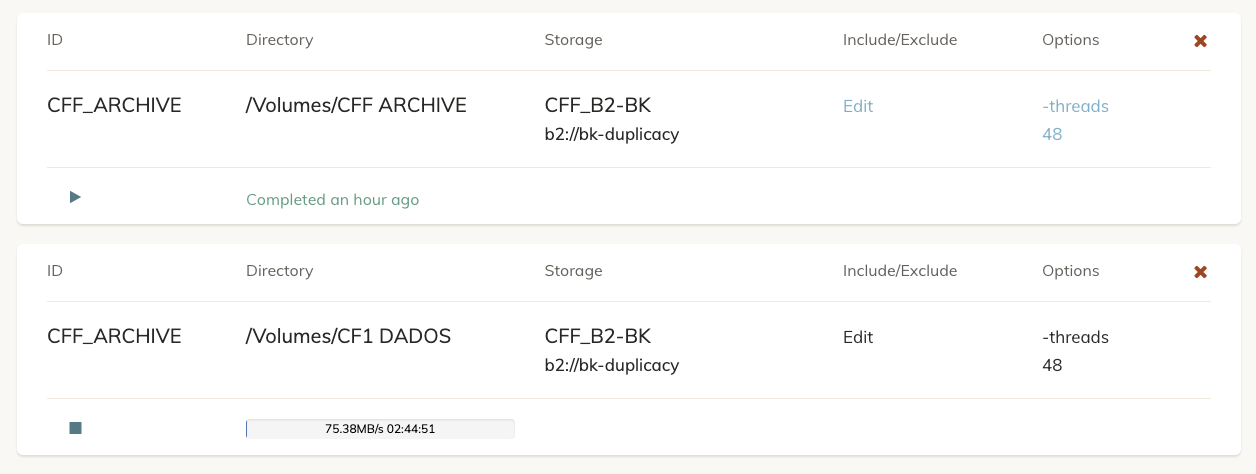
I’v noticed that Duplicacy is reading my entire HD when starting a job for B2. It’s over 4TB of data for one Volume so It takes a while. It isn’t supposed to be like that, right?
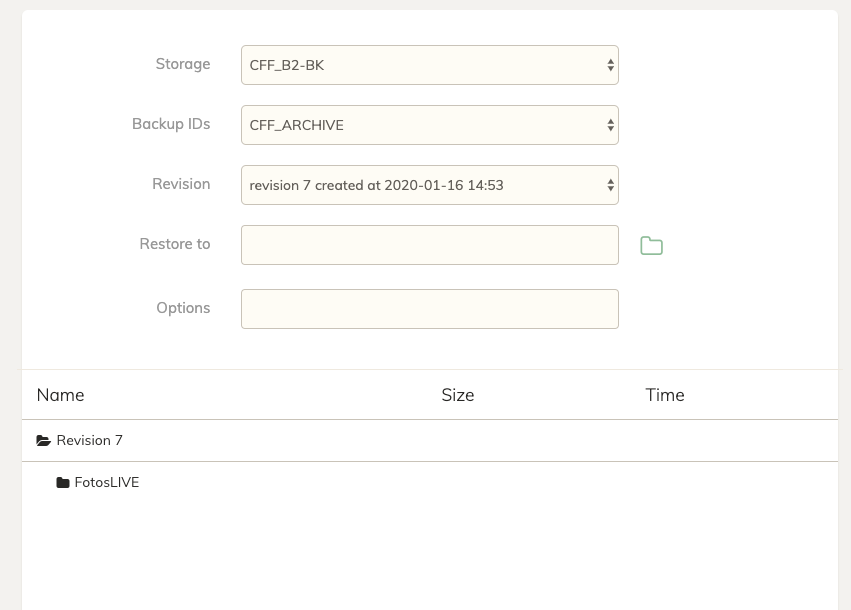
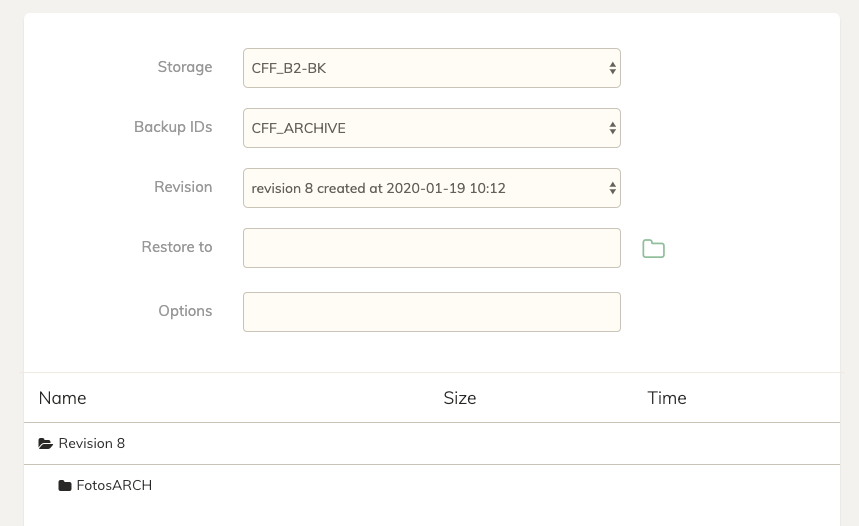
The other thing I’v noticed is that the revision ID “7” when trying to restore only shows one Volume, and the next “rev 8” shows the other… they should show both volumes in the same ID?
