
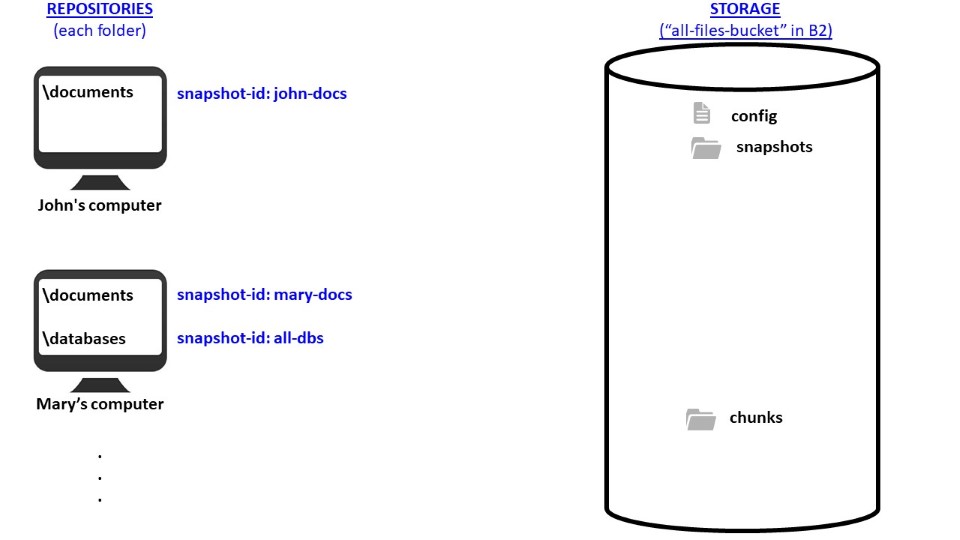
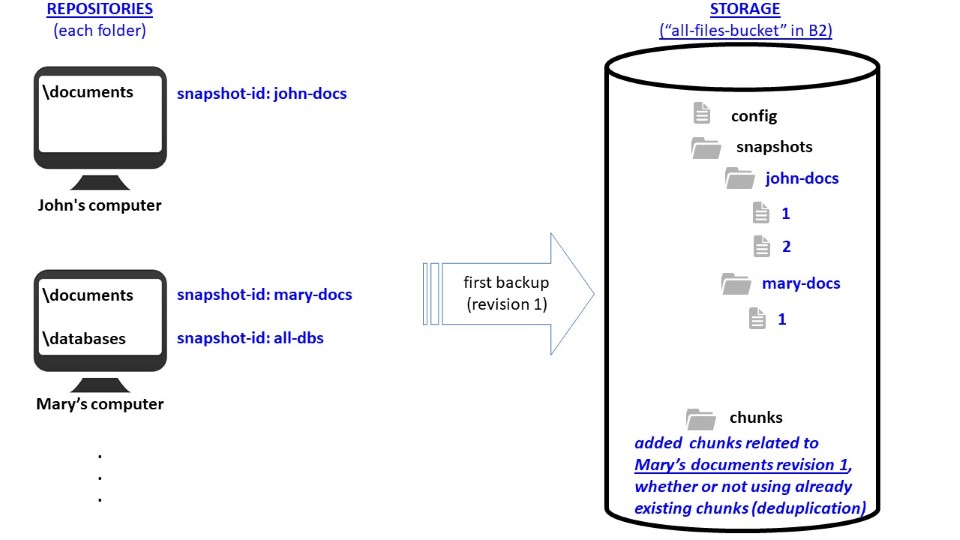
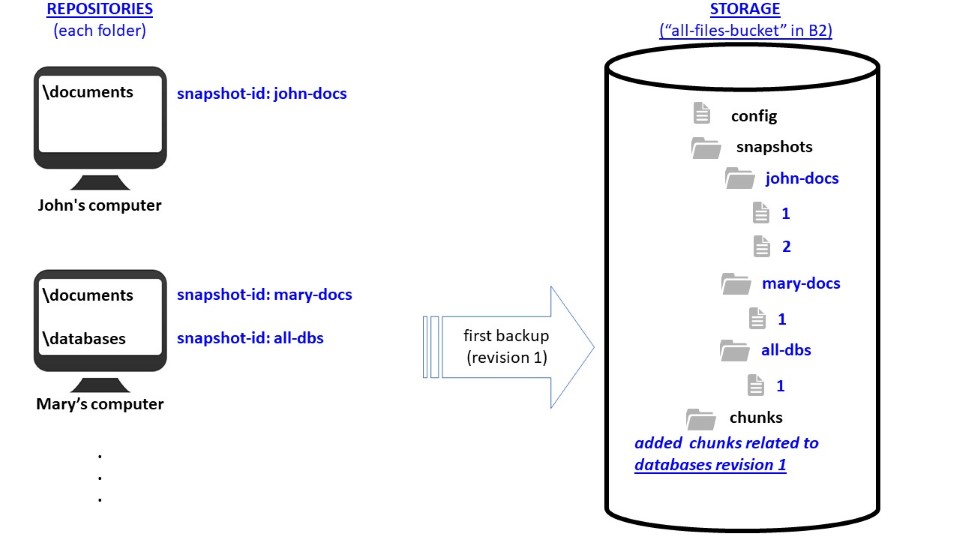
This is an example of nomenclatures used in Duplicacy. This case considers two computers (“John” and “Mary”) backing up to the same storage (a single bucket in B2). Since both computers have “documents” folders, deduplication can save storage space and allow faster backups if the documents used by John and Mary are similar.
