
That sounds much better.
You need to create a backup first. The first time you ran the schedule it didn’t have any job in it. (of course the start button should have been made disabled if there isn’t a job).
You probably clicked the delete button for deleting a job. The job needs to be selected first for the deletion button to work.
To delete a schedule, click the clock button in the upper right corner of the schedule panel
Can you elaborate on this? Which directory?
If I understood what you describe above, it’s perfectly possible to do this with prune command using -keep option:
If you never prune, then yes, the size graph can be drawn using the data directly available in the log. But once you start to prune some revisions then how the storage size changes over time can’t be simply deduced from one log file.
2 Likes
Filters are saved in files under .duplicacy-web/filters and then copied to .duplicacy-web/repositories/locahost/[1,2,...n] before running the backup command.
1 Like
Sorry, i didn’t understand.
If you don’t prune, you will have this:
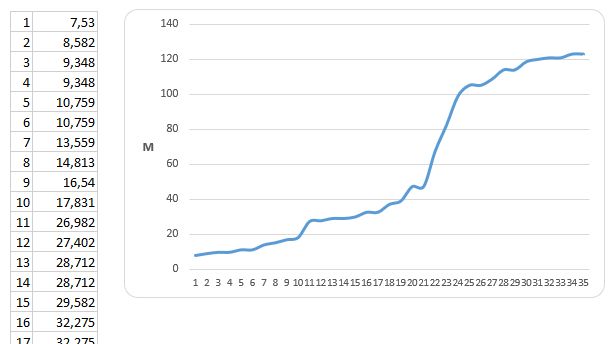
If you prune, you still have the information about the remaining revisions:
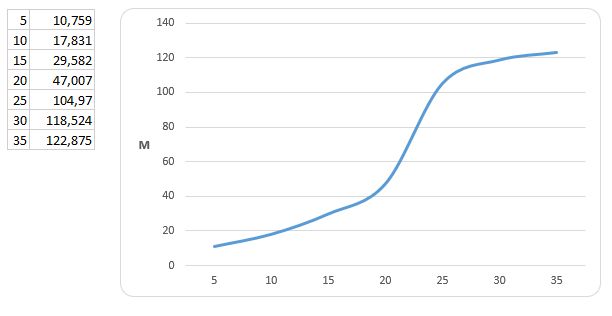
Or am I missing something?
I understand that the space used in storage is not necessarily the sum of the revisions, but would not it be interesting to see the information above?
(I used the log data from the post above)
I forgot to say: just like the CLI version, this web interface is very fast! Both to launch the executable and to load the page.
Speed is definitely a “striking feature” of Duplicacy. 
1 Like
I guess the token approach gets around the immediate problem for me. However I think there is considerable risk of bad publicity if you release software which defaults to such open access, and that access is exploited to do the wrong thing. I would suggest at minimum installing to loopback address only, but I think it would be wiser to implement traditional username/password access to the interface. And I certainly hope you have username/password access on the roadmap as the token is complex and does not provide the same level of security as username/password prompt to access the interface.
Yes, I think that makes a lot of sense. I assume this would also allow you to restore files from the storage’s from other PCs etc, which would also probably be handy. But I think my key point would be that you don’t have to create a new “Backup Repository” to do a restore, and also the workflow defaults to restores in new locations and adequate warnings before a restore overwrites existing file.
I appreciate the challenges of this with the current way you do backups. But thought putting it on your radar to put into the no doubt long list of ideas. Along possibly similar lines, it might be nice if Duplicacy could continue with a backup and record a revision, even although there might be problems accessing certain files (see my previous post about issues with VSS I did not seem to have with previous Crashplan). This means 1 open file can cause no backup to be complete, despite the fact that 99.99% of files could be backed up. I hope my VSS issue can be eliminated, as my previous backup looks could backup everything without issues. But if not, then I might be handy if Duplicacy could record a “partial backup” when this happens, to avoid the potential challenges of never being able to get a full backup. This is all related to being able to browse by file, and then reversion, because if you have this functionality, it makes it easy to find the latest file, even if it happened to be missing form a “partial” backup. Anyway, just food for thought.