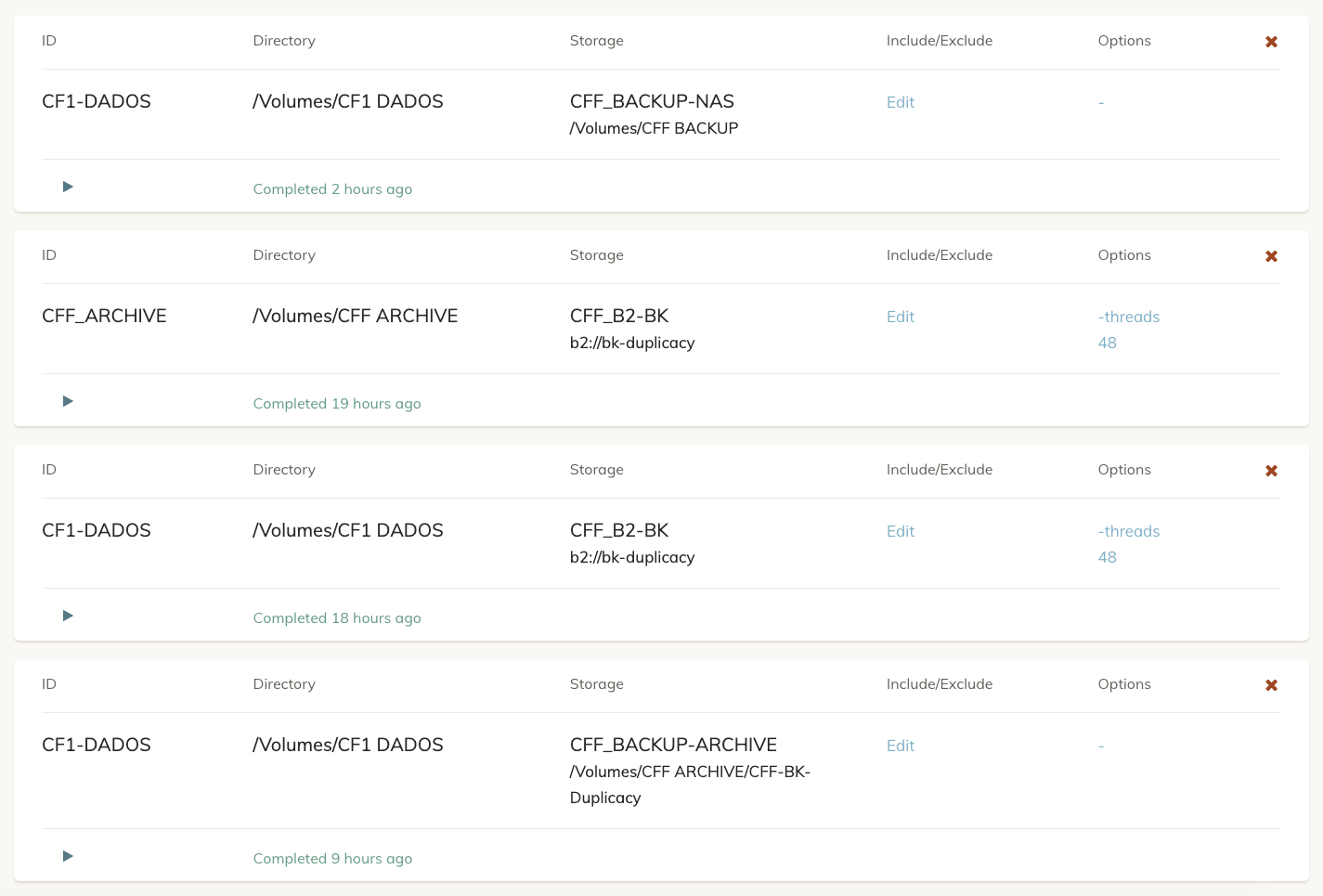
You have 2 backup jobs - backing up 2 different repositories - using the same ID. This is a bad idea, particularly because each new backup thinks it’s encountering new data - i.e. because the last backup was of an entirely different location.
