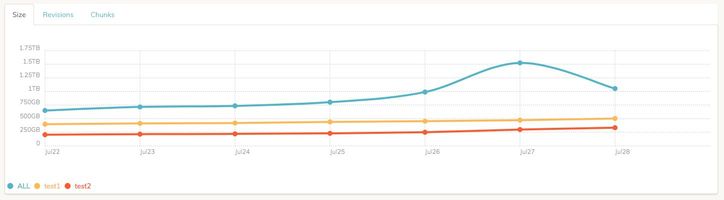
Sure, I understand this, but once the log itself gives all the information below, would not it be possible to put this on the chart? Is the chart data being fetched directly from the log?
| rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
| 1 | @ 2018-09-18 10:28 -hash | 89714 | 7,530M | 5956 | 6,983M | 3 | 664K | 5956 | 6,983M |
| 2 | @ 2018-09-18 14:23 | 93117 | 8,582M | 6674 | 7,825M | 3 | 665K | 721 | 862,504K |
| 3 | @ 2018-09-18 14:57 | 93857 | 9,348M | 7310 | 8,591M | 0 | 0 | 639 | 785,088K |
| 4 | @ 2018-09-18 15:37 | 93857 | 9,348M | 7310 | 8,591M | 0 | 0 | 0 | 0 |
| 5 | @ 2018-09-18 16:43 | 94229 | 10,759M | 8409 | 10,001M | 0 | 0 | 1102 | 1,410M |
| 6 | @ 2018-09-19 09:03 | 94229 | 10,759M | 8409 | 10,001M | 0 | 0 | 0 | 0 |
| 7 | @ 2018-09-19 10:51 | 94231 | 13,559M | 9650 | 11,560M | 2 | 625K | 1244 | 1,559M |
| 8 | @ 2018-09-19 11:02 | 104840 | 14,813M | 10239 | 12,112M | 3 | 898K | 592 | 566,758K |
| 9 | @ 2018-09-19 11:21 | 104846 | 16,540M | 11496 | 13,564M | 2 | 737K | 1260 | 1,452M |
| 10 | @ 2018-09-19 11:56 | 108036 | 17,831M | 12540 | 14,838M | 3 | 1,394K | 1047 | 1,275M |
| 11 | @ 2018-09-19 13:54 | 115911 | 26,982M | 19951 | 24,027M | 3 | 1,606K | 7414 | 9,190M |
| 12 | @ 2018-09-19 17:29 | 116582 | 27,402M | 20310 | 24,449M | 2 | 1,255K | 362 | 433,387K |
| 13 | @ 2018-09-19 17:34 | 140031 | 28,712M | 21394 | 25,742M | 0 | 0 | 1087 | 1,294M |
| 14 | @ 2018-09-19 22:47 | 140031 | 28,712M | 21394 | 25,742M | 0 | 0 | 0 | 0 |
| 15 | @ 2018-09-19 23:12 | 140146 | 29,582M | 22091 | 26,616M | 2 | 1,359K | 700 | 896,530K |
| 16 | @ 2018-10-01 12:08 | 143039 | 32,275M | 24300 | 29,302M | 0 | 0 | 2215 | 2,691M |
| 17 | @ 2018-10-01 14:46 | 143039 | 32,275M | 24300 | 29,302M | 0 | 0 | 0 | 0 |
| 18 | @ 2018-10-03 16:36 | 152471 | 36,824M | 27982 | 33,871M | 4 | 3,442K | 3686 | 4,571M |
| 19 | @ 2018-10-03 17:32 | 160262 | 38,751M | 29539 | 35,807M | 5 | 4,386K | 1561 | 1,939M |
| 20 | @ 2018-10-03 22:38 | 206665 | 47,007M | 36386 | 44,099M | 3 | 2,476K | 6852 | 8,296M |
| 21 | @ 2018-10-09 10:32 | 206666 | 47,007M | 36387 | 44,100M | 2 | 2,197K | 4 | 2,695K |
| 22 | @ 2018-10-10 08:12 | 295375 | 67,187M | 52390 | 61,750M | 2 | 3,141K | 16006 | 17,653M |
| 23 | @ 2018-10-11 12:55 | 302363 | 82,221M | 64544 | 76,831M | 2 | 730K | 12158 | 15,085M |
| 24 | @ 2018-10-11 14:07 | 314503 | 98,739M | 78029 | 93,418M | 2 | 555K | 13489 | 16,588M |
| 25 | @ 2018-10-11 15:44 | 322082 | 104,970M | 83083 | 99,675M | 0 | 0 | 5058 | 6,259M |
| 26 | @ 2018-10-12 21:05 | 322082 | 104,970M | 83083 | 99,675M | 0 | 0 | 0 | 0 |
| 27 | @ 2018-10-12 21:12 | 325951 | 108,576M | 85999 | 103,296M | 2 | 1022K | 2919 | 3,623M |
| 28 | @ 2018-10-13 21:57 | 330412 | 113,831M | 90309 | 108,574M | 0 | 0 | 4314 | 5,280M |
| 29 | @ 2018-10-14 17:43 | 330412 | 113,831M | 90309 | 108,574M | 0 | 0 | 0 | 0 |
| 30 | @ 2018-10-29 08:32 | 343981 | 118,524M | 94181 | 113,286M | 2 | 1,501K | 3875 | 4,715M |
| 31 | @ 2018-10-29 11:50 | 346884 | 119,837M | 95229 | 114,605M | 3 | 1,817K | 1051 | 1,320M |
| 32 | @ 2018-10-29 15:19 | 347782 | 120,734M | 95938 | 115,507M | 0 | 0 | 712 | 924,889K |
| 33 | @ 2018-10-29 18:57 | 347782 | 120,734M | 95938 | 115,507M | 0 | 0 | 0 | 0 |
| 34 | @ 2018-10-29 22:46 | 349256 | 122,875M | 97687 | 117,657M | 0 | 0 | 1752 | 2,152M |
| 35 | @ 2018-10-30 09:16 | 349256 | 122,875M | 97687 | 117,657M | 0 | 0 | 0 | 0 |