What directory do I need to be in to make that work??? I run it from C:\Users\xxxxx.duplicacy-web\repositories\localhost\all but I have to put in the password each time I run a command. I can see a “keyring” file in C:\Users\xxxxx.duplicacy-web, but if I try and run from there, it does not find the repositories. What am I missing?
More feedback on the GUI beta operations with restores :-
-
There does not seem to be a way to select multiple files for restores unless I am missing something. So each file needs to be restored individually. This can be tedious and slow and impractical if there are lots of files to restore. Ideally we should be able to have a file selection dialogue box to make it simple and quick to make selections of files for restores.
-
Partially related to the above, I thought I would restore a whole directory to get around the problem above. But I then discovered the next problem. Seem there is a problem with restoring directories with symbolic links. So when I tried restoring my whole Windows “Documents” directory, I got the following error :-
2018-11-09 17:41:01.816 ERROR RESTORE_SYMLINK Can't create symlink documents/My Music: symlink C:\Users\xxxxx\Music C:/duplicacy-test-restore-temp/documents/My Music: A required privilege is not held by the client.
Of course these are some sort of Windows created Symbolic links on my machine. I am not sure why they are there, or if it is some sort of historical thing, or if I can just delete them. But if I try to access them on my machine to see what is in there or where they go, I get permission denied. If I try to see them with a cmd dir listing, they don’t appear to be there. Maybe I can delete them, but I did not create, and maybe they are needed to support some weird windows thing I don’t know about. So this might be nothing to do with Duplicacy, except for the fact that these problems make restores hard to handle, because I can’t just deselect them from the restore to work around these issues.
- There does not seem to be a way of doing a “duplicacy add -e -copy…” type command with a “–bit-identical” option. It appear possible to do a “add -copy” when you add storage by selecting a checkbox to copy from some other storage. But this copy does not seem to use the --bit-identical. It would be good to add checkbox to enable the creation of a --bit-identical copy. Without this, you have to go to the CLI.
I hope this feedback is useful. I appreciate some of it goes a bit beyond beta testing, and some of it is more “feature request” type stuff.
Ok, I just realized that what I thought was a backup schedule was in fact an empty schedule. And the schedule contains “jobs” that can be added. This took me a while to realize – so perhaps this should be made a bit more obvious – maybe display a huge button [Add Job] inside of an empty schedule to nudge the user to the right direction?
And I still disagree with the sizes of the controls - they are tiny. It’s hard to see and aim for tiny controls. A good example of bold approach to UI design that guides the user is at pirateship.com, where most frequent actions are tied to a horse-size buttons that are impossible to miss. Both visually and with the mouse; as a result the web site looks a bit ridiculous but it is extremely easy to use.
This is counter-intuitive, but I guess acceptable.
the ~/.duplicacy-web folder. Right now I cannot get anything to render except “404 page not found” at http://localhost:8080.