You need to use unique IDs. Chunk de-duplication will still work, but you need to use different IDs so the incremental backups can properly track the changes. Fix that and it won’t scan the HDD so much.
Hmm ok. I see that I’v selected the same ID instead of creating a new one.
In fact I created another post last week about it. I have set different filters for each job, so they don’t encounter new data, but still scans everything from each HD.
In this case, when I create the new ID in the same repository, I will move the files (in about 6 months) from ID 2 (Live files) to ID (1) Archive. Will de-duplication work and not upload everything again?
And now that I’v already uploaded my “Live files” (around 800gb) to B2, is there a way to delete them from there? So I won’t be paying for that data that will never be used again in this specific ID.
Yep, most chunks will be de-duplicated regardless of what ID they’re in…
Notice however, when you’re uploading a new repository for the first time (or the file history of a particular repository ID is being nuked by another location’s file metadata for the same ID - as you’ve just experienced), it’ll take longer to finish the job because it’s re-hashing file contents locally. It’ll skip the majority of chunks and even appear as though it’s still uploading. Those numbers aren’t upload speeds, but throughput of how much data is being processed.
As for deleting your ‘Live’ files, there probably isn’t much point as most of the chunks will be referenced by the Archive, but I’d set a normal retention period for your prune operation on that repo and those old snapshots will disappear eventually. Or, you can always prune individual revisions to speed that process up, and in case you want to tidy up the moments when it was interleaving between the two repositories with the same ID.
You really don’t need to do anything special with the backup jobs when moving stuff from Live to Archive - just move your files between your repositories and Duplicacy will take care of the de-duplication for you.
Edit: Oh, and as @leerspace mentioned, it’s a good idea to test with-dry-run.
It need to be an Unique ID every time or only If I’m backing up to the same location?
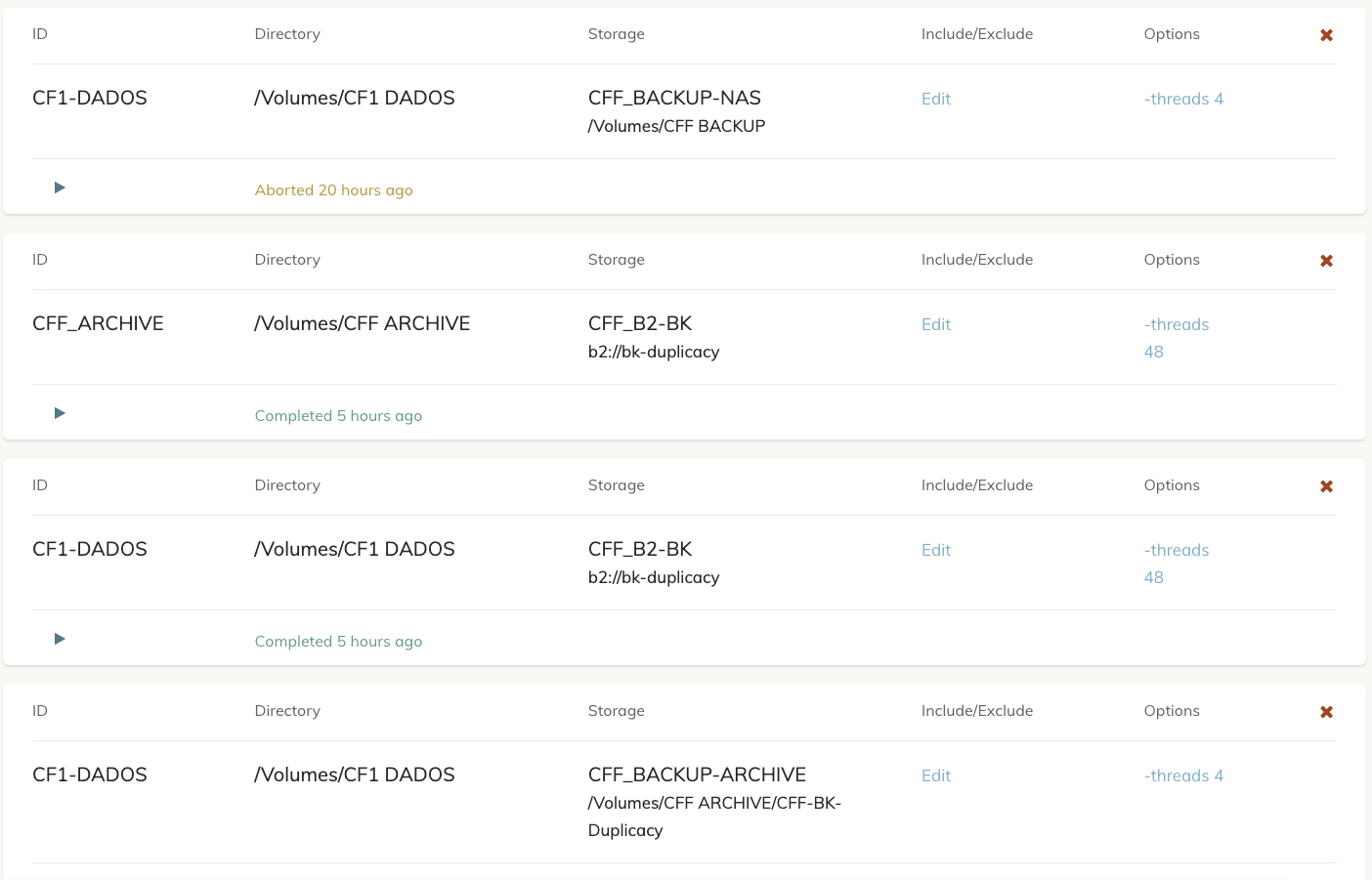
For ex, this is my current setup, sometimes when backing up, duplicacy is reading it all over again, but not always. Is it still wrong?
