To answer your question, it’s important to realise you can only combine these two -keep n:m retention parameters together in decreasing order. i.e. when you sort them in decreasing order of m (as you must), then n should decrease as well (with the exception of 0:m), otherwise there’s no point as you correctly surmised, you can’t do it the other way around. (Can’t remember if Duplicacy stops you from doing that, but it certainly wants m in the correct order.)
An n of 0 is a special case, in that anything and everything older than m gets removed. So you can choose to have that, or not.
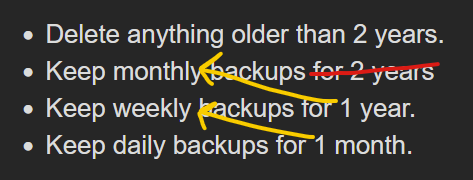
In terms of backups in general… weekly, monthly, yearly is just a traditional way to rotate backups - specifically, the Grandfather-father-son system. Duplicacy doesn’t understand these periods so precisely - it’s just numbers of days as far as it sees - and are simply emulated by 7, 30 etc., but won’t quite match a reliable pattern. (Like some backups systems can retain the first backup of the month; Duplicacy isn’t that fussed, nor can it made to be in the current implementation. Besides, we normally no longer physically rotate them.)
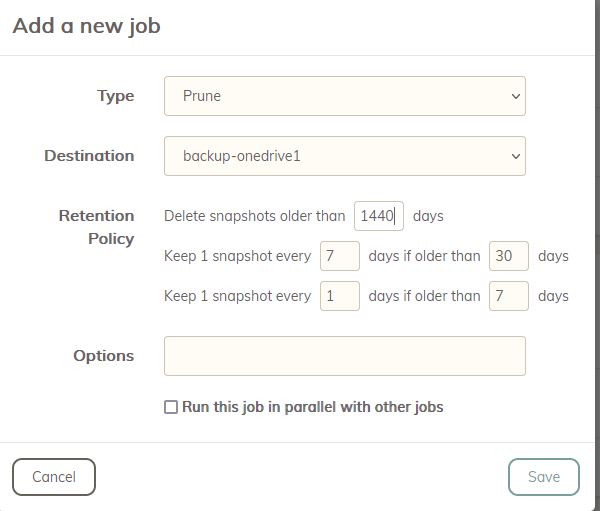
Let’s take a simple example of -keep 0:2555 -keep 365:30 -keep 1:14. We backup every hour (so 24 snapshots in a day).
Notice the lack of a ‘weekly’ option (just to get you to think why you might want multiple options regardless of the difference between the numbers 7 and 30).
In a sense, the first (n=0) and last (n=1) are kinda special cases. The first declares an ultimate expiry. The last - because we can only specify days and not fractions of a day - reduces the number of snapshot we keep each day, after a couple of weeks go by.
Of course you don’t have to do it that way, but after a couple weeks (say) you very likely won’t need to recover a specific hour (say). If anything went wrong in that day or perhaps you notice the day after, you have a fresh memory and have hourly snapshots to recover from. But as time goes on, generally we’re less interested in recovering from a specific time in the day (or week etc.), so we wanna keep less copies (to save on disk space) but to delineate age into human understandable periods, if that’s how we want it.
Really, it’s all just arbitrary and you strictly don’t have to abide by these numbers at all (although maybe you might have a weekly ritual of doing your finances every Sunday of every week, so keeping a weekly version… for a while… helps, until it becomes unimportant. And then you can switch from weekly to monthly. 
If 7 years is overkill (for many, removing the 0:m entirely is perfectly fine, too), you could change the ‘monthlies’ to anything over 3 years, and then maybe add a ‘quarterlies’ 'til 10 years. i.e. -keep 0:3650 -keep 1095:90 -keep 90:7 -keep 1:1 - the last couple I threw in to further illustrate, in which ‘monthlies’ doesn’t even feature - I just wanna keep a backup copy once a week beyond 90 days, and 1:1 ensures I’m only keeping 1 a day if I happen to be running hourly or whatever. At time goes on, the gap widens.
I actually do this for one of our clients (1:1), where I’m running Vertical Backup (Duplicacy for VMs) at 6am, 6pm, and midnight, and I really just wanna run it as often as possible, while minimising disk space, resource usage during the day. So even if you just wanted daily snapshots, it really is a good idea to run much more frequently anyway, since your last backup may be as much as 24 hours old. -keep 1:1 then becomes a useful last case.
To answer your question…
You can totally have that Local (0:30) and Cloud (0:90) retention and they’d be compatible with each other - so long as you either backup individually to each storage, OR backup to local and then copy local-to-cloud (as most would). Copying Cloud to Local wouldn’t make much sense, however.
HTH
</long post, soz>
Edit: Clarified the ordering of n and m and some typos.