mymbp:Downloads me$ curl http://localhost:8080
404 page not found
This is the folder structure:
mymbp:Downloads me$ find ~/.duplicacy-web/
/Users/me/.duplicacy-web/
/Users/me/.duplicacy-web/bin
/Users/me/.duplicacy-web/bin/duplicacy_osx_x64_2.1.2
/Users/me/.duplicacy-web/repositories
/Users/me/.duplicacy-web/repositories/localhost
/Users/me/.duplicacy-web/repositories/localhost/all
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy/preferences
/Users/me/.duplicacy-web/repositories/localhost/all/.duplicacy/known_hosts
/Users/me/.duplicacy-web/logs
/Users/me/.duplicacy-web/logs/check-20181107-000001.log
/Users/me/.duplicacy-web/logs/duplicacy_web.log
/Users/me/.duplicacy-web/logs/check-20181106-230001.log
/Users/me/.duplicacy-web/logs/check-20181109-000001.log
/Users/me/.duplicacy-web/duplicacy.json
/Users/me/.duplicacy-web/stats
/Users/me/.duplicacy-web/stats/storages
/Users/me/.duplicacy-web/stats/storages/tuchka.stats
/Users/me/.duplicacy-web/stats/schedules
/Users/me/.duplicacy-web/stats/schedules/0.stats
Nothing in the log from what I can tell:
mymbp:Downloads me$ tail ~/.duplicacy-web/logs/duplicacy_web.log
2018/11/09 00:00:01 Set current working directory to /Users/me/.duplicacy-web/repositories/localhost/all
2018/11/09 00:06:15 Duplicacy CLI 2.1.2
2018/11/09 00:06:15 Temporary directory set to /Users/alex/.duplicacy-web/repositories
2018/11/09 00:06:15 Schedule 0 (12:00am, 3600, 1111111) next run time: 2018-1109 01:00
2018/11/09 00:06:15 Duplicacy Web Edition Beta 0.1.0 (FDA052) started
2018/11/09 00:06:25 [::1]:58632 GET /
2018/11/09 00:06:25 [::1]:58634 GET /assets/js/paper-dashboard.js
2018/11/09 00:06:25 [::1]:58633 GET /assets/css/paper-dashboard.css
2018/11/09 00:06:25 [::1]:58635 GET /
2018/11/09 00:06:38 [::1]:58638 GET /
mymbp:Downloads me$
Let me know if I can provide better diagnostic. macOS is current Mojave.
Thanks very much for the new web-based gui. I’ve been trying it out on two computers, mostly very successfully, and it is a much nicer experience than the previous gui. I just want to report a few issues, one seems significant, the others are minor. All testing has been on Win10 in Firefox.
First the significant bug. I have a directory, D:/user, that has 5 subdirectories (a/, b/, c/, d/, and e/) that I want to back up on different schedules. So I set up three backup jobs:
- D:/user/ with filters -c/ -d/ -e/
- D:/user/c/ with filter -*.lrdata/
- D:/user/ with filters -a/ -b/ -c/
When I ran backup 2, it used the filters specified for backup 0, not 2, and when I ran backup 1 it seemed to ignore the filter. When I looked into the files in ~/.duplicacy-web/, I see that filters/localhost/0, filters/localhost/1, and filters/localhost/2 are different and correct. However, the files repositories/localhost/*/.duplicacy/filters are all the same, with the entries for backup 0. The result seems to be that the gui shows the different set of filters, but the cli is called with the wrong filters for backups 1 and 2. Obviously I can fix it locally, but it seems like something to try to fix. On the other PC, I used the same filters for backups 0 and 1, and no filters for a third backup, and there were no problems.
Setting the starting time for a schedule is a little quirky. I couldn’t use the arrows, and had to type in a time in the exact format used. For example, 4:00pm (no leading zero) didn’t work, 16:00 and 04:00 pm also fail. Maybe some off the shelf jscript time chooser would help. Also, once I realized that setting the starting time sets the first time each day that the job will run, I thought it could also be useful to have an ending time so that you could run a backup regularly only during work hours, for example.
My cloud backups go to a single B2 bucket to allow deduplication, and that means I have 5 backups, plus “all”, displayed on the storage graph for that B2 bucket. It seems like there is no color specification working for the 6th line on the graph. The sixth line is the same color as the first (All), and the sixth dot and label in the legend below the plot are black. The color spec for the sixth legend dot in the html is color:Zgotmp1Z, and for the text in the legend is rgba(104, 179, 200, 0.8). In the plot, the sixth line and dot have the same rgba color spec, which has the same rgb values as the first dot and line, which are specified as #68b3c8.
Finally, on the longer term, I want to support the previous request to be able to restore by finding the file to be restored and then choosing the version to restore.
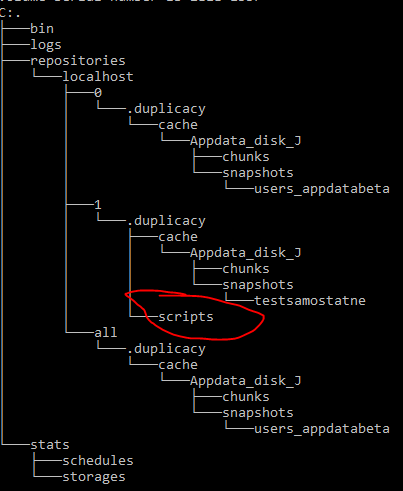
I have question about pre/post backup scripts.
They work, but I find current location non-intuitive.
I have to put post-backup in folder C:\Users\username.duplicacy-web\repositories\localhost\1.duplicacy\scripts
But can I see backup number (0,1) in GUI somewhere? After some time with many backups, it can be quite confusing.
Hi everyone,
The new web GUI is amazing. thank you @gchen
I just have some suggestions:
1-restores:
1.1-A new restore flow might be good.
Just browsing a repository at last revision and click on a file or folder.
Click on show revisions->
then on a secondary filed would show the available revisions.
to keep it fast we only query when we press show revisions.
1.2-Designate a special directory for quick restores. behind the scenes, we would initiate the repository with the correct repository id download the file and clear the repository until next use.
1.3-allow restores selecting multiple files and directories.
2-Security:
2.1 Regarding authentication: A full-fledged user system is a step in the right direction if we want to move towards multiple endpoints controlled by the web interface but I understand that it would add complexity and is too much for now.
Maybe just have a user-defined timeout and ask for the master password on timeout.
2.2- I would also ask for the for and master password via the CLI. That way at no point would the user be at risk.
3-Question: how to backup of the web gui local data?:
what happens after rm -rf ~/.duplicacy-web/?
What do we need to get things working again?
Ideally, we would backup essential files to the storage itself.
Then on a clean install, we would get asked to restore after entering the storage password and the correct endpoint.
4-Small ui fixes:
4.1. I agree that destructive actions should be visually separated from normal actions.
4.2 A visual cue for drop-downs.(a simple coloured border would work)
4.3 possible bug: If you select and deselect the “parallel” checkbox it can be duplicated (goes away after a refresh).
4.4 Edit job options on the backup pane or concentrate them on the schedules section. (that would be my choice due to flexibility.)
5-Feature requests:
5.1: API endpoints via the web GUI.
That way we could control backup restore and monitoring of endpoints and we open up a lot of functionality. Like instant backup and sync.
5.2: Once we hit stable: a quick video tutorial and links to online help on each section.
That’s it for now, in the end, the web gui is everything I hoped it would be and the potential unbelievable.
Thanks again!
2 Likes
Update:
4 small UI fixes
4.5 make the “selected item” shade a bit darker or a light green so it’s more apparent.
5-Feature requests
5.3 instead of status, show last successful run timestamp in green (or error in red) for each job.
(this is bc in a desktop the scheduler will not be always running)
5.4 If a job in a schedule is selected run just the selected job. (or display a “per job” run icon)
1 Like
Feedback on the Dashboard:
- Enhancement: Make the icons at the top of the dashboard into “drilldown” links to their respective details page.
- Issue: The “Activities” timeline exceeds it’s box depending on browser window size:
- Question on proposed licensing: Will the GUI be free for those entitled to use the CLI for free, or will it require a subscription?

Again - fantastic work. I believe this is the one missing piece that will make Duplicacy a de facto standard for folks I know (running a NAS, which is my use case). This could easily be made into a package for QNAP and Synology NAS app stores. A third-party app store has already bundled Duplicacy CLI for that purpose. However, I’m a big fan of docker for running web GUI interfaces so I don’t need to rely on the buggy or vulnerable Apache web server & PHP version that ships with the NAS.
1 Like
If you are interested, one way around the default port is to use docker:
1 Like
I few more bits of feedback for consideration after more uses :-
-
The naming of log files with on a prefix of “copy” or “backup” etc and then only the date and time can be a bit difficult to find the log file you want on a box with lots of different backup jobs. I think as a previous poster has suggested, it might be good to be able to name backup jobs, or at least “schedules” and use these names on the backup files to be able to quickly job to the log file you want if you are searching for log files.
-
As further reason to change the implementation of the ways you do restores is highlighted by a minor annoyance I have with something I have setup. I have a backup job to an onsite server. Then I run a copy job to the offsite server. Because I don’t have a “backup” job from the local server to the offsite server, there is no way for me to do a restore in the GUI, and you then need to go to the CLI. So based on that, and further to other comments above, I think it would much more sensible completely decouple backups and restores. From other backup software, the most standard way to do this would be to have a completely separate “Restores” top level option. If it was me, I would then allow people to browse all the configured “Storage’s” (I would also allow an additional storage to be configured at this point or at least point back to doing that at the “Storages” top level if required), and then browse all the backup IDs on that particular storage, irrespective if it has come from that machine or not, and then browse into the revisions etc. Of course you could implement the same thing from the “Storages” top level menu, which would offer the same functionality. But for me it seems counter intuitive to have to go to “Storages” to do a restore, and I suspect that Backup software needs to have “Restores” as a primary item Restores is a primary function of backup software, and backup is completely useless without restores. As a case it point, when I 1st started playing with the GUI, I though you had not yet implemented restores in the GUI yet, because I did not think to look for it under “Backups” and missed the significance in the tiny icon in backups that takes you to the restores option.
-
And of course, bonus marks for restores if it is possible to implement file revisions at the file level once you have drilled into the file, rather than having to search every revision from the top down. Interim step might be to allow file history from the GUI to be able to see the dates the file changed
-
I could believe it might be something for a future version, but for GUI users who have used backup software that allows you to choose what you want to backup and exclude from a directory tree you can drill into which has tick boxes next to the things you want to backup and/or exclude, it is hard to go back to methods similar to current implementation used in Duplicacy. I guess this is further complicated in Duplicacy’s CLI and “Repository” based approach. But ideally for simple non technical GUI users, I think it would be simpler if they couple create jobs based on frequency and destination and place all the directories in that backup strategy in the 1 job.
Anyway, the work so far looks fantastic, so keep up the good work. And I appreciate there are lots of reasons you have done things the way you have that I have not even thought of. But hopefully these end user insights are useful.
Just tried it out, first time, on a Mac. Had to “chmod +x” the executable, but then it ran without a hitch. Might be better to distribute it as a zip, which might preserve the x bit, too.
It would be nice if you’d (optionally) use the native file browser. The one that’s now used is not user friendly compared to what macOS offers.
1 Like
Hi,
I have just started using Duplicacy and am using the Web Edition on Linux.
Some feedback I have:
- When I click on “Status” of a job (when a copy/backup etc) is in progress, then log file does not show up in new window, with “Failed to open the log file /root/.duplicacy-web/logs/null”.
- Check jobs shouldn’t need to be something that needs to be setup, but just happens at certain intervals in the background.
Features that would be great:
- It would be good to see some kind of throughput status/time-remaining on a copy job.
- It would be nice be able to set Schedule names, so you can see what each schedule represents in the dashboard view.
- More granular timings on the graph view on the dashboard/storages and be able to change the timeframe. For example, be able to see hourly increments in the graph for example and also change the period you are viewing.
- Tooltips when you hover over the icons (showing what they do) and also the dashboard/storages graphs (show #Gb/Chunks/Revisions)
That’s all my feedback/suggestions for now :>
Thank you very much for working on the Web based GUI.
It great good so far!
Regards
pdaemon