I notice that your fourth backup is backing up to a storage in /Volumes/CFF ARCHIVE which, in turn, is also being backed up. Have you excluded this directory or are you in fact backing up a Duplicacy storage?
Otherwise, your IDs seem OK. You have three backups with the ID CF1-DADOS, but since they point to the same repository and each go to a different storage, that should be fine.
The fourth backup is a Lacie 2Big in RAID 12TB. I have my Archive there, and an extra destination to my Live Photos (in this case backed up by duplicacy). When uploading the archive to the B2, I’m excluding the duplicacy folder.
I must be doing something wrong. It is still scanning my entire HD, but I can’t find a pattern on why. Sometimes it does, sometimes not…
How could I find this issue?
Double-check that your source repositories are actually online at backup time. If those locations are mount points, they still exist as empty directories even if your drive isn’t connected. That will erase the history for the next incremental backup. Run a check to see if any of your snapshots contain 0 files.
Could a program or filesystem quirk be touching the timestamps and make them appear modified?
My main HD with my live files is an external, I use it at home and then take back to office next morning, but the backup schedule is running every 6 hours…
Is there a way to solve this? I mean, Duplicacy should be smarter about it. Only start a revision if the storage is connected?
It will be a pain for me running it manually, and I might forget one day and lose things.
I was originally thinking you’d use a separate pre-script with a single path (for that backup) for each backup. But if you wanted to use the same pre-backup script for all 3 backups, and have it fail if any of the paths have zero files, then I think you’d need to do something like this.
#!/bin/sh
declare -a paths=(
"/Volumes/CF1 DADOS/"
"/Volumes/CFF ARCHIVE/"
"/Volumes/CFF BACKUP/"
)
for path in "${paths[@]}"; do
count=$(ls "$path" | wc -l)
if [ $count -eq 0 ]
then
exit 1
fi
done
exit 0
I was trying to do the same thing to work around the same problem, but on Windows. Posting my findings here since though it seems like the most simple thing in the world, I spent hours trying to get it to work. I scoured this forum and others (mainly stack overflow) and ended up with way too complex versions that would only work in certain cases. Here’s the post I wish I had found yesterday that would have saved me a lot of time and frustration:
Two notes for anyone else in my position (these both made things way more difficult for me than they should have):
Unlike the sh/bash example here, you have to switch the “exit 1” and “exit 0” around (man that hurt me!)
You need to use “\” - not “/” (yes I know it’s windows, but everything else that has to do with duplicacy use “/” so I started having to test with both, which doubled the number of tests.
After getting through that, I finally landed on this very simple script that seems to work with paths that contain spaces and symlinks (many otherwise-working solutions don’t)
IF EXIST "<path to directory to check. no trailing slash>" (
exit 0
) ELSE (
exit 1
)
Ya, that’s it. It’s embarrassing this took me hours to figure this out.
…and an example:
And to gather other relevant info into one place, especially for those not so technically inclined, here’s a little tutorial:
Copy the text I posted here into a text editor. Notepad works fine (Notepad++ is much friendlier though if you plan to start tinkering with this stuff)
Insert the directory path you want to check on and save the file as “pre-backup.bat”
Place that file in…
It’s a little annoying to find what number each backup is. It’s not just listed in the WebUI, to my knowledge, yet it’s helpful for lots of reasons to know it. It will be at/near the top of the log of a backup (final number in the path listed under “running backup”)
Running backup command from C:\Users\Administrator/.duplicacy-web/repositories/localhost/3
and in \.duplicacy-web\duplicacy.json listed as “index” (if you need these instructions, it means you shouldn’t touch anything in that .json file. Just read and close or make a backup before opening if you don’t trust yourself)