This example only covers one configuration use case. Separate storages and different configurations may be used. The purpose is just to clarify how the following terms are used in  :
:
- repository is the location/folder of the source/original files on your own computer;
- snapshot-id is an ID used to distinguish different repositories connected to the same storage. Each repository must have a unique snapshot ID, and snapshot IDs must be unique across machines. See the init command description for details.
- storage is where backups will be saved, i.e., the folder or bucket on the remote cloud provider;
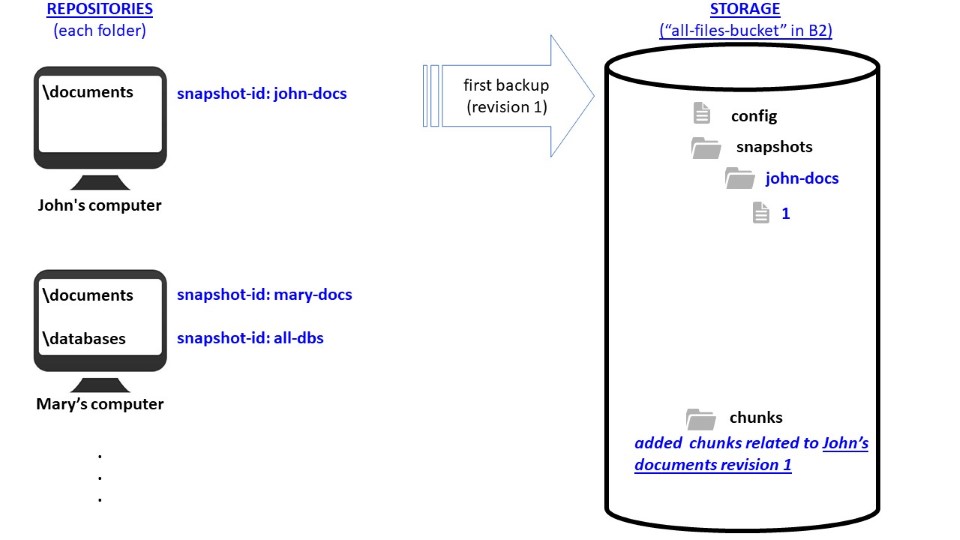
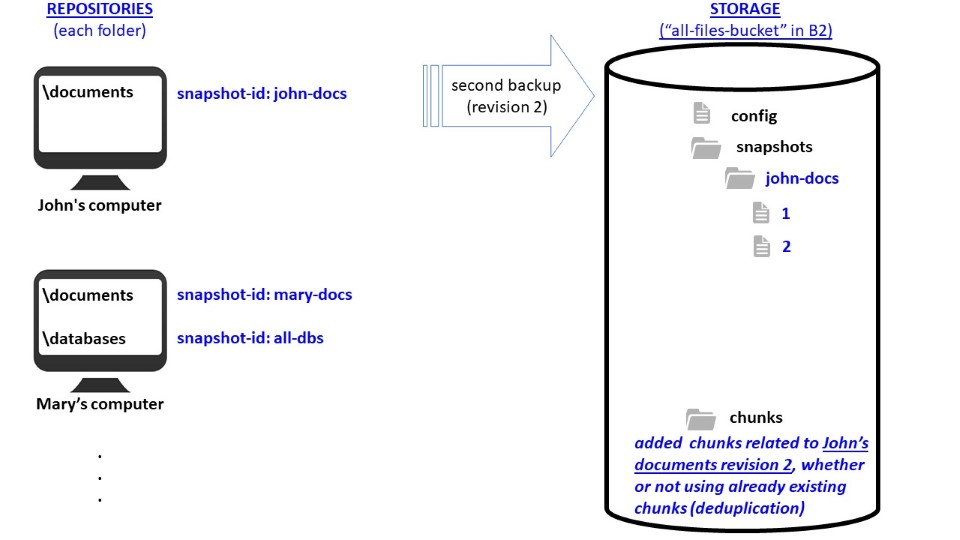
- each time a backup is performed, a revision is generated;
.
(click to enlarge the images)
John’s computer preferences file (main lines):
"name": "john-docs--b2", --> <storage name>
"id": "john-docs", --> <snapshot id>
"repository": "D:/documents",
"storage": "b2://all-files-bucket",
Mary’s computer preferences file (main lines):
"name": "mary-docs--b2", --> <storage name>
"id": "mary-docs", --> <snapshot id>
"repository": "D:/documents",
"storage": "b2://all-files-bucket",
...
"name": "all-dbs--b2", --> <storage name>
"id": "all-dbs", --> <snapshot id>
"repository": "D:/databases",
"storage": "b2://all-files-bucket",
Note that "name" (storage name) is not the name of the storage itself, but a reference to be used to execute commands (backup, check, etc.).
And "storage" (storage path) represents the real path where stores all its data.

