steps), I’ll leave that topic be as based on what I understand from the replies it seems like that’s how it is designed to work.
I have been reading up on BTRFS specifically mostly because Ubuntu seems to come with support for this (mostly) out of the box and because I had already dipped my toes a little bit into ZFS a while ago. From what I can gather though it seems like its ability to actually do something about bitrot is only possible only if you have more than one drive included in the setup, as it needs to be able to pull correct data from one of the other drive(s) if it indeed discovers bitrot somewhere.
This, of course, makes sense, but this also means that even if I formatted my backup drive to use BTRFS, I could (or will, as bitrot is a guaranteed when, not if) still end up in the same situation. Other benefits of being aware of bitrot having happened aside, this switch in itself isn’t enough to prevent Duplicacy’s backups from being unable to proceed in a scenario like this. I’ll use the advice you’ve given to try to figure out what might be a good solution for my local storage setup at least.
Not necessarily You can write data with redundancy on a single drive but you will of course pay with double storage consumption. With raid array of multiple drives the cost goes down with the number of drives of course.
Other benefits of being aware of bitrot having happened aside, this switch in itself isn’t enough to prevent Duplicacy’s backups from being unable to proceed in a scenario like this.
Duplicacy does not need filesytem assistance to determine that the chunk is corrupted: bad chunk will simply fail to decrypt. What Duplicacy can do is gracefully skip such unusable chunks during restoring and continue restoring files that are restorable (mostly meaning that those that are assembled from good chunks)
I’ll use the advice you’ve given to try to figure out what might be a good solution for my local storage setup at least.
That depends on the budget, but just for reference, you could go with one of the synology units – DS418 (4 bays) or DS218+ (2 bays); while the best value would be DS1618+ (6 bays, + significantly better build appliance with expansion capability). I use the latter one both as Duplicacy destination, source and host – Duplicacy can run on those devices natively.
The error came up when trying to run the backup task though, not when trying to restore.I would of course understand if things failed due to bitrot or similar reasons at the point of restoration, and having a way to continue-on-error there would indeed be useful if not required. But in my opinion to have it lock up and be unable to continue backing up until manually removing files is not ideal.
Synology devices can be a great choice, especially for small businesses for example, but them being best value is, as it usually is, decidedly subjective. And depending on the country you live in they can also be prohibitively expensive. Regardless, with my current data storage needs being relatively small (6TB total, with less than 1TB considered essential), a NAS feels like an electric screwdriver for a situation that might only need a hand screwdriver, if you forgive the poor analogy. Certainly nice to have, but certainly not the only way.
Slightly more back on-topic: I do think it would be good to at least consider implementing parity file support into Duplicacy. It just seems like a feature that would be incredibly useful to have, especially if it can be optionally configured, so that you could enable it (with configurable coverage setting) for less reliable storage destinations for example. While most cloud storage solutions are fairly robust, the chance of something happening is always there, and having the option to increase data parity seems like a great way to further reduce possible worst-case scenarios. I would personally love to have this functionality and enable it for my cloud/off-site backup, knowing that even in a case where a chunk might be damaged for whatever reason, up to a certain point I’d still be able to recover everything.
But I understand if that is considered outside the scope of Duplicacy’s focus, of course. I just thought I’d mention it here.


 ), and as long as you use your laptop occasionally these maintenance tasks will keep data alive. If you however remove SSD and shelve it for a year or two – it’s very unlikely that you will read you data back from it intact.
), and as long as you use your laptop occasionally these maintenance tasks will keep data alive. If you however remove SSD and shelve it for a year or two – it’s very unlikely that you will read you data back from